1.Ragas的介绍
RAGAs (Retrieval-Augmented Generation Assessment) 它是一个框架,它可以帮助我们来快速评估RAG系统的性能,为了评估 RAG系统,RAGAs 需要以下信息: - question:用户输入的问题。 - answer:从 RAG 系统生成的答案(由LLM给出)。 - contexts:根据用户的问题从外部知识源检索的上下文即与问题相关的文档。 - reference: 人类提供的基于问题的真实(正确)答案ground_truths。 这是唯一的需要人类提供的信息。
安装依赖:
pip install ragas==0.2.6
2. Ragas 可以评价的指标(部分)
2.1 Context Precision 上下文精度
2.1.1 基于大模型的上下文精度
基于大模型是指使用大模型进行判断相关性。简单来说就是使用类似以下的prompt使评价大模型给出相关性。
Given question, answer and context verify if the context was useful in arriving at the given answer.
Give verdict as "1" if useful and "0" if not with json output.
#翻译结果
给定一个问题、答案和上下文(context),你需要评估这个上下文是否对生成给定的答案有帮助。根据评估结果,输出一个 JSON 格式的verdict(判决),其中:
如果上下文有用,则 verdict 为 "1"。
如果上下文无用,则 verdict 为 "0"。
基于大模型的prompt实现:
from langchain_openai import ChatOpenAI
from ragas.llms import LangchainLLMWrapper
chat_model = LangchainLLMWrapper(ChatOpenAI(
openai_api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
base_url="https://api.siliconflow.cn/v1",
model="Qwen/Qwen2.5-7B-Instruct"
))
from ragas.embeddings import LangchainEmbeddingsWrapper
from langchain_huggingface import HuggingFaceEmbeddings
embedding = LangchainEmbeddingsWrapper(HuggingFaceEmbeddings(model_name="models/AI-ModelScope/bge-large-zh-v1___5"))
# 计算上下文精度
from ragas.metrics._context_precision import LLMContextPrecisionWithReference
context_precision = LLMContextPrecisionWithReference(llm=chat_model)
from ragas import SingleTurnSample
sample = SingleTurnSample(
user_input="故宫位于哪里?", # 用户的提问
response="故宫在北京。", # LLM的回答
reference="故宫位于北京。", # 真实答案
retrieved_contexts=["北京是中国的首都", "故宫位于北京"] # 知识库相似度提取出的内容
)
print(context_precision.single_turn_score(sample))
运行效果:
0.99999999995
2.1.2 Non LLM Based Context Precision 不基于大模型的上下文精度(传统方法-编辑距离)
编辑距离:
编辑距离(Edit Distance),也称为Levenshtein距离,是由俄罗斯科学家 Vladimir Levenshtein 在 1965 年提出的。它衡量的是将一个字符串转换为另一个字符串所需要的最少单字符编辑操作次数。这些编辑操作包括插入(insertion)、删除(deletion)和替换。
下面用一个例子解释编辑距离的计算(动态规划): 假设我们有两句话"故宫在北京", "故宫位于北京",要计算这两句话的编辑距离,即前句最少经过几次编辑操作后可以得到后句。直观上看这两句话的不同在于”在“和”位于“,于是我们最简单的方法是将”在“改为”位“然后在后面增加一个”于“,这样我们只使用了两次操作就将"故宫在北京"变成了"故宫位于北京",所以编辑距离就是2,而标准化后的的编辑距离就是2/6(最长的字符串长度)=0.33333。
