1.向量相似度计算
当计算两个向量的相似度时,常见的方法包括余弦相似度、内积和L2距离(欧几里得距离)。下面是每个方法的公式和示例计算。
1.1余弦相似度
向量a是[1,2,3],向量b是[4,5,6],计算a和b的余玄相似度计算过程如下:

1.2 内积(Dot Product)
向量a是[1,2,3],向量b是[4,5,6],计算a和b的内积相似度计算过程如下:

注意: 内积(点积)本身可以视为一种相似性度量,但它未归一化,因此受向量长度的影响(模长越大的向量,内积可能越大)。若需消除向量长度的影响,可用余弦相似度(如之前的问题),公式为:cosθ = (a·b) / (||a|| * ||b||) ,计算结果约为 0.9746,表示方向高度相似。
1.3 L2 距离(欧几里得距离)


总结:
- 余弦相似度 衡量两个向量的夹角相似度,值范围为 [−1, 1],值越大表示越相似。
- 内积 衡量两个向量的相似度,值越大表示越相似,但不考虑向量的大小。
- L2距离 衡量两个向量之间的“直线”距离,值越小表示越相似。
2.什么是向量数据库
向量数据库是一种专门用于存储和查询高维向量的数据库。随着机器学习和深度学习技术的发展,向量表示(如词向量、图像特征、用户行为向量等)变得越来越重要。这些向量通常是多维的,表示数据的特征和属性。在这样的背景下,向量数据库提供了高效的存储、检索和相似度搜索功能。向量数据库其实和其他数据库差不多,只不过它存的是向量。
一般使用向量数据库的流程是:创建数据库->创建集合->创建索引->插入数据->搜索。
3.常见的向量数据库
3.1 Pinecone
专为构建和运行向量数据库而设计,提供简单易用的API。支持高效的相似性搜索和实时数据更新。提供管理和监控功能,易于扩展。注册Pinecone获取api key安装 Pinecone。
打开官网: https://app.pinecone.io
注册登录,这里直接使用github账号登录:
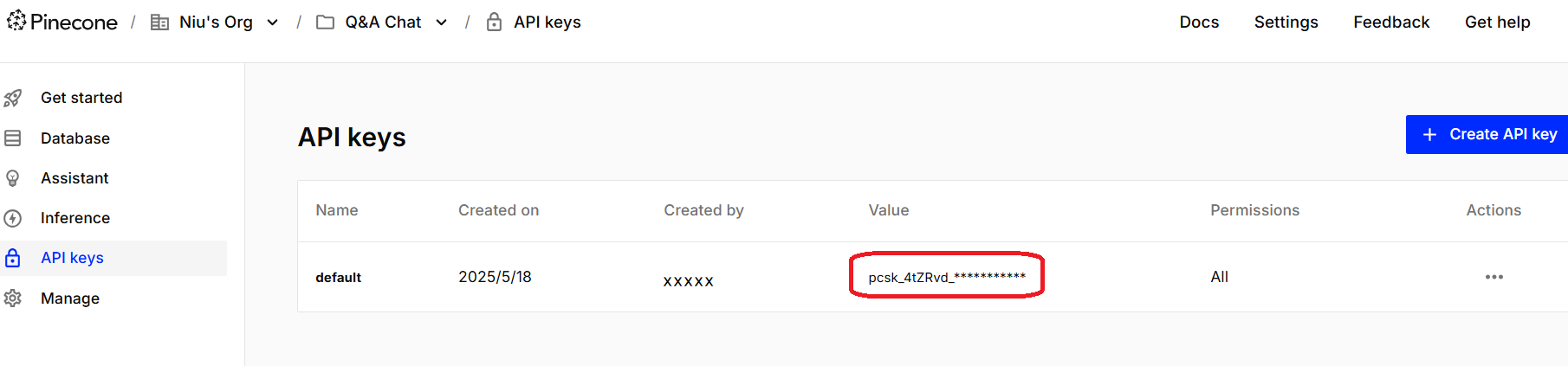
获取api key:
安装依赖:
pip install pinecone==5.4.1
初始化客户端:
# 初始化客户端
pc = Pinecone(api_key="sk-4a646aa7-de8d-461e-ac3f-xxxxxxxxxxx")
Pinecone向量相似度案例:
from sentence_transformers import SentenceTransformer
# 加载embedding模型
model = SentenceTransformer("models/AI-ModelScope/bge-large-zh-v1___5")
# 设置输入文本
texts = ["院子里有一只可爱的小猫", "厨房里有一只黑色的猫", "大模型真简单"]
# 向量化, embeddings是一个2D的数组,形状(3, 1024),3表示3句话,1024是每句话转成的向量
embeddings = model.encode(texts)
print(embeddings.shape)
