spark支持四种运行模式:local、Standalone、Mesos和yarn。
1.spark的四种运行模式
- local模式——本地测试用,用来学习时运行一些测试案例。
- Standalone——spark自带的集群模式,需要构建一个由Master+Slave构成的Spark集群,Spark运行在集群中
- Mesos——国内用的很少
- yarn集群模式——Spark客户端直接连接Yarn,不需要额外构建Spark集群。国内生产上用的多。
2.local模式官方PI案例
Spark Local模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,直接运行在本地,便于调试,通常用来验证开发出来的应用程序逻辑上有没有问题,其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core),如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.即运行的线程数与CPU的核数一样。通常,Local模式用于完成开发出来的分布式程序的测试工作,并不用于实际生产。
测试spark环境是否安装正确:
[root@master]# cd /usr/local/spark/bin
[root@master bin]# spark-shell
出现以下启动界面,说明spark启动成功,scala的版本号为:2.11.8
打开浏览器,地址栏输入:http://192.168.3.77:4040, 其中192.168.3.77是虚拟机的内网静态IP地址。
输入:quit命令退出。
scala> :quit
[root@master bin]#
测试官网的求PI的案例
在/usr/local/spark目录下执行以下命令:
[root@master spark]# bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ./examples/jars/spark-examples_2.11-2.3.0.jar 10
其中: 1). --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序。 2). --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟CPU 核数量。 3). spark-examples_2.11-2.3.0.jar 运行的应用类所在的jar包。 4). 数字 10 表示程序的入口参数,用于设定当前应用的任务数量。
运行结果:

3.spark-shell运行wordcount案例
1).创建wordcount.txt测试数据。
java html java c python javascript python c++ html sql javascript java python
2).hadoop HDFS集群启动 参考:HDFS集群启动
3).把wordcount.txt上传至/hello
[root@master bin]# hadoop fs -put wordcount.txt /hello/
[root@master bin]# hadoop fs -ls /hello/
Found 4 items
-rw-r--r-- 3 root supergroup 11 2022-05-31 09:43 /hello/helloworld.txt
drwxr-xr-x - root supergroup 0 2022-06-01 21:14 /hello/input
drwxr-xr-x - root supergroup 0 2022-06-01 22:43 /hello/output
-rw-r--r-- 3 root supergroup 78 2022-06-07 22:58 /hello/wordcount.txt
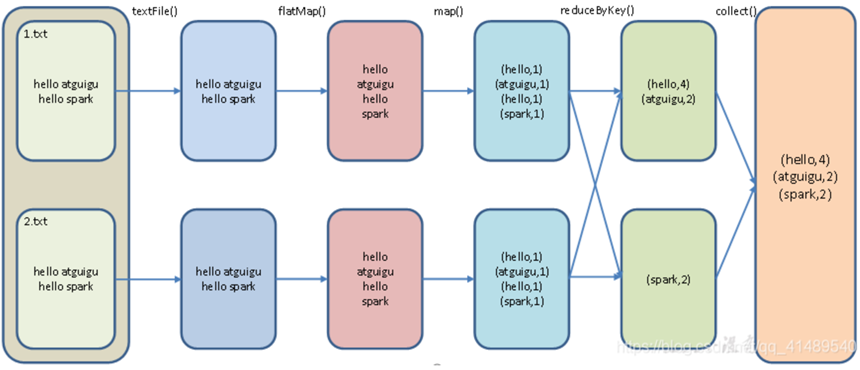 4).spark内部执行
4).spark内部执行
scala> sc.textFile("/hello/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res2: Array[(String, Int)] = Array((c++,1), (python,3), (java,3), (javascript,2), (html,2), (sql,1), (c,1))
执行过程如下: 1. textFile("/hello/wordcount.txt"):读取本地文件/hello/wordcount.txt里的数据; 2. flatMap(.split(" ")):压平操作,按照空格分割符将一行数据映射成一个个单词; 3. map((,1)):对每一个元素操作,将单词映射为元组; 4. reduceByKey(+):按照key将值进行聚合,相加; 5. collect:将数据收集到Driver端展示.前面的所有的操作是懒加载,不会立即执行,调用collect之后就开始执行了.
5).把运算结果输出到文件。
scala> sc.textFile("/hello/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/hello/output")
查看输出文件。
[root@master ~]# hadoop fs -ls /hello/output/
Found 2 items
-rw-r--r-- 3 root supergroup 0 2022-06-08 23:33 /hello/output/_SUCCESS
-rw-r--r-- 3 root supergroup 66 2022-06-08 23:33 /hello/output/part-00000
[root@master ~]# hadoop fs -cat /hello/output/part-00000
(c++,1)
(python,3)
(java,3)
(javascript,2)
(html,2)
(sql,1)
(c,1)