那我们如何使用动态规划去计算呢?首先我们需要画出状态转移矩阵:
分解字符: 句子A:“故”、“宫”、“在”、“北”、“京”(长度5) 句子B:“故”、“宫”、“位”、“于”、“北”、“京”(长度6)
定义状态转移矩阵: 矩阵 dp[i][j] 表示将A的前 i 个字符转换为B的前 j 个字符的最小编辑操作数。矩阵大小为 (5+1) × (6+1)。
初始化边界条件: dp[0][j] = j(插入 j 次) dp[i][0] = i(删除 i 次)
填充矩阵规则: 若 A[i-1] == B[j-1],则 dp[i][j] = dp[i-1][j-1](无需操作)。 否则,dp[i][j] = min(dp[i-1][j] + 1(删除),dp[i][j-1] + 1(插入),dp[i-1][j-1] + 1(替换))。
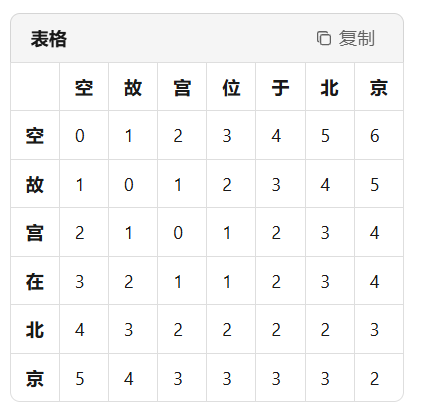
编辑距离:矩阵右下角值 dp[5][6] = 2,即需要两次操作。
操作解释:
- 将A中的“在”替换为“位”(替换操作)。
- 在“位”后插入“于”(插入操作)。
结论:两句话的编辑距离为 2,状态转移矩阵如上表所示。
代码实现:
strA = "故宫在北京"
strB = "故宫位于北京"
def edit_distance(strA:str, strB:str) -> int:
m, n = len(strA) + 1, len(strB) + 1
dp = [[0] * n for _ in range(m)]
# print(dp)
# 初始化dp数组
for i in range(m):
dp[i][0] = i
for j in range(n):
dp[0][j] = j
# print(dp)
for i in range(1, m):
for j in range(1, n):
if strA[i-1] == strB[j-1]:
dp[i][j] = dp[i-1][j-1]
else:
dp[i][j] = min(dp[i-1][j-1], dp[i-1][j], dp[i][j-1]) + 1
return dp[-1][-1]
distance = edit_distance(strA, strB)
print(distance)
print(distance / max(len(strA), len(strB)))
# 使用库函数:
from rapidfuzz import distance
print(distance.Levenshtein.normalized_distance(strA, strB))
运行效果:
2
0.3333333333333333
0.3333333333333333
不基于大模型的上下文精度的代码实现:
而在Ragas中也是同样的方法计算上下文精度,即计算检索到的文档和所有参考文档的标准化编辑距离,然后用1减去标准化编辑距离表示相关性,取最大的相关性值作为评价标准。若大于相关性阈值(默认0.5)则认为相关返回1(0.9999999)否则不相关返回0。
from ragas.metrics._context_precision import NonLLMContextPrecisionWithReference
context_precision = NonLLMContextPrecisionWithReference()
from ragas import SingleTurnSample
sample = SingleTurnSample(
retrieved_contexts=["故宫在北京"],
reference_contexts=["故宫位于北京"]
)
print(context_precision.single_turn_score(sample))
运行效果:
0.9999999999
2.2 Context Recall 上下文召回
2.2.1 基于大模型的上下文召回
注意比较召回与精准度的区别: - 召回(Recall):逐句检查答案内容的覆盖情况,确保答案中的所有信息都能从上下文中找到来源。 - 精确度(Precision):整体检查答案与上下文的关联性,确认答案是否依赖上下文提供的信息。
基于大模型是指使用大模型进行判断相关性。简单来说就是使用类似以下的prompt使评价大模型给出相关性:
Given a context, and an answer, analyze each sentence in the answer and classify if the sentence can be
attributed to the given context or not. Use only 'Yes' (1) or 'No' (0) as a binary classification.
Output json with reason.