# 假设我们想查询:"黑色的猫在哪?"
query_embedding = model.encode(["黑色的猫在哪?"])
from pinecone import Pinecone, ServerlessSpec
# 初始化Pinecone数据库
pc = Pinecone(api_key="pcsk_4tZRvd_F3agmaXGiPd33AR1xKmxJh1gowpWjDG7SDJeQ7fKkFbJZuyqysFBEf6BY5ztMh7")
index_name = "example"
# 创建数据库(创建时打开,其他时候注释)
"""
pc.create_index(
name=index_name,
dimension=1024,
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
),
metric="cosine"
)
"""
# # 向索引中插入向量(创建或者插入的时候打开,其他时候注释,查询的时候注释)
"""
index = pc.Index(index_name)
index.upsert(
vectors=[
{"id": "vec1", "values": embeddings[0].tolist()},
{"id": "vec2", "values": embeddings[1].tolist()},
{"id": "vec3", "values": embeddings[2].tolist()},
]
)
"""
# # 查询
# # 获取数据库的索引对象
index = pc.Index(index_name)
# # 查询相似向量
query_results = index.query(
top_k=3, # 返回前几个最相关的
vector=query_embedding[0].tolist(),
include_values=False # 包含返回向量的实际值
)
# # 打印返回结果
print(query_results)
# 删除example
#pc.delete_index(index_name)
运行效果:
(3, 1024)
{'matches': [{'id': 'vec2', 'score': 0.669890463, 'values': []},
{'id': 'vec1', 'score': 0.450800836, 'values': []},
{'id': 'vec3', 'score': 0.089593038, 'values': []}],
'namespace': '',
'usage': {'read_units': 5}}
当我们问:"黑色的猫在哪?",返回的vec2得分最高0.669890463,说明这个向量最匹配问题的答案。
查询结果解释:
查询结果是一个字典,包含以下键: - matches : 匹配的结果列表。每个匹配项是一个字典,包含以下键: - id : 向量的唯一标识符。 - score : 相似度分数(余弦相似度)。 - values : 向量的实际值(在本例中为空列表,因为设置了include_values=False )。 - namespace : 命名空间(默认为空字符串)。 - usage : 使用情况统计信息。 - read_units : 读取单元的数量。
3.2 FAISS (Facebook AI Similarity Search)
一个开源库,专门用于高效的相似性搜索。支持多种索引结构,适合处理非常大的数据集。具有强大的性能优化,能够在CPU和GPU上运行。
安装依赖:
pip install faiss-cpu==1.9.0
创建索引: 创建一个 Faiss 索引,并将句子的嵌入向量添加进去,通过faiss.write_index可以将向量持久化到本地上。持久化是指将数据保存到非易失性存储介质上的过程,以便在程序关闭后仍然能够保留这些数据。这样在运行代码后,在你指定的位置会新建一个faiss_index.index文件。
Faiss 向量相似度案例:
from sentence_transformers import SentenceTransformer
# 加载embedding模型
model = SentenceTransformer("models/AI-ModelScope/bge-large-zh-v1___5")
# 设置输入文本
texts = ["院子里有一只可爱的小猫", "厨房里有一只黑色的猫", "大模型真简单"]
# 向量化, embeddings是一个2D的数组,形状(3, 1024),3表示3句话,1024是每句话转成的向量
embeddings = model.encode(texts)
# print(embeddings.shape)
# 假设我们想查询:"黑色的猫在哪?"
query_embedding = model.encode(["黑色的猫在哪?"])
