Spark是一种基于内存的快速、通用、可扩展的大数据分析引擎。
![]()
1.Spark发展历程
- 2009年,Spark诞生于伯克利大学AMPLab,属于伯克利大学的研究性项目;
- 2010 年,通过BSD 许可协议正式对外开源发布;
- 2012年,Spark第一篇论文发布,第一个正式版(Spark 0.6.0)发布;
- 2013年,成为了Aparch基金项目;发布Spark Streaming、Spark Mllib(机器学习)、Shark(Spark on Hadoop);
- 2014 年,Spark 成为 Apache 的顶级项目; 5 月底 Spark1.0.0 发布;发布 Spark Graphx(图计算)、Spark SQL代替Shark;
- 2015年,推出DataFrame(大数据分析);2015年至今,Spark在国内IT行业变得愈发火爆,大量的公司开始重点部署或者使用Spark来替代MapReduce、Hive、Storm等传统的大数据计算框架;
- 2016年,推出dataset(更强的数据分析手段);
- 2017年,structured streaming 发布;
- 2018年,Spark2.4.0发布,成为全球最大的开源项目。
2.Spark特点
Spark具有以下几个显著的特点:
1).速度快 小生根据官方数据统计,与Hadoop相比,Spark基于内存的运算效率要快100倍以上,基于硬盘的运算效率也要快10倍以上。Spark实现了高效的DAG执行引擎,能够通过内存计算高效地处理数据流。
2).易用性 Spark编程支持Java、Python、Scala及R语言,并且还拥有超过80种高级算法,除此之外,Spark还支持交互式的Shell操作,开发人员可以方便地在Shell客户端中使用Spark集群解决问题。
3).通用性 Spark提供了统一的解决方案,适用于批处理、交互式查询(SparkSQL)、实时流处理(SparkStreaming)、机器学习(SparkMLlib)和图计算(GraphX),它们可以在同一个应用程序中无缝地结合使用,大大减少大数据开发和维护的人力成本和部署平台的物力成本。
4).兼容性 Spark开发容pSpark可以运行在Hadoop模式、Mesos模式、Standalone独立模式或Cloud中,并且还可以访问各种数据源,包括本地文件系统、HDFS、Cassandra、HBase和Hive等。
3.Spark vs Hadoop
1).综合能力 Spark是一个综合性质的计算引擎。 Hadoop既包含MapReduce(计算引擎),还包含HDFS(分布式存储)和Yarn(资源管理)
所以说他们两个的定位是不一样的。从综合能力上来说,hadoop是完胜spark。
2).计算模型 Spark 任务可以包含多个计算操作,轻松实现复杂迭代计算。而Hadoop中的MapReduce任务只包含Map和Reduce阶段,不够灵活,从计算模型上来说,spark是完胜hadoop。
3).处理速度 Spark 任务的数据是基于内存的,计算速度很快。而Hadoop中MapReduce 任务是基于磁盘的,速度较慢。 从处理速度上来说,spark也是完胜hadoop。
之前有一种说法,说Spark将会替代Hadoop,这个说法是错误的,其实它们两个的定位是不一样的,Spark是一个通用的计算引擎,而Hadoop是一个包含HDFS、MapRedcue和YARN的框架,所以说Spark就算替代也只是替代Hadoop中的MapReduce,也不会整个替代Hadoop,因为Spark还需要依赖于Hadoop中的HDFS和YARN。 所以在实际工作中Hadoop会作为一个提供分布式存储和分布式资源管理的角色存在,Spark会在它之上去执行。
所以在工作中就会把spark和hadoop结合到一块来使用。
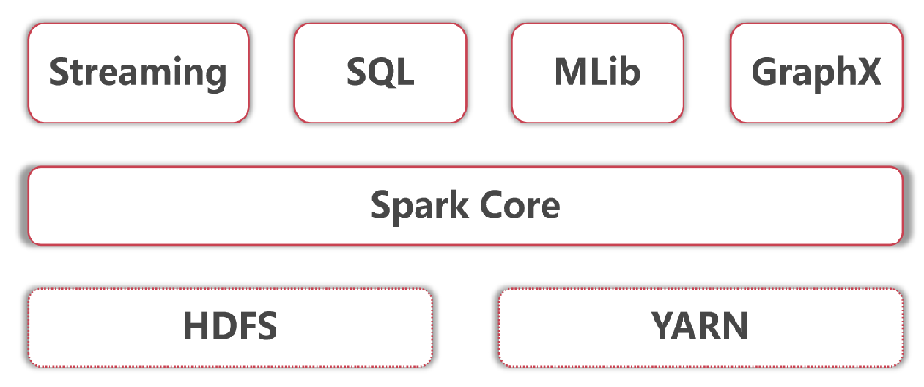
- 底层是Hadoop的HDFS和YARN
- Spark core指的是Spark的离线批处理
- Spark Streaming指的是Spark的实时流计算
- SparkSQL指的是Spark中的SQL计算
- Spark Mlib指的是Spark中的机器学习库,这里面集成了很多机器学习算法
- 最后这个Spark GraphX是指图计算
这里面这么多模块,针对大数据开发岗位主要需要掌握的是Spark core、streaming、sql这几个模块,其中Mlib主要是搞算法的岗位使用的,GraphX这个要看是否有图计算相关的需求,所以这两个不是必须要掌握的。
所以在本套体系课程中我们会学习Spark core、Spark SQL、还有Spark streaming这三块内容,不过由于现在我们主要是学习离线批处理相关的内容,所以会先学习Spark core和Spark SQL,而Spark streaming等到后面我们讲到实时计算的时候再去学习。