基于FastAPI构建聊天机器人
基于FastAPI构建聊天机器人
1.基于FastAPI构建聊天机器人
以下是一个基于 FastAPI 框架的简单对话机器人示例,结合了OpenAI的API,用于处理用户的输入并生成对话。
首先我们需要一个可以进行模型对话的api,这里使用之前学过的vllm封装方式。启动vllm大模型,vllm推理服务器启动命令如下:
start_vllm.sh
python -m vllm.entrypoints.openai.api_server --port 10222 --model /root/autodl-tmp/DeployModelDemo/models/Qwen/Qwen2___5-0___5B-Instruct --served-model-name Qwen2___5-0___5B-Instruct &
实现代码:
from fastapi import FastAPI, Body
from openai import AsyncOpenAI
from typing import List
from fastapi.responses import StreamingResponse
# 初始化FastAPI应用
app = FastAPI()
# 初始化openai的客户端
api_key = "EMPTY"
base_url = "http://127.0.0.1:10222/v1"
aclient = AsyncOpenAI(api_key=api_key, base_url=base_url)
# 初始化对话列表
messages = []
# 定义路由,实现接口对接
@app.post("/chat")
async def chat(
query: str = Body(..., description="用户输入"),
sys_prompt: str = Body("你是一个有用的助手。", description="系统提示词"),
history: List = Body([], description="历史对话"),
history_len: int = Body(1, description="保留历史对话的轮数"),
temperature: float = Body(0.5, description="LLM采样温度"),
top_p: float = Body(0.5, description="LLM采样概率"),
max_tokens: int = Body(None, description="LLM最大token数量")
):
global messages
# 控制历史记录长度
if history_len > 0:
history = history[-2 * history_len:]
# 清空消息列表
messages.clear()
messages.append({"role": "system", "content": sys_prompt})
# 在message中添加历史记录
messages.extend(history)
# 在message中添加用户的prompt
messages.append({"role": "user", "content": query})
# 发送请求
response = await aclient.chat.completions.create(
model="Qwen2___5-0___5B-Instruct",
messages=messages,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
stream=True
)
# 响应流式输出并返回
async def generate_response():
async for chunk in response:
chunk_msg = chunk.choices[0].delta.content
if chunk_msg:
yield chunk_msg
# 流式的响应fastapi的客户端
return StreamingResponse(generate_response(), media_type="text/plain")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=6066, log_level="info")
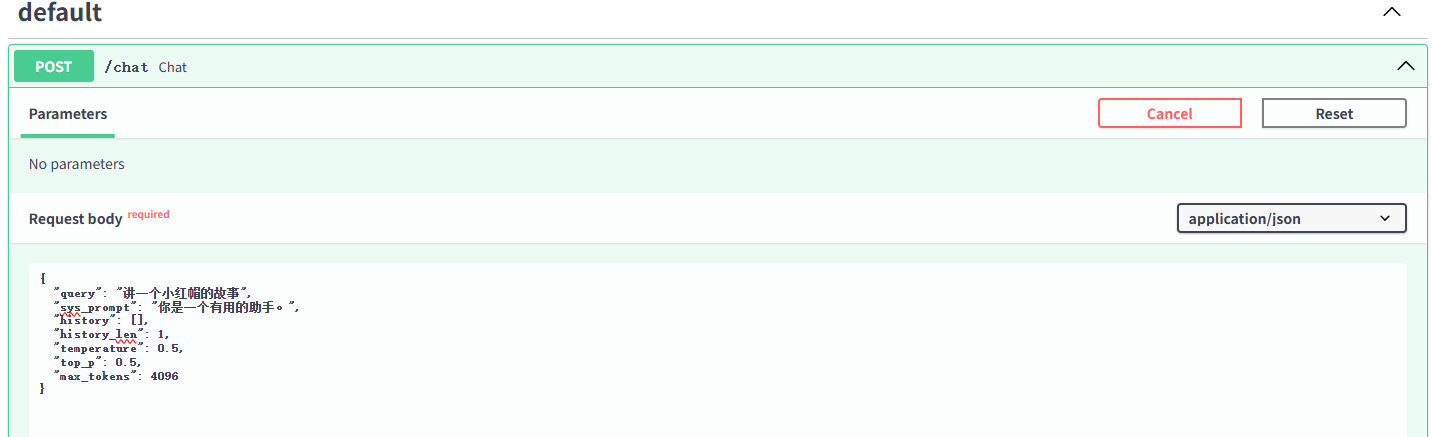
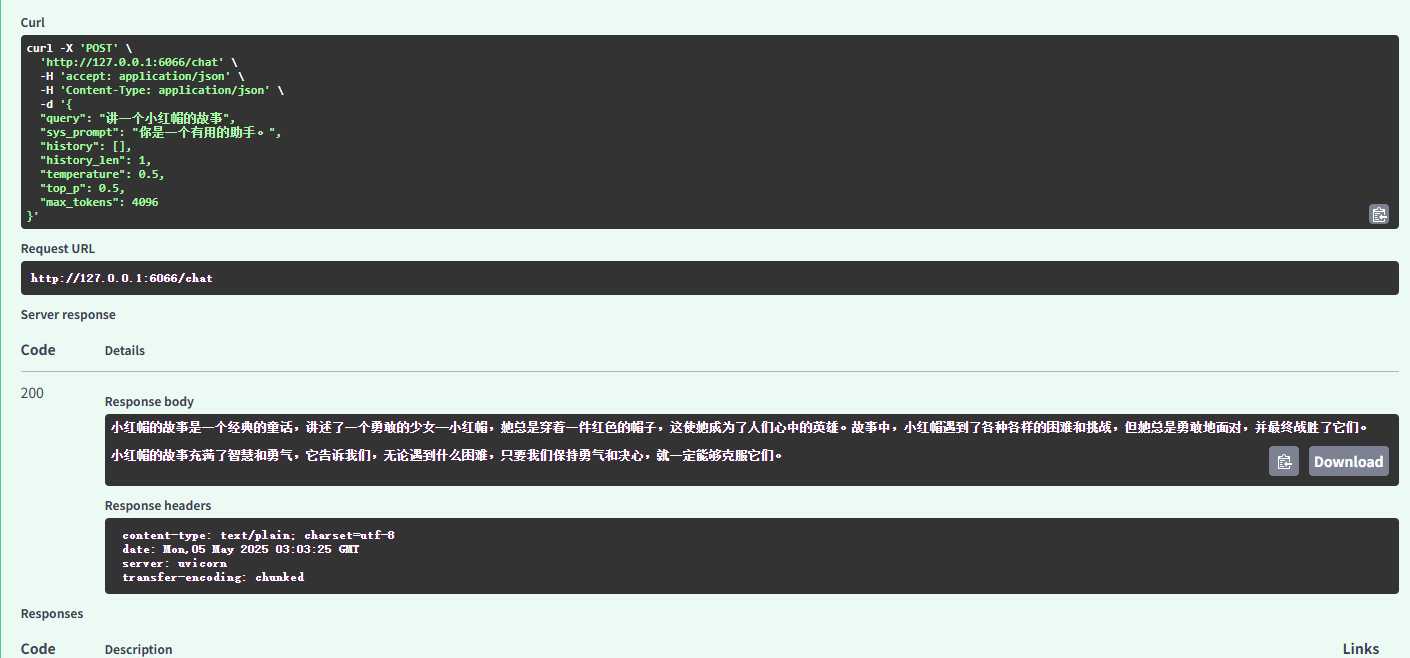
运行代码启动服务器,通过 http://127.0.0.1:6066/docs 可以进入自动生成的接口文档,在文档中可以测试api接口。