# FAISS向量数据库
import faiss
import numpy as np
# 转换为numpy数组
embeddings = np.array(embeddings)
# 初始化FAISS索引
index = faiss.IndexFlatIP(1024) # 使用内积进行检索, 把内积做了标准化,于是结果等于余弦相似度
# index = faiss.IndexFlatL2(1024) # 使用L2距离检索
# 将向量添加到索引
index.add(embeddings)
# 保存索引到磁盘
faiss.write_index(index, "db/faiss_index.index")
# 查询并检索,返回最相似的3个结果
D, I = index.search(query_embedding, k=3)
# 输出
print(f"最相似的句子索引:{I}")
print(f"对应的相似度/距离:{D}")
运行效果:
最相似的句子索引:[[1 0 2]]
对应的相似度/距离:[[0.6703383 0.45103025 0.08964229]]
标准化后的内积就是余弦相似度如何理解:
faiss.IndexFlatIP 使用内积进行相似度计算,其背后的原因是,内积在某些情况下可以与余弦相似度等价。如果你将向量进行标准化,即每个向量除以其欧几里得范数,那么内积结果就相当于计算了它们之间的余弦相似度。也就是说,标准化后的内积和余弦相似度是相等的。
3.3 Chroma
Chroma提供易于使用的API,特别适合构建和使用向量数据库。支持多种向量存储后端,具有良好的扩展性。适用于文本、图像等多种类型的数据。
安装Chroma:
pip install chromadb==0.5.20
Chroma向量相似度案例:
from sentence_transformers import SentenceTransformer
# 加载embedding模型
model = SentenceTransformer("models/AI-ModelScope/bge-large-zh-v1___5")
# 设置输入文本
texts = ["院子里有一只可爱的小猫", "厨房里有一只黑色的猫", "大模型真简单"]
# 向量化, embeddings是一个2D的数组,形状(3, 1024),3表示3句话,1024是每句话转成的向量
embeddings = model.encode(texts)
# print(embeddings.shape)
# 假设我们想查询:"黑色的猫在哪?"
query_embedding = model.encode(["黑色的猫在哪?"])
# 初始化Chroma
from chromadb import Client, PersistentClient
client = Client()
# 持久化
# client = PersistentClient(path="db")
# 创建集合,hnsw:图索引 space:距离度量空间
collection = client.create_collection("example_collection", metadata={"hnsw:space": "cosine"})
# 插入向量
collection.add(
ids=["vec0", "vec1", "vec2"],
embeddings=embeddings
)
# 查询
results = collection.query(
query_embeddings=query_embedding,
n_results=3
)
print(f"最相似的句子索引: {results['ids']}")
print(f"对应的相似度/距离: {[1-d for d in results['distances'][0]]}")
运行效果:
最相似的句子索引: [['vec1', 'vec0', 'vec2']]
对应的相似度/距离: [0.6703382134437561, 0.45103007555007935, 0.0896422266960144]
3.4 Milvus
Milvus 是一款云原生向量数据库,它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。
安装 Milvus:
设置工作目录和配置文件,在创建启动容器之前,我们要先设置好工作目录和配置文件。新建 milvus 后在milvus文件夹下新建以下文件夹。

下载 docker-compose.yml ,v2.4.13是版本。将 docker-compose.yml 复制到刚刚新建的 milvus 文件夹中。
wget https://github.com/milvusio/milvus/releases/download/v2.4.13/milvus-standalone-dockercompose.yml -O docker-compose.yml
