导出onnx模型
导出onnx模型
1.ONNX模型
ONNX(Open Neural Network Exchange)是一种开放的神经网络交换格式,旨在为AI模型提供一个统一的表示方式。它允许开发者在不同的深度学习框架之间转换模型,从而实现模型的可移植性和互操作性。
ONNX的主要特点:
- 跨框架兼容性:支持从PyTorch、TensorFlow、Keras、MXNet等框架转换模型。
- 硬件加速支持:可以在各种硬件平台上优化执行。
- 广泛的操作符支持:包含丰富的神经网络操作符集。
- 可扩展性:允许添加自定义操作符和属性。
ONNX生态系统:
- ONNX格式规范
- ONNX Runtime执行引擎
- 模型转换工具
- 模型优化工具
- 推理加速库
2.YOLOV8的Pytorch模型导出为onnx模型
from ultralytics import YOLO
if __name__ == '__main__':
# 加载预训练模型
model = YOLO('./model/yolov8n.pt') # 你可以根据需要更换为yolov8s, yolov8m, yolov8l, yolov8x等
# 导出模型到ONNX格式
model.export(format='onnx', imgsz=640, simplify=True, opset=12, device=None) # 这里的imgsz是输入图像的尺寸
# 导出的ONNX格式进行预测
model.predict('./images/sample007.jpg', save=True)
3.ONNX与PyTorch 原生模型(pt)推理速度对比
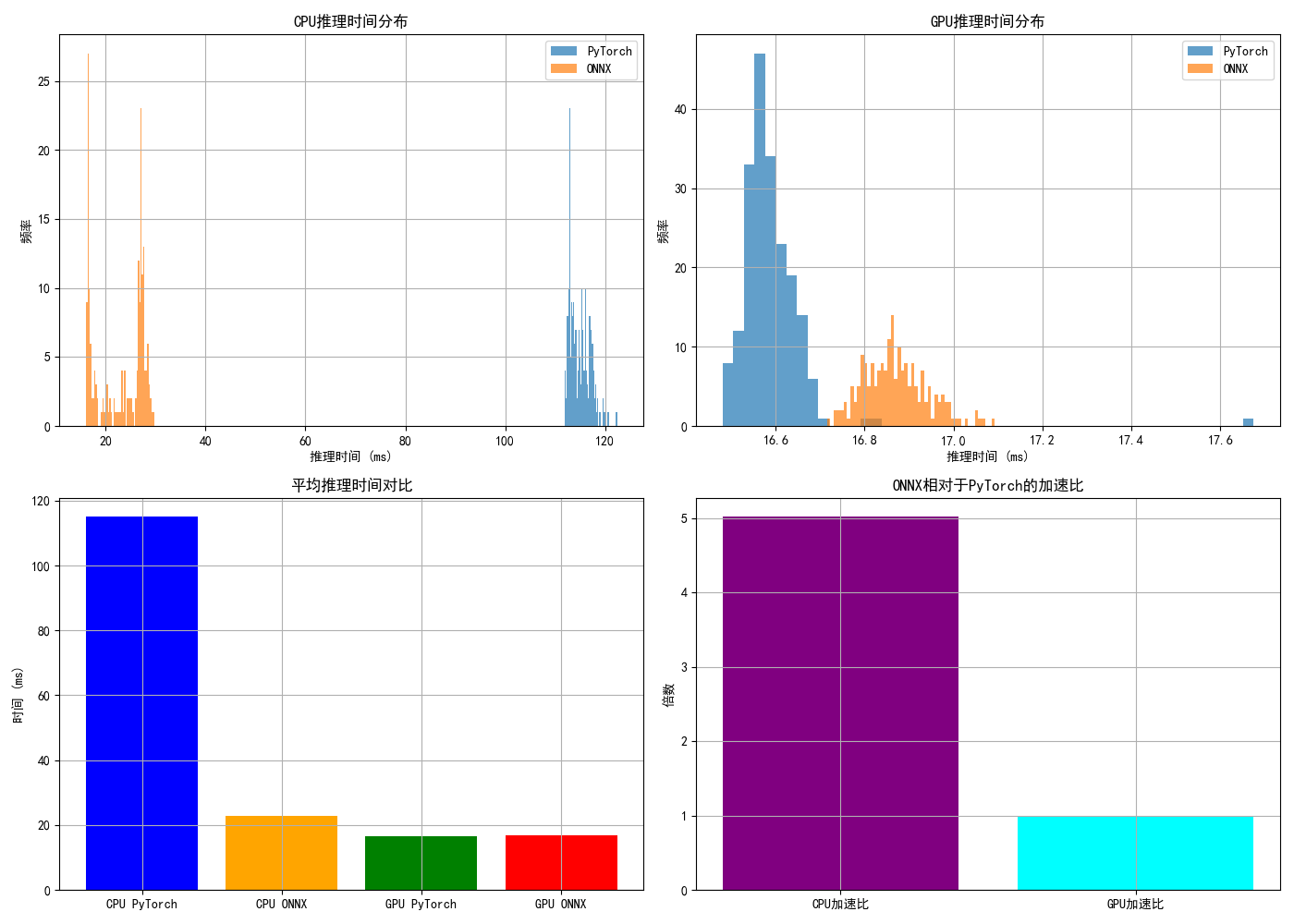
ONNX 与 PyTorch 原生模型(.pt/.pth)的推理速度对比,结论是:在大多数情况下,ONNX 模型经过优化后,推理速度会快于 PyTorch 原生模型,但这依赖于运行时环境、硬件加速库和模型结构。以下是详细分析:
ONNX 加速的主要原因有以下几点:
图优化 (Graph Optimization)
ONNX 将模型转换为静态计算图,运行时(如 ONNX Runtime)可执行以下优化:
- 算子融合(如 Conv + BatchNorm + ReLU 合并为单一算子)
- 常量折叠(预计算固定输入)
- 内存复用(减少中间结果拷贝)
- 死代码消除
- 这些优化在 PyTorch 的动态图(Eager Mode)中难以实现。
硬件专用加速
ONNX Runtime 支持:
- CPU:集成 Intel MKL-DNN、OpenMP 等。
- GPU:通过 CUDA/cuDNN 优化,支持 TensorRT 和 DirectML。
- 移动端:兼容 NNAPI(Android)、Core ML(iOS)等。
跨平台高效运行时
ONNX Runtime 专为生产环境设计,比 PyTorch 的默认推理模式更轻量级。

下面是一个完整的程序,用于证明ONNX模型比PyTorch原生模型推理速度更快。该程序使用ResNet-50作为基准模型,在CPU和GPU上分别测试两者的推理速度,并生成可视化对比图表:
import time
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision.models as models
import onnxruntime as ort
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
# 设置随机种子确保可重复性
torch.manual_seed(42)
np.random.seed(42)
class DummyDataset(Dataset):
"""创建虚拟数据集用于基准测试"""
def __init__(self, num_samples=1000):
self.num_samples = num_samples
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
# 生成随机图像数据 (224x224 RGB)
img = np.random.rand(224, 224, 3).astype(np.float32) # 修正形状为 (H, W, C)
return self.transform(img) # 转换为 (C, H, W)
def prepare_models():
"""准备PyTorch和ONNX模型"""
# 加载预训练的ResNet-50模型
pt_model = models.resnet50(pretrained=True)
pt_model.eval() # 设置为评估模式
# 保存PyTorch模型
torch.save(pt_model.state_dict(), "resnet50.pt")
# 创建正确的虚拟输入 (batch, channels, height, width)
dummy_input = torch.randn(1, 3, 224, 224)
# 导出为ONNX模型
torch.onnx.export(
