Spark UI是反映一个Spark作业执行情况的web页面, 用户可以通过Spark UI观察Spark作业的执行状态, 分析可能存在的问题。
1.Jobs
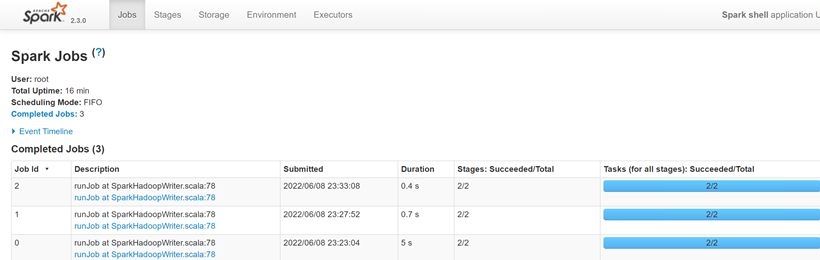
在提交spark任务运行后,日志中会输出tracking URL即任务的日志链接。在浏览器中打开tracking URL后,默认进入Jobs页。Jobs展示的是整个spark应用任务的job整体信息。
2.Stages
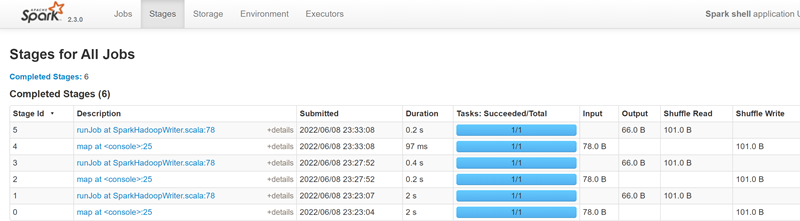
在Job Detail页点击进入某个stage后,可以查看某一stage的详细信息:
- Total time across all tasks: 当前stage中所有task花费的时间和。
- Locality Level Summary: 不同本地化级别下的任务数,本地化级别是指数据与计算间的关系(PROCESS_LOCAL进程本地化:task与计算的数据在同一个Executor中。NODE_LOCAL节点本地化:情况一:task要计算的数据是在同一个Worker的不同Executor进程中;情况二:task要计算的数据是在同一个Worker的磁盘上,或在 HDFS 上,恰好有 block 在同一个节点上。RACK_LOCAL机架本地化,数据在同一机架的不同节点上:情况一:task计算的数据在Worker2的Executor中;情况二:task计算的数据在Worker2的磁盘上。ANY跨机架,数据在非同一机架的网络上,速度最慢)。
- Input Size/Records: 输入的数据字节数大小/记录条数。
- Shuffle Write: 为下一个依赖的stage提供输入数据,shuffle过程中通过网络传输的数据字节数/记录条数。应该尽量减少shuffle的数据量及其操作次数,这是spark任务优化的一条基本原则。
- DAG Visualization: 当前stage中包含的详细的tranformation操作流程图。
- Metrics: 当前stage中所有task的一些指标(每一指标项鼠标移动上去后会有对应解释信息)统计信息。
- Event Timeline: 清楚地展示在每个Executor上各个task的各个阶段的时间统计信息,可以清楚地看到task任务时间是否有明显倾斜,以及倾斜的时间主要是属于哪个阶段,从而有针对性的进行优化。
- Aggregated Metrics by Executor: 将task运行的指标信息按excutor做聚合后的统计信息,并可查看某个Excutor上任务运行的日志信息。
- Tasks: 当前stage中所有任务运行的明细信息,是与Event Timeline中的信息对应的文字展示(可以点击某个task查看具体的任务日志)。
3.Storage Storage页面能看出application当前使用的缓存情况,可以看到有哪些RDD被缓存了,以及占用的内存资源。如果job在执行时持久化(persist)/缓存(cache)了一个RDD,那么RDD的信息可以在这个选项卡中查看。
4.Enviroment Environment选项卡提供有关Spark应用程序(或SparkContext)中使用的各种属性和环境变量的信息。用户可以通过这个选项卡得到非常有用的各种Spark属性信息,而不用去翻找属性配置文件。
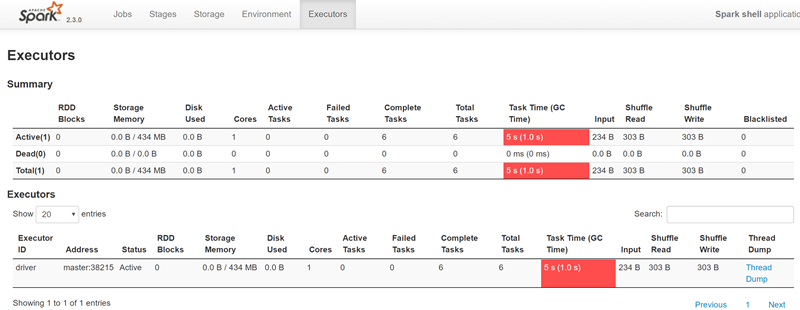
5.Executor
Executors选项卡提供了关于内存、CPU核和其他被Executors使用的资源的信息。这些信息在Executor级别和汇总级别都可以获取到。一方面通过它可以看出来每个excutor是否发生了数据倾斜,另一方面可以具体分析目前的应用是否产生了大量的shuffle,是否可以通过数据的本地性或者减小数据的传输来减少shuffle的数据量。
Summary: 该application运行过程中使用Executor的统计信息。 Executors: 每个Excutor的详细信息(包含driver),可以点击查看某个Executor中任务运行的详细日志。