1.RAG 的评估
RAG(Retrieval-Augmented Generation)是结合检索和生成的自然语言处理技术。在 RAG 模型中,首先通过检索模块从外部知识库中提取相关文档,随后生成模块基于这些检索结果生成自然语言的回答。评估 RAG 系统的性能主要涉及两个方面:检索的质量和生成的质量。以下是一些常见的评估方法。
2.检索模块的评估
RAG 模型的检索模块通常使用信息检索技术,如 基于深度学习的向量检索模型(如 Faiss)。检索模块的目标是在大量的文档中找到与用户输入(query)最相关的文档。检索的好坏直接影响到生成模块的表现,因此对检索模块的评估至关重要。
2.1 精确度和召回率(Precision & Recall)
精确度(Precision):在检索到的文档中,正确相关的文档所占的比例。计算公式:

召回率(Recall):所有与用户查询相关的文档中,被成功检索到的比例。计算公式:
召回率(Recall)= 系统检索到的相关文件 / 系统所有相关的文件总数
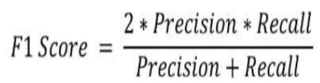
F1-score:精确度和召回率的调和平均数,常用于评估整体检索效果。计算公式:
2.2 排名质量(MRR)
Mean Reciprocal Rank (MRR) 是一种常用的评价指标,用于衡量信息检索系统、推荐系统或问答系统等任务中,系统返回的结果列表中正确答案的位置。MRR 特别适用于需要评估多个查询或任务的综合性能的情况。
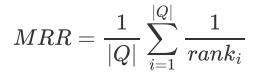
其中, 是第 ranki 个查询中第一个相关文档的排名,Q表示Q个查询。
计算步骤 1. 确定每个查询的第一个正确答案的位置:对于每个查询或任务,找到系统返回的结果列表中第一个正确答案的位置ranki。 2. 计算每个查询的倒数:计算每个查询的第一个正确答案位置的倒数1/ranki。 3. 求平均值:将所有查询的倒数求和,然后除以查询的数量|Q|。

解释: - MRR 越高,表示系统越能将正确答案排在前面。MRR 的取值范围是 ,其中 1 表示所有查询的第一个结果都是正确答案,0 表示没有任何查询的第一个结果是正确答案。 - MRR 对第一个正确答案的位置非常敏感。如果正确答案出现在较靠后的位置,MRR 的值会显著下降。
2.3平均准确率(MAP)
2.3.1 平均准确率(Average Precision, AP)
平均准确率(AP)用于评估单个查询的检索结果质量。它计算的是在每个相关文档出现的位置之前的平均准确率。
公式如下:

其中: - P(k)是第k个文档的准确率,即前 个文档中相关文档的比例。 - rel(k)是第k个文档是否相关的指示函数(相关为 1,不相关为 0)。
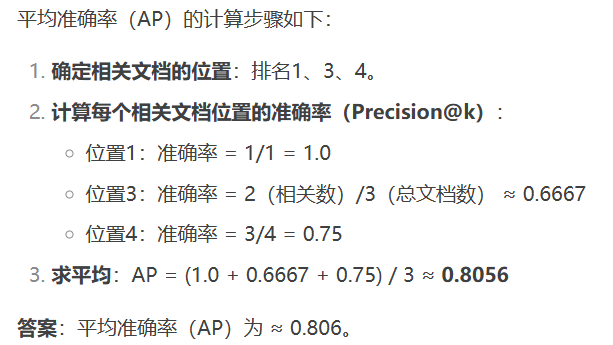
计算步骤 假设有一个查询,模型返回了 5 个文档,其中相关文档的分布如下:
| 排名 | 相关性 |
|---|---|
| 1 | 相关 |
| 2 | 不相关 |
| 3 | 相关 |
| 4 | 相关 |
| 5 | 不相关 |
2.3.2 平均平均准确率(Mean Average Precision, MAP)
平均平均准确率(MAP)是对多个查询的平均准确率的平均值。公式如下:


总结:
- AP:针对单个查询,计算在每个相关文档出现位置之前的平均准确率。
- MAP:针对多个查询,计算所有查询的 AP 的平均值。
3.生成模块的评估
生成模块的评估关注生成的文本是否准确、连贯且符合用户需求。常见的自动化评估指标如下:
- BLEU(Bilingual Evaluation Understudy):主要用于机器翻译,但也常用于生成任务。它通过比较生成文本与参考答案之间的词汇 n-gram 的匹配程度来评估生成文本的质量。BLEU 的分值在0 到 1 之间,分数越高表示生成文本与参考文本越接近。
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation):常用于摘要任务,主要评估生成文本与参考文本之间的重叠情况,主要关注召回率。常用的指标有 ROUGE-N(n-gram 匹配)、ROUGE-L(最长公共子序列匹配)等。
4.更直观的评估指标
通常我们会对以下 4 种类型的 RAG 评估感兴趣:
- 响应与参考答案:衡量RAG 答案相对于真实答案的相似/正确程度。是否回答准确。
- 响应与输入:衡量生成的响应与初始用户输入的相关程度,是否回答准确。
- 响应与检索到的文档:衡量生成的响应与检索到的文档相关性。是否检索正确。
- 检索到的文档与输入:衡量我检索到的文档与查询的相关性。是否检索正确。