#翻译结果
给定一个上下文(context)和一个答案(answer),你需要逐句分析答案中的每一句话,并判断这句话是否可以归因于提供的上下文。
对于每一句话,你将进行二元分类,使用 1 表示“可以归因于上下文”(即“是”),使用 0 表示“不能归因于上下文”(即“否”)。最终,你需要以JSON 格式输出每个句子的分类结果及其理由。
代码实现:
from langchain_openai import ChatOpenAI
from ragas.llms import LangchainLLMWrapper
chat_model = LangchainLLMWrapper(ChatOpenAI(
openai_api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxx",
base_url="https://api.siliconflow.cn/v1",
model="Qwen/Qwen2.5-7B-Instruct"
))
from ragas.embeddings import LangchainEmbeddingsWrapper
from langchain_huggingface import HuggingFaceEmbeddings
embedding = LangchainEmbeddingsWrapper(HuggingFaceEmbeddings(model_name="models/AI-ModelScope/bge-large-zh-v1___5"))
# 计算上下文召回
from ragas.metrics import LLMContextRecall
context_recall = LLMContextRecall(llm=chat_model)
from ragas import SingleTurnSample
sample = SingleTurnSample(
user_input="故宫位于哪里?", # 用户的提问
response="故宫在北京。", # LLM的回答
reference="故宫位于北京。", # 真实答案
retrieved_contexts=["北京是中国的首都", "故宫位于北京"] # 知识库相似度提取出的内容
)
print(context_recall.single_turn_score(sample))
运行效果:
1.0
2.2.2 不基于大模型的上下文召回(传统方法-编辑距离)
计算距离的方法和之前的一样,然后计算召回率。
from ragas.metrics import NonLLMContextRecall
context_recall = NonLLMContextRecall()
from ragas import SingleTurnSample
sample = SingleTurnSample(
retrieved_contexts=["故宫在北京"],
reference_contexts=["故宫位于北京"]
)
print(context_recall.single_turn_score(sample))
运行效果:
1.0
2.3 Response Relevancy 响应相关性
Response Relevancy指标侧重于评估生成的答案与给定问题的相关性。对于不完整或包含冗余信息的答案,分数较低,分数越高表示相关性越高。 注意响应相关性评估并不考虑事实,而是对答案缺乏完整性或包含冗余细节的情况进行惩罚。为了计算此分数,系统会提示 LLM 多次为生成的答案生成合适的问题,并计算这些生成的问题与原始问题之间的平均余弦相似度。 其思想就是,如果答案能够很好的解决问题,那么通过答案生成的问题应该和原始问题差不多。
from langchain_openai import ChatOpenAI
from ragas.llms import LangchainLLMWrapper
chat_model = LangchainLLMWrapper(ChatOpenAI(
openai_api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
base_url="https://api.siliconflow.cn/v1",
model="Qwen/Qwen2.5-7B-Instruct"
))
from ragas.embeddings import LangchainEmbeddingsWrapper
from langchain_huggingface import HuggingFaceEmbeddings
embedding = LangchainEmbeddingsWrapper(HuggingFaceEmbeddings(model_name="models/AI-ModelScope/bge-large-zh-v1___5"))
# 计算响应相关性
from ragas import SingleTurnSample
from ragas.metrics import ResponseRelevancy
sample = SingleTurnSample(
user_input="故宫位于哪里?",
response="故宫在北京"
)
scorer = ResponseRelevancy(llm=chat_model, embeddings=embedding)
print(scorer.single_turn_score(sample))
运行效果:
0.3303978438689674
2.4 Faithfulness 忠诚度
Faithfulness指标衡量生成的答案与给定上下文的事实一致性。它是根据答案和检索到的上下文计算得出的。答案缩放到 (0,1) 范围。越高越好。 如果答案中提出的所有声明都可以从给定的上下文中推断出来,则生成的答案被认为是忠实的。要计算此值,首先从生成的答案中确定一组陈述。 然后,这些陈述中的每一个都与给定的上下文进行交叉检查,以确定是否可以从上下文中推断出来。忠实度分数由下式给出:

计算忠诚度的步骤: 将答案改写为简单句(分为多个陈述)如例子中将回答“爱因斯坦于 1879 年 3 月 14 日出生于德国。”改写为两个句子“爱因斯坦出生在德国。”和“爱因斯坦出生于 1879 年 3 月 14 日。” 然后对于每个生成的语句,验证是否可以从给定的上下文中推断出它,发现都可以推断出来,于是忠诚度为1。
from langchain_openai import ChatOpenAI
from ragas.llms import LangchainLLMWrapper
chat_model = LangchainLLMWrapper(ChatOpenAI(
openai_api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
base_url="https://api.siliconflow.cn/v1",
model="Qwen/Qwen2.5-7B-Instruct"
))
