HashMap底层是由哈希表实现的,是非常重要的数据结构,哈希表的基本结构就是“数组+链表”。 数组:占用空间连续,寻址容易,查询速度快,但是,增加和删除效率非诚低。 链表:占用空间不连续,寻址困难,查询速度慢,但是,增加和删除效率非常高。
1.HashMap的存储结构
- HashMap底层是以数组方式进行存储。将key-value对作为数组中的一个元素进行存储。
- key-value都是Map.Entry中的属性。其中将key的值进行hash之后进行存储,即每一个key都是计算hash值,然后再存储。每一个Hash值对应一个数组下标,数组下标是根据hash值和数组长度计算得来。
- 由于不能的key有可能hash值相同,即该位置的数组中的元素出现两个,对于这种情况,HashMap采用链表形式进行存储。 下图描述了HashMap的存储结构图
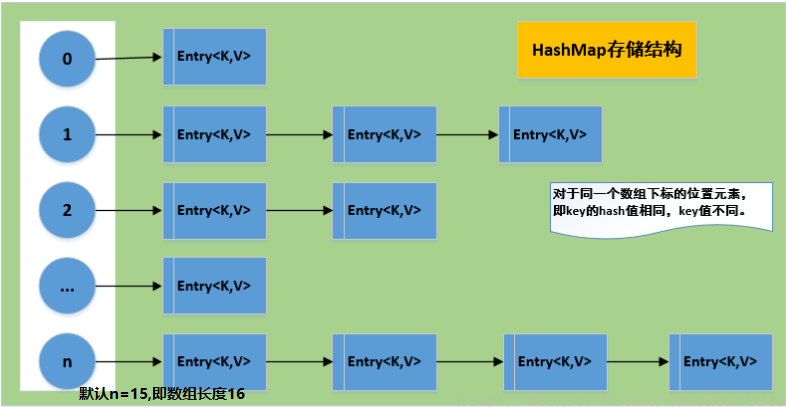
2.HashMap的存储原理
HashMap的存储过程如下: - 获取到传过来的key,调用hash算法获取到hash值。 - 通过获取到的hash值以及数组的长度算出数组的下标。 1)hashCode:HashMap的Key对象里面的方法hashCode产生的值。 2)hash:通过hashCode的值,通过一定算法产生的hash值。 3)index:通过hash值计算产生要保存到数组的下标。 index = hash % length, index范围就是0-length-1; - 把传过来的key和value存到该数组下标当中。 - 如该数组下标下以及有值了,则使用链表,jdk7是把新增元素添加到头部节点 jdk8则添加到尾部节点。当链表的长度大于或等于8的时候则会把链表变成红黑树。
实例:
Map map =new HashMap();
map.put(33,"33");
map.put(1,"1");
map.put(12,"12");
map.put(25,"25");
map.put(17,"17");
map.put(9,"9");
Set<Map.Entry> set = map.entrySet();
System.out.println("-----------entry遍历-----------");
for(Map.Entry entry: set){
System.out.println(entry.getKey() + "=" + entry.getValue());
}
System.out.println("---------key set 遍历----------");
Set keys = map.keySet();
for(Object k: keys){
System.out.println(k + "=" + map.get(k));
}
运行结果:

3.HashMap的扩容机制
分析HashMap源码有以下代码:
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
*默认的负载因子是0.75f,也就是75% 负载因子的作用就是计算扩容阈值用,比如说使用
*无参构造方法创建的HashMap 对象,他初始长度默认是16 阈值 = 当前长度 * 0.75 就
*能算出阈值,当当前长度大于等于阈值的时候HashMap就会进行自动扩容
*/
HashMap的加载因子默认值是0.75,所谓加载因子表示Map的值填充程度。如果加载因子越大,则空间使用率越高,但是冲突也越高,简单说就是省空间,费时间。如果加载因子越低,空间使用率越低,但是冲突也会降低,简单说就是费空间,省时间。因此通过一个简单的数学推理,可以测算出这个数值在0.75左右是比较合理的。
散列表数组初始长度,可从HashMap的以下源码分析。
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* HashMap中散列表数组初始长度为 16 (1 << 4)
* 创建HashMap的时候可以设置初始化容量和设置负载因子,
* 但HashMap会自动优化设置的初始化容量参数,确保初始化
* 容量始终为2的幂
*/
首先我们看hashMap的源码可知当新put一个数据时会进行计算位于table数组(也称为桶)中的下标:
int index =key.hashCode()&(length-1);
HashMap每次扩容都是以 2的整数次幂进行扩容,那么这个值为啥是16,而不是64或者8呢,因为是64或者8的话很容易导致map扩容影响性能,如果分配太小很容易引发冲突,如果分配的太大的话又会浪费资源,所以就使用16作为初始大小比较合适。