1.python的字符集
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python3的字符串支持全世界所有国家的语言和文字。
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符。
以汉字‘中’为例,Ascii和utf-8,unicode三者之间的关系见下图:

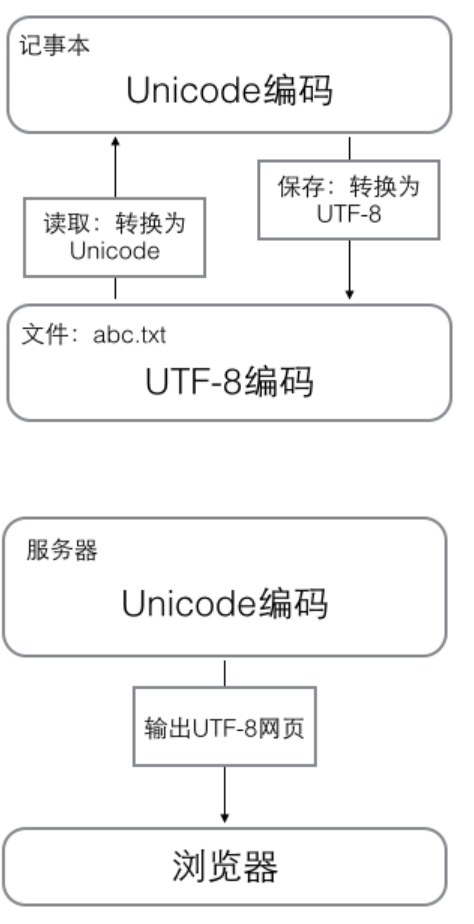
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
实例:
# -*- coding: utf-8 -*-
# @Time : 2022/3/26 14:11
# @File : charset.py
# @Software : PyCharm
s = '中'
print('中字的unicode编码:',ord(s))
n = 20013
print('20013转换为字符:',chr(n))
print(hex(ord('中')))
print('\u4e2d')
#通过encode()方法可以编码为指定的bytes
str="中文"
#可以观察到使用utf-8字符集时,一个汉字占三个字节
print(str.encode('utf-8'))
str="java"
print(str.encode('utf-8'))
#bytes类型的数据用带b前缀的单引号或双引号表示
print(type(b'hello'))
print(type('hello'))
str="你好python"
print(str.encode('utf-8'))
#计算字符个数
print(len(str))
#计算字节的个数
print(len(b'\xe4\xbd\xa0\xe5\xa5\xbdpython'))
运行结果:
中字的unicode编码: 20013
20013转换为字符: 中
0x4e2d
中
b'\xe4\xb8\xad\xe6\x96\x87'
b'java'
<class 'bytes'>
<class 'str'>
b'\xe4\xbd\xa0\xe5\xa5\xbdpython'
8
12
2.字符串拼接
方法1:使用加号“+”连接字符串。
但在python中,尽量少用加号“+”连接字符串,原因如下:在python中,String对象是定长对象,一旦创建,长度就不可变化,若是使用+号连接两个字符串,则会新开辟一段长度总和长度的内存,再将两个字符串memcpy进去。如果要连接N个String对象,则要进行N-1次内存申请和拷贝。官方推荐的是使用字符串的join方法。
方法2:使用逗号连接字符串。
python可用逗号“,”将多个字符串连接为一个元组,再通过join()方法将元组中的各个元素连接为一个字符串,从而达到连接字符串的目的。若是直接将字符串逗号连接后print,字符串之间会多一个空格。
方法3:通过“%”连接字符串
这种功能比较强大,借鉴了C语言中 printf 函数的功能。
方法4:直接连接字符串 python独有的方法。只要把两个字符串放在一起,无论中间有空白或没有空白,两个字符串将自动连接为一个字符串(空格不会自动去掉)。
方法5:多行字符串拼接() python遇到未闭合的小括号,自动将多行拼接为一行,相比三个引号和换行符,这种方式不会把换行符、前导空格当作字符。
实例:
# -*- coding: utf-8 -*-
# @Time : 2022/4/9 11:13
# @File : strcat.py
# @Software : PyCharm
s1 = 'hello,'
s2 = 'world'
str1 = s1, s2
str2 = ('select * '
'from table '
'where id=888')
# 不推荐使用+号拼接
print(s1 + s2)
# 逗号拼接默认带空格
print(s1,s2)
# 推荐使用join
print(''.join(str1))
# 指定分隔符
print('_'.join(str1))
# 推荐使用%s
print('%s%s' % (s1, s2))
# 直接字符串拼接
print('hello,' 'world')
# 直接字符串拼接不能用于变量
#print(s1 s2)
print(str2)
运行结果:
hello,world
hello, world
hello,world
hello,_world
hello,world
hello,world
select * from table where id=888