Spark基础教程(四)
CentOS7安装Spark
1.安装Scala
上传本地的 spark 安装包到虚机上的/usr/local目录下,然后解压缩到当前目录,更名为scala。
打开 /etc/profile 添加如下内容配置spark环境:
#1.打开配置环境变量的文件
vim /etc/profile
#2.配置环境变量
export SCALA_HOME=/usr/local/scala
export PATH=${SCALA_HOME}/bin:$PATH
#3.立刻生效
source /etc/profile
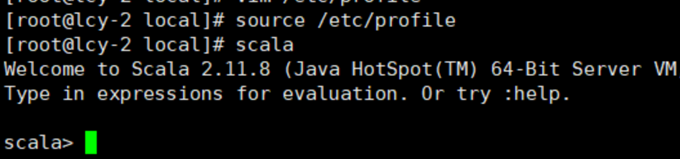
这里环境变量生效后,可以测试一下scala:
2.安装spark
上传本地的spark安装包到虚机上的/usr/local目录下,然后解压缩到当前目录,更名为spark。
#1.打开配置环境变量的文件
vim /etc/profile
#2.配置环境变量
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
#3.立刻生效
source /etc/profile
在spark的安装路径下的环境变量(/usr/local/spark/conf)与Hadoop进行库文件的关联。
#1.重命名
cd /usr/local/spark/conf
mv spark-env.sh.template spark-env.sh
#2.打开文件spark-env.sh(在最后添加声明,对应的路径为Hadoop安装路径bin/hadoop)
#/usr/local/hadoop 为hadoop的安装路径
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-2.9.2/bin/hadoop classpath)
#spark-3.2.4配置
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_271
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop3.1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_HOST=hadoop-master
export SPARK_LOCAL_DIRS=/usr/local/spark
export SPARK_DRIVER_MEMORY=4g #内存
export SPARK_WORKER_CORES=2 #cpus核心数
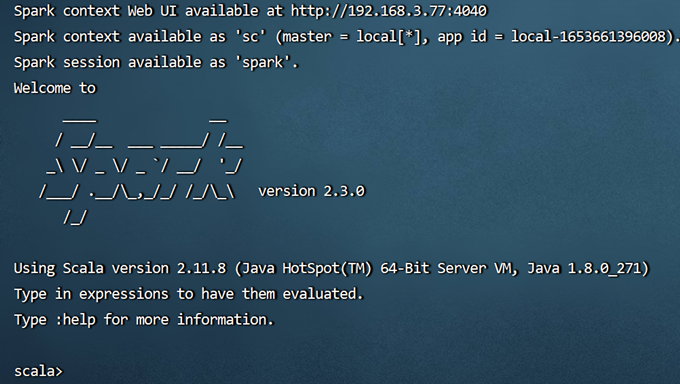
启动spark
cd /usr/local/spark/bin
spark-shell
输入以下测试案例:
scala> var r = sc.parallelize(Array(1,2,3,4))
r: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:23
scala> r.map(_*10).collect()
res0: Array[Int] = Array(10, 20, 30, 40)
打开浏览器,地址栏输入:http://192.168.3.77:4040, 其中192.168.3.77是虚拟机的内网静态IP地址。
检查spark版本命令。
[root@master tools]# spark-submit --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12, Java HotSpot(TM) 64-Bit Server VM, 1.8.0_271
Branch HEAD
Compiled by user centos on 2020-02-02T19:38:06Z
Revision cee4ecbb16917fa85f02c635925e2687400aa56b
Url https://gitbox.apache.org/repos/asf/spark.git
Type --help for more information.