使用 Docker 部署 Milvus,在 milvus 文件夹中打开终端,运行以下命令:
docker-compose up -d
运行效果:
(langchain_env) E:\langchain_project\vector_database\milvus>docker-compose up -d
time="2025-05-18T22:28:02+08:00" level=warning msg="E:\\langchain_project\\vector_database\\milvus\\docker-compose.yml: the attribute `version` is obsolete, it will be ignored, please
remove it to avoid potential confusion"
[+] Running 22/22
✔ minio Pulled 360.8s
✔ standalone Pulled 1442.6s
✔ etcd Pulled 207.1s
[+] Running 4/4
✔ Network milvus Created 0.0s
✔ Container milvus-etcd Started 1.0s
✔ Container milvus-minio Started 1.1s
✔ Container milvus-standalone Started
打开Docker Desktop,从下面信息可以看出,这个Docker环境中有四个正在运行的容器,分别与Milvus数据库服务、Etcd键值存储服务、MinIO对象存储服务相关联。“standalone”指的是一个独立运行的Milvus实例。

安装可视化界面(可选)
进入官网: https://github.com/zilliztech/attu/releases 下载安装
通过python使用Milvus:
安装依赖:
pip install pymilvus==2.5.0
milvus向量相似度案例:
from sentence_transformers import SentenceTransformer
# 加载embedding模型
model = SentenceTransformer("models/AI-ModelScope/bge-large-zh-v1___5")
# 设置输入文本
texts = ["院子里有一只可爱的小猫", "厨房里有一只黑色的猫", "大模型真简单"]
# 向量化, embeddings是一个2D的数组,形状(3, 1024),3表示3句话,1024是每句话转成的向量
embeddings = model.encode(texts)
# print(embeddings.shape)
# 假设我们想查询:"黑色的猫在哪?"
query_embedding = model.encode(["黑色的猫在哪?"])
"""1.创建数据库"""
"""
from pymilvus import connections, db
conn = connections.connect(host="127.0.0.1", port=19530)
database = db.create_database("sample_db")
"""
"""2.创建collection集合和索引"""
"""
from pymilvus import CollectionSchema, FieldSchema, DataType
from pymilvus import connections, db, Collection
# # 链接到milvus服务
conn = connections.connect(host="127.0.0.1", port=19530)
# # 使用一个名为sample_db数据库
db.using_database("sample_db")
# # 定义主键的字段"id", 类型是INT64, is_primary设置主键, auto_id开启自动增长
id = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True)
# # 定义embedding字段
embedding = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1024)
# # 创建集合模式,包含id 和 embedding ,可供描述信息
schema = CollectionSchema(
fields=[id, embedding],
description="Test"
)
# # 定义集合的名称为"example"
collection_name = "example"
