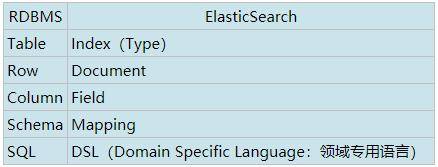
1.Elasticsearch基本概念
 |概念|说明|
|-|-|-|
|集群(cluster)|cluster就是一个及以上个node的集合,它们一起存储你的所有数据,提供跨节点的搜索和索引能力,集群通过一个唯一的名字来标识。|
|节点(node)|一个node就是一个es实例,每个节点都可以存储数据,参与索引(添加)数据,搜索|
|索引库(indices)|indices是index的复数,代表许多的索引|
|索引(index)|一个索引可以定义一个或者多个类型,文档必须属于一个类型|
|类型(type)|类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念。|
|文档(document)|存入索引库原始的数据。比如每一条商品记录,就是一个文档|
|字段(field)|文档中的属性|
|映射配置(mappings)|字段的数据类型、属性、是否索引、是否存储等特性|
|分片(shard)|es中的shard用来解决节点的容量上限问题,通过将index分为多个分片(默认为一个也就是不分片),一个或多个node共同存储该index的所有数据实现水平拓展|
|副本(replicas)|由于数据只有一份,如果一个node挂了,那存在上面的数据就都丢了,有了replicas,只要不是存储这条数据的node全挂了,数据就不会丢失。|
|概念|说明|
|-|-|-|
|集群(cluster)|cluster就是一个及以上个node的集合,它们一起存储你的所有数据,提供跨节点的搜索和索引能力,集群通过一个唯一的名字来标识。|
|节点(node)|一个node就是一个es实例,每个节点都可以存储数据,参与索引(添加)数据,搜索|
|索引库(indices)|indices是index的复数,代表许多的索引|
|索引(index)|一个索引可以定义一个或者多个类型,文档必须属于一个类型|
|类型(type)|类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念。|
|文档(document)|存入索引库原始的数据。比如每一条商品记录,就是一个文档|
|字段(field)|文档中的属性|
|映射配置(mappings)|字段的数据类型、属性、是否索引、是否存储等特性|
|分片(shard)|es中的shard用来解决节点的容量上限问题,通过将index分为多个分片(默认为一个也就是不分片),一个或多个node共同存储该index的所有数据实现水平拓展|
|副本(replicas)|由于数据只有一份,如果一个node挂了,那存在上面的数据就都丢了,有了replicas,只要不是存储这条数据的node全挂了,数据就不会丢失。|
要注意的是:Elasticsearch 本身就是分布式的,因此即便你只有一个节点,Elasticsearch 默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。
2.倒序索引
索引的本质,其实是描述了一个事物到另一个事物之间的关联关系,我们可以通过这种关联关系,即索引,方便快速的从一个事物找到另一个事物。正常来讲,我们通常是以一个事物具备哪些特征来描述一个事物的,比如:博主是一个帅气、阳光、乐观、向上的人。也就是说,我们从博主出发,能找到帅气、阳光、乐观、向上等四个关键词,这其实就是一个正序索引。如下:博主->帅气博主->阳光博主->乐观博主->向上博主,那么什么倒排索引呢?就是把正序索引反过来。帅气->阳光->乐观->向上->博主。
简单比较正序索引和倒序索引。 - 正序索引:文档ID到文档内容和单词的关联 - 倒序索引:单词到文档ID的关系