Python3基础教程(七十五)
POP3接收邮件
Python 内置一个 poplib 模块,实现了 POP3 协议,可以直接用来收邮件。
1.POP3
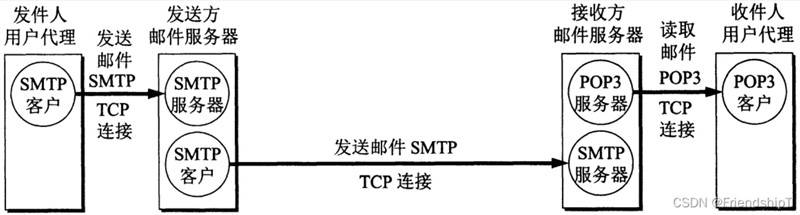
POP3,全名为“Post Office Protocol - Version 3”,即“邮局协议版本3”。是TCP/IP协议族中的一员,由RFC1939 定义。本协议主要用于支持使用客户端远程管理在服务器上的电子邮件。
POP3 协议收取的不是一个已经可以阅读的邮件本身,而是邮件的原始文本,这和 SMTP 协议很像,SMTP 发送的也是经 过编码后的一大段文本。要把 POP3 收取的文本变成可以阅读的邮件,还需要用 email 模块提供的各种 类来解析原始文本,变成可阅读的邮件对象。
2.实例
接收163邮箱的最新的邮件,并解析邮件内容。
# -*- coding: utf-8 -*-
# @Time : 2022/5/10 9:17
# @File : pop3demo.py
# @Software : PyCharm
import poplib
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
def get_origin_text(): # 获取邮件原始文本
# 连接到POP3服务器
pop_server = poplib.POP3("pop.163.com")
# 邮箱号
pop_server.user("xxxxx@163.com")
# 授权码
pop_server.pass_("CVUERWRTDGFDVWRR") #
# stat()返回(邮件数,邮件尺寸)
# print('邮件数: %s. 邮件尺寸: %s' % pop_server.stat())
# list()返回所有邮件的编号列表,默认返回20个元素
resp, mails, octets = pop_server.list() # 编号最大的为最新的一封
# 获取最新的一封邮件(索引号从1开始)
index = len(mails)
# print(index)
resp, lines, octets = pop_server.retr(index) # 返回(状态信息,邮件,邮件尺寸)
# lines存储了邮件的原始文本的每一行,可以获得整个邮件的原始文本
msg_content = b'\r\n'.join(lines).decode('utf-8') # b表示:后面字符串是bytes类型。
msg = Parser().parsestr(msg_content)
# 退出连接
pop_server.quit()
return msg
def decode_str(s): # 解码字符串
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
def set_charset(msg): # 设置字符集
charset = msg.get_charset() # 获取字符集
if charset is None:
content_type = msg.get('Content-Type', '').lower()
pos = content_type.find('charset=')
if pos >= 0:
charset = content_type[pos + 8:].strip()
return charset
def parse_msg(msg):
# 解析邮件头
for header in ['From', 'To', 'Subject']: # 遍历获取发件人,收件人,主题的相关信息
value = msg.get(header, '') # 获取邮件头的内容
if value:
if header == 'Subject': # 获取主题的信息,并解码
value = decode_str(value) # 解码字符串
else:
hdr, addr = parseaddr(value) # 解析字符串中的邮件地址
name = decode_str(hdr) # 解码字符串
value = '%s <%s>' % (name, addr)
print('%s: %s' % (header, value))
# 解析邮件正文
if (msg.is_multipart()): # 如果消息由多个部分组成,则返回True
parts = msg.get_payload() # 返回一个包含邮件所有的子对象的列表
for n, part in enumerate(parts): # 枚举,遍历各个对象
print('part %s' % (n))
parse_msg(part)
else:
content_type = msg.get_content_type() # 获取邮件信息的内容类型
if content_type == 'text/plain' or content_type == 'text/html': # 如果是纯文本或者html类型
content = msg.get_payload(decode=True) # 返回一个包含邮件所有的子对象(已解码)的列表
charset = set_charset(msg) # 设置字符集
if charset: # 字符集不为空
content = content.decode(charset) # 解码
print('Text: %s' % (content))
else:
print('Attachment: %s' % (content_type)) # 附件
if __name__ == "__main__":
msg = get_origin_text() # 第一步:用 poplib 获取邮件的原始文本。
parse_msg(msg) # 第二步:用 email 解析原始文本,还原为邮件对象。
运行结果:
From: simoniu <45833626@qq.com>
To: bob <xxxx@163.com>
Subject: 邮件主题-测试
part 0
From:
To:
Subject:
Attachment: image/jpg
part 1
From:
To:
Subject:
Text: <html><body><h1>Hello</h1><p><img src="cid:0"></p></body></html>
小结: 用Python的poplib模块收取邮件分两步:第一步:用 poplib 获取邮件的原始文本。第二步:用 email 解析原始文本,还原为邮件对象。