# 计算忠诚度
from ragas import SingleTurnSample
from ragas.metrics import Faithfulness
sample = SingleTurnSample(
user_input="爱因斯坦出生于何时何地?",
response="爱因斯坦于1879年3月14日出生于德国。",
retrieved_contexts=["阿尔伯特·爱因斯坦(Albert Einstein,生于 1879 年 3 月 14 日)是一位出生于德国的理论物理学家,被广泛认为是有史以来最伟大、最有影响力的科学家之一"],
)
scorer = Faithfulness(llm=chat_model)
print(scorer.single_turn_score(sample))
运行效果:
1.0
3.使用Ragas评估RAG系统
from langchain_openai import ChatOpenAI
# 初始化聊天大模型
chat_model = ChatOpenAI(
openai_api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
base_url="https://api.siliconflow.cn/v1",
model="Qwen/Qwen2.5-7B-Instruct"
)
# 初始化评估大模型
eval_model = ChatOpenAI(
openai_api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
base_url="https://api.siliconflow.cn/v1",
model="Qwen/Qwen2.5-7B-Instruct"
)
# 初始化嵌入模型
from langchain_huggingface import HuggingFaceEmbeddings
embedding = HuggingFaceEmbeddings(model_name="models/AI-ModelScope/bge-large-zh-v1___5")
# 初始化提示词模板
from langchain_core.prompts import ChatPromptTemplate
system_prompt = "根据以下已知信息回答用户问题,\n 已知信息:{context}"
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("user", "问题:{question}")
])
# 加载文档
from langchain_community.document_loaders import TextLoader
loader = TextLoader("黑悟空.txt", encoding="UTF-8")
docs = loader.load()
# 切片/分块
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
chunks = text_splitter.split_documents(docs)
# 使用FAISS做存储并得到检索器
from langchain_community.vectorstores import FAISS
vs = FAISS.from_documents(chunks, embedding)
retriever = vs.as_retriever()
# 初始化输出解析器
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
# 构建RAG链
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| chat_model
| output_parser
)
# 导入csv文件,获得问题和标准回答
import pandas as pd
dataset = pd.read_csv("黑悟空.csv")
# 读取问题、真实答案字段、获取LLM的回答、获取上下文
questions = dataset["问题"].to_list()
ground_truths = dataset["回答"].to_list()
answers = []
contexts = []
for question in questions:
answers.append(rag_chain.invoke(question))
contexts.append([doc.page_content for doc in retriever.get_relevant_documents(question)])
# 创建输入ragas的数据
data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"reference": ground_truths
}
# 构建输入RAGAS的数据集
from datasets import Dataset
dataset = Dataset.from_dict(data)
# 使用RAGAS进行RAG的评估
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall
result = evaluate(
dataset=dataset,
metrics=[faithfulness, answer_relevancy, context_precision, context_recall],
llm=eval_model,
embeddings=embedding
)
# 将测评结果显示出来
pd.set_option("display.max_columns", None)
pd.set_option("display.max_rows", None)
pd.set_option("display.max_colwidth", None)
df = result.to_pandas()
print(df)
运行效果:
Evaluating: 100%|██████████| 40/40 [01:00<00:00, 1.52s/it]
...
faithfulness answer_relevancy context_precision context_recall
0 1.000000 0.718407 0.333333 1.0
1 1.000000 0.938602 0.583333 1.0
2 1.000000 0.979287 1.000000 1.0
3 0.833333 0.972230 1.000000 1.0
4 1.000000 0.832040 1.000000 1.0
5 1.000000 0.968260 1.000000 1.0
6 0.666667 0.981793 1.000000 1.0
7 1.000000 0.975897 1.000000 1.0
8 1.000000 0.755073 1.000000 1.0
9 1.000000 0.845799 1.000000 1.0