ElasticSearch是基于apache lucene构建的开源搜索引擎。使用Java编写,提供简易的RESTFul API。ElasticSearch的设计目标就是屏蔽lucene的复杂性,让全文检索更加的简单易用。
Elasticsearch 也是一个实时的分布式搜索分析引擎,轻松地实现横向扩展,可支持PB级别的结构化和非结构化的数据处理。

1.elasticsearch的产生背景
elasticsearch的诞生基于解决以下问题: - 大规模数据如何检索?当系统数据量上了10亿、100亿条的时候,如何解决检索难题。 - 非关系型数据库的解决方案? - 超大数据无法放入内存怎么办?数据放在内存中查询速度快,但是当我们的数据达到PB级别时,成本巨大决定了其不现实。
2.elasticsearch的应用场景
- 海量数据分析引擎
- 站内全文检索
- 数据仓库
一些一线公司的实际应用场景:
- 英国卫报-实时分析公众对文章的回复
- 维基百科、Github-站内实.搜索
- 百度-站内实时日志监控平台
3.学习elasticsearch的前置知识
- 熟悉使用maven建构项目
- 熟悉Springboot的基本使用
4.常见的全文检索引擎
- Lucene Lucene是Java家族中最为出名的一个开源搜索引擎,在Java世界中属于标准的全文检索程序,它提供了完整的查询引擎和索引引擎。 但是它也存在一些缺点:
- 不支持分布式,无法扩展,海量数据下会存在瓶颈。
- 提供的都是低级API,使用繁琐。
-
没有提供web界面,不便于管理。
-
Solr Solr是一个用java开发的独立的企业级搜索应用服务器,它是基于Lucene的。 它解决了Lucene的一些痛点,提供了web界面,以及高级API接口。 并且从Solr4.0版本开始,Solr开始支持分布式,称之为Solrcloud。
-
Elasticsearch Elasticsearch是一个采用Java语言开发的,基于Lucene的开源、分布式的搜索引擎,能够实现实时搜索。 它最重要的一个特点是天生支持分布式,可以这样说,Elasticsearch就是为了分布式而生的。 它对外提供REST API接口,便于使用,通过外部插件实现web界面支持,便于管理集群。 Elasticsearch一般我们会简称为ES。
5.Solr vs Elasticsearch
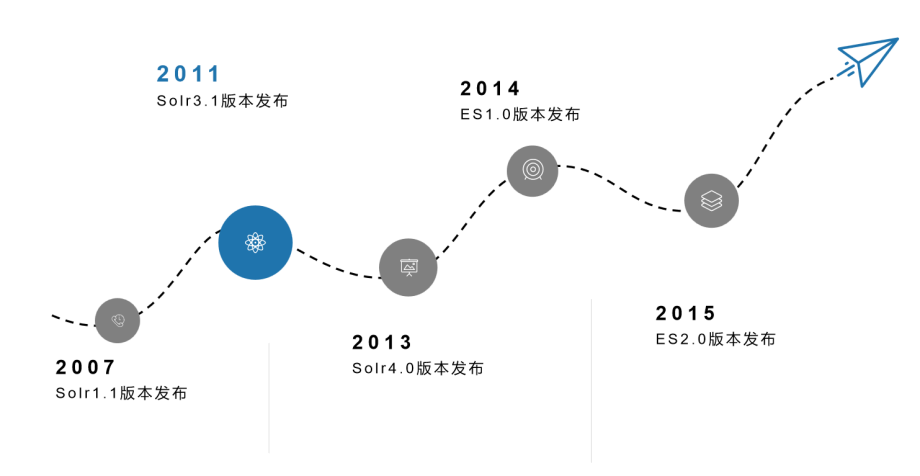
Solr从2007年就出现了,在传统企业中应用的还是比较广泛的,并且在2013年的时候,Solr推出了4.0版本,提供了Solrcloud,开始正式支持分布式集群。ES在2014年的时候才正式推出1.0版本,所以它的出现要比Solr晚很多年。但是ES从一开始就是为了解决海量数据下的全文检索,所以在分布式集群相关特性层面,ES会优于Solrcloud。
建议方案: - 如果之前公司里面已经深度使用了Solr,现在为了解决海量数据检索问题,建议优先考虑使用Solrcloud。 - 如果之前没有使用过Solr,那么在海量数据的场景下,建议优先考虑使用ES。
6.MySQL VS Elasticsearch
为了便于理解ES,在这里我们拿MySQL和ES做一个对比分析:

名词解释: - MySQL中有Database(数据库)的概念,对应的在ES中有Index(索引库)的概念。 - MySQL中有Table(表)的概念,对应的在ES中有Type(类型)的概念,不过需要注意,ES在1.x~5.x版本中是正常支持Type的,每一个Index下面可以有多个Type。从6.0版本开始,每一个Index中只支持1个Type,属于过渡阶段。从7.0版本开始,取消了Type,也就意味着每一个Index中存储的数据类型可以认为都是同一种,不再区分类型了。 - MySQL中有Row(行)的概念,表示一条数据,在ES中对应的有Document(文档)。 - MySQL中有Column(列)的概念,表示一条数据中的某个列,在ES中对应的有Field(字段)。
ES为何要取消Type?
主要还是基于性能方面的考虑。因为ES设计初期,是直接参考了关系型数据库的设计模型,存在了 Type(表)的概念。但是,ES的搜索引擎是基于Lucene的,这种基因决定了Type是多余的。在关系型数据库中Table是独立的,但是在ES中同一个Index中不同Type的数据在底层是存储在同一个Lucene的索引文件中的。如果在同一个Index中的不同Type中都有一个id字段,那么ES会认为这两个id字段是同一个字段,你必须在不同的Type中给这个id字段定义相同的字段类型,否则,不同Type中的相同字段名称就会在处理的时候出现冲突,导致Lucene处理效率下降。除此之外,在同一个Index的不同Type下,存储字段个数不一样的数据,会导致存储中出现稀疏数据,影响Lucene压缩文档的能力,最终导致ES查询效率降低。