pt_model,
dummy_input,
"resnet50.onnx",
export_params=True,
opset_version=17,
do_constant_folding=True,
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}}
)
return pt_model
def benchmark_pt_model(model, dataloader, device="cpu"):
"""基准测试PyTorch模型推理速度"""
model.to(device)
model.eval()
times = []
with torch.no_grad():
# 预热
for _ in range(10):
inputs = next(iter(dataloader)).to(device)
_ = model(inputs)
# 正式测试
for inputs in dataloader:
inputs = inputs.to(device)
start_time = time.perf_counter()
_ = model(inputs)
if device == "cuda":
torch.cuda.synchronize() # 确保CUDA操作完成
end_time = time.perf_counter()
# 记录每次推理时间(毫秒)
times.append((end_time - start_time) * 1000)
return times
def benchmark_onnx_model(onnx_path, dataloader, device="cpu"):
"""基准测试ONNX模型推理速度"""
# 设置ONNX Runtime执行提供者
providers = ["CPUExecutionProvider"] if device == "cpu" else ["CUDAExecutionProvider"]
# 创建ONNX Runtime会话
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
session = ort.InferenceSession(onnx_path, sess_options, providers=providers)
# 获取输入名称
input_name = session.get_inputs()[0].name
times = []
# 预热
for _ in range(10):
inputs = next(iter(dataloader)).numpy()
_ = session.run(None, {input_name: inputs})
# 正式测试
for inputs in dataloader:
inputs = inputs.numpy()
start_time = time.perf_counter()
_ = session.run(None, {input_name: inputs})
end_time = time.perf_counter()
# 记录每次推理时间(毫秒)
times.append((end_time - start_time) * 1000)
return times
def plot_results(cpu_results, gpu_results):
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False
"""可视化基准测试结果"""
plt.figure(figsize=(14, 10))
# CPU结果对比
plt.subplot(2, 2, 1)
plt.hist(cpu_results["pt"], bins=50, alpha=0.7, label="PyTorch")
plt.hist(cpu_results["onnx"], bins=50, alpha=0.7, label="ONNX")
plt.title("CPU推理时间分布")
plt.xlabel("推理时间 (ms)")
plt.ylabel("频率")
plt.legend()
plt.grid(True)
# GPU结果对比
plt.subplot(2, 2, 2)
plt.hist(gpu_results["pt"], bins=50, alpha=0.7, label="PyTorch")
plt.hist(gpu_results["onnx"], bins=50, alpha=0.7, label="ONNX")
plt.title("GPU推理时间分布")
plt.xlabel("推理时间 (ms)")
plt.ylabel("频率")
plt.legend()
plt.grid(True)
# 平均时间对比
plt.subplot(2, 2, 3)
avg_times = {
"CPU PyTorch": np.mean(cpu_results["pt"]),
"CPU ONNX": np.mean(cpu_results["onnx"]),
