Hadoop基础教程(八)
MapReduce编程
MapReduce 主要是依靠开发者通过编程来实现功能的,开发者可以通过实现 Map 和 Reduce 相关的方法来进行数据处理。
1.MapReduce编程
把上小节的案例使用编程手段实现。
项目结构图如下:
1.pom.xml添加依赖,指定打包方式和文件名。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>mapreduce-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<name>Archetype - mapreduce-demo</name>
<url>http://maven.apache.org</url>
<dependencies>
<!-- hadoop的依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
<scope>provided</scope>
</dependency>
<!-- log4j的依赖 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.10</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.10</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<finalName>wordcount</finalName>
<plugins>
<!-- compiler插件, 设定JDK版本 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
<showWarnings>true</showWarnings>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
2.编写WordCountJob.java
package com.simoniu.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountJob {
/**
* 创建自定义的reducer类
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
/**
* 针对v2s的数据进行累加求和 并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context)
throws IOException, InterruptedException {
// 创建一个sum变量,保存v2s的和
long sum = 0L;
for (LongWritable v2 : v2s) {
sum += v2.get();
}
// 组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
// 把结果写出去
context.write(k3,v3);
}
}
/**
* 创建自定义mapper类
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
/**
* 需要实现map函数
* 这个map函数就是可以接收k1,v1, 产生k2,v2
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
// k1代表的是每一行的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
// 迭代切割出来的单词数据
for (String word:words) {
// 把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
// 把<k2,v2>写出去
context.write(k2,v2);
}
}
}
/**
* 组装job=map+reduce
*
* @param args
*/
public static void main(String[] args) {
try {
if (args.length != 2) {
// 如果传递的参数不够,程序直接退出
System.exit(100);
}
// job需要的配置参数
Configuration conf = new Configuration();
// 创建一个job
Job job = Job.getInstance(conf);
// 注意:这一行必须设置,否则在集群中执行的是找不到WordCountJob这个类
job.setJarByClass(WordCountJob.class);
// 指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 指定map相关的代码
job.setMapperClass(MyMapper.class);
// 指定k2的类型
job.setMapOutputKeyClass(Text.class);
// 指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
// 指定reduce相关的代码
job.setReducerClass(MyReducer.class);
// 指定k3的类型
job.setOutputKeyClass(Text.class);
// 指定v3的类型
job.setOutputValueClass(LongWritable.class);
// 提交job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.maven打包
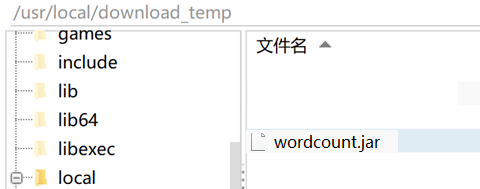
创建一个/usr/local/download_temp目录用来测试。
把上面的maven项目打包,把target目录下的wordcount.jar,复制到/usr/local/download_temp目录下。
4.执行mapreduce任务
#最好先删除上小节生成的/hello/output目录
#hadoop fs -rm -r /hello/output
[root@master download_temp]# hadoop jar wordcount.jar com.simoniu.mapreduce.WordCountJob /hello/input /hello/output
5.查看/hello/output
[root@master download_temp]# hadoop fs -ls /hello/output/
Found 2 items
-rw-r--r-- 3 root supergroup 0 2022-06-01 22:43 /hello/output/_SUCCESS
-rw-r--r-- 3 root supergroup 43 2022-06-01 22:43 /hello/output/part-00000
6.查看执行结果
[root@master download_temp]# hadoop fs -cat /hello/output/part-00000
I 4
flink 1
hadoop 2
like 2
love 2
spark 1