collection = Collection(name=collection_name, schema=schema)
###创建索引
from pymilvus import connections, db, Collection, utility
# # 链接到milvus服务
conn = connections.connect(host="127.0.0.1", port=19530)
# # 使用一个名为sample_db数据库
db.using_database("sample_db")
# # 定义索引参数,度量类型:余弦相似度
index_param = {"metric_type": "COSINE"}
# # 获取名为example的集合
collection = Collection("example")
# # 在名为"embedding"的字段上创建索引,参数为index_param
collection.create_index(
field_name="embedding",
index_params=index_param
)
# # 获取创建 的进度
utility.index_building_progress("example")
"""
# """3.插入数据"""
"""
from pymilvus import connections, db, Collection
# # 链接到milvus服务
conn = connections.connect(host="127.0.0.1", port=19530)
# # 使用一个名为sample_db数据库
db.using_database("sample_db")
# # 获取名为example的集合
collection = Collection("example")
# # 插入数据
mr = collection.insert([embeddings])
print(mr)
"""
"""4.向量搜索"""
from pymilvus import connections, db, Collection
# 链接到milvus服务
conn = connections.connect(host="127.0.0.1", port=19530)
# 使用一个名为sample_db数据库
db.using_database("sample_db")
# 获取名为example的集合
collection = Collection("example")
# 将集合加载到内存中,以便进行搜索
collection.load()
# 定义搜索参数
search_param = {"metric_type": "COSINE"}
# 执行搜索
results = collection.search(
data=query_embedding.tolist(), # 查询的向量
anns_field="embedding", # 要查询的字段
param=search_param, # 搜索参数
limit=3, # 返回最多的结果数量
expr=None # 过滤表达式,None表示不过滤
)
print(results)
创建索引时还可以设定以下参数用于设定索引方式:
- FLAT:准确率高, 适合数据量小,暴力求解相似。
- IVF-FLAT:量化操作, 准确率和速度的平衡
- IVF: inverted file 先对空间的点进行聚类,查询时先比较聚类中心距离,再找到
- 最近的N个点。
- IVF-SQ8:量化操作,disk cpu GPU 友好
- SQ8:对向量做标量量化,浮点数表示转为int型表示,4字节->1字节。
- IVF-PQ:快速,但是准确率降低,把向量切分成m段,对每段进行聚类;查询
- 时,查询向量分端后与聚类中心计算距离,各段相加后即为最终距离。使用对称
- 距离(聚类中心之前的距离)不需要计算直接查表,但是误差回更大一些。
- HNSW:基于图的索引,高效搜索场景,构建多层的NSW。
- ANNOY:基于树的索引,高召回率。
metric_type 包括 "IP" 内积、"COSINE" 余弦相似度、"L2" L2距离。
运行效果:
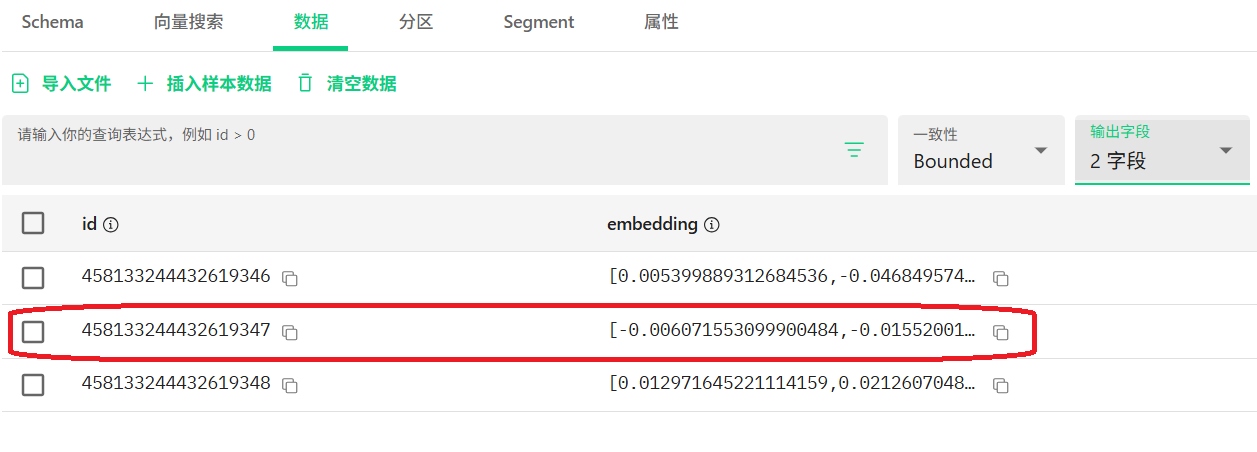
data: ["['id: 458133244432619347, distance: 0.6703382730484009, entity: {}', 'id: 458133244432619346, distance: 0.4510301947593689, entity: {}', 'id: 458133244432619348, distance: 0.08964231610298157, entity: {}']"]