"GPU PyTorch": np.mean(gpu_results["pt"]),
"GPU ONNX": np.mean(gpu_results["onnx"]),
}
plt.bar(avg_times.keys(), avg_times.values(), color=['blue', 'orange', 'green', 'red'])
plt.title("平均推理时间对比")
plt.ylabel("时间 (ms)")
plt.grid(True)
# 加速比
plt.subplot(2, 2, 4)
speedups = {
"CPU加速比": np.mean(cpu_results["pt"]) / np.mean(cpu_results["onnx"]),
"GPU加速比": np.mean(gpu_results["pt"]) / np.mean(gpu_results["onnx"]),
}
plt.bar(speedups.keys(), speedups.values(), color=['purple', 'cyan'])
plt.title("ONNX相对于PyTorch的加速比")
plt.ylabel("倍数")
plt.grid(True)
plt.tight_layout()
plt.savefig("onnx_vs_pt_speed_comparison.png")
plt.show()
# 打印统计信息
print("\n=== 基准测试结果统计 ===")
print(f"CPU PyTorch 平均推理时间: {np.mean(cpu_results['pt']):.2f} ms ± {np.std(cpu_results['pt']):.2f}")
print(f"CPU ONNX 平均推理时间: {np.mean(cpu_results['onnx']):.2f} ms ± {np.std(cpu_results['onnx']):.2f}")
print(f"CPU 加速比: {np.mean(cpu_results['pt']) / np.mean(cpu_results['onnx']):.2f}x")
if gpu_results["pt"]:
print(f"\nGPU PyTorch 平均推理时间: {np.mean(gpu_results['pt']):.2f} ms ± {np.std(gpu_results['pt']):.2f}")
print(f"GPU ONNX 平均推理时间: {np.mean(gpu_results['onnx']):.2f} ms ± {np.std(gpu_results['onnx']):.2f}")
print(f"GPU 加速比: {np.mean(gpu_results['pt']) / np.mean(gpu_results['onnx']):.2f}x")
def main():
# 准备模型和数据
print("准备模型和数据...")
pt_model = prepare_models()
dataset = DummyDataset(num_samples=200) # 减少样本数量以加快测试
dataloader = DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0)
# 获取可用设备
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device.upper()}")
# CPU基准测试
print("\n在CPU上运行基准测试...")
cpu_pt_times = benchmark_pt_model(pt_model, dataloader, device="cpu")
cpu_onnx_times = benchmark_onnx_model("resnet50.onnx", dataloader, device="cpu")
# GPU基准测试(如果可用)
gpu_pt_times, gpu_onnx_times = [], []
if device == "cuda":
print("\n在GPU上运行基准测试...")
gpu_pt_times = benchmark_pt_model(pt_model, dataloader, device="cuda")
gpu_onnx_times = benchmark_onnx_model("resnet50.onnx", dataloader, device="cuda")
else:
print("\n未检测到GPU,跳过GPU基准测试")
# 结果分析和可视化
results = {
"cpu": {"pt": cpu_pt_times, "onnx": cpu_onnx_times},
"gpu": {"pt": gpu_pt_times, "onnx": gpu_onnx_times}
}
plot_results(results["cpu"], results["gpu"])
if __name__ == "__main__":
main()