1.AutoDL简介
AutoDL平台是一个专注于提供云端GPU算力资源的租用平台,主要服务于需要进行大量计算任务的人工智能领域,尤其是深度学习模型的训练与推理。用户可以通过该平台租用不同配置的GPU服务器,这些服务器通常配备高性能的图形处理单元(GPU),例如NVIDIA的RTX系列显卡,适合执行并行计算密集型的任务。
AutoDL平台主要是为大模型的实战开发、生产部署提供了硬件(算力)和软件(模型、深度学习框架、工具等)上的支持。方便快速低成本的进行大模型相关领域的开发。
2.AutoDL算力云服务器基本使用
由于使用LlamaFactory进行大模型微调对电脑GPU的显存要求比较高,一般的笔记本电脑很难胜任大模型微调任务。因此我们需要租用AutoDL算力云服务器来完成微调任务。
以下示例基于 AutoDL 云计算资源。
在云计算平台选择可用的云计算资源实例,如果有3090实例可用,推荐选择3090实例(性价比更高)。同时注意镜像的选择,所以镜像会包含特定的环境,省去一些基础环境的安装步骤,不过这里镜像在实例启动之后也可以进行切换。
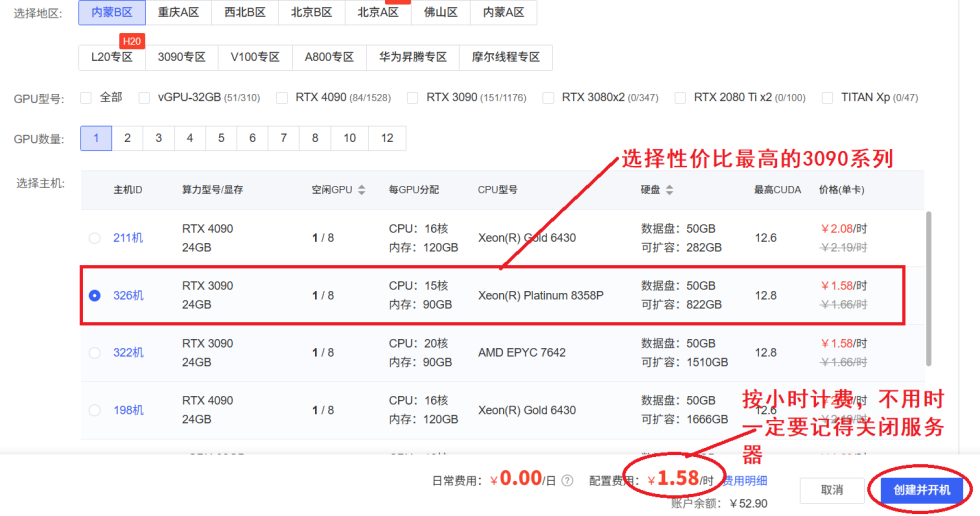
选择镜像环境。

创建实例之后,开机后,通过SSH连接远程服务器。

这里我使用 VS Code的 Remote-SSH 插件进行连接,连接进去之后可以看到实例中有两个盘,其中/root/autodl-tmp是数据盘,推荐运行环境、模型文件都放在数据盘,避免后续因为实例关机回收导致数据文件丢失。
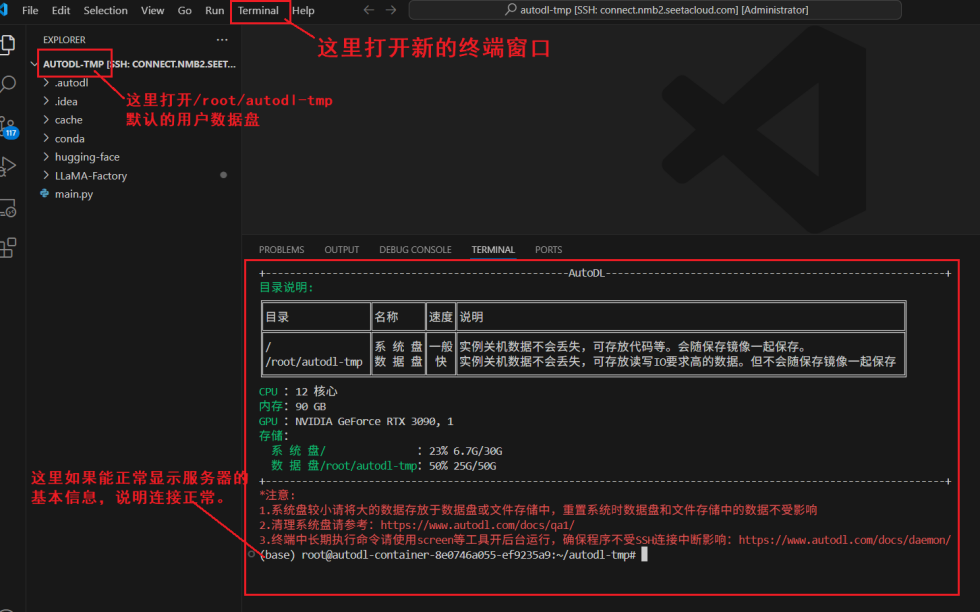
3. 创建新的conda环境和拉取镜像
创建新的虚拟环境:
# 创建新的虚拟环境
conda create --name AI_env python=3.11.9
# 激活虚拟环境
source ~/.bashrc
conda init
conda activate AI_env
安装必要依赖: 使用以下命令安装所需的依赖库,安装 pytorch gpu版本。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
安装 transformers:
pip install transformers==4.45.0
4.下载Qwen2.5-0.5B模型
为了加快下载速度,我们使用魔搭社区的下载方式。
pip install modelscope
下载模型:
from modelscope.hub.snapshot_download import snapshot_download
llm_model_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct',cache_dir='models')
Qwen/Qwen2.5-0.5B-Instruct为魔搭社区上的路径,models为本地路径。
5.模型推理
代码示例:
import torch
# 导入transformers库中的AutoModelForCausalLM(用于因果语言模型)和AutoTokenizer(自动化的分词工具)。
from transformers import AutoModelForCausalLM, AutoTokenizer
# 检查是否有可用的CUDA设备(即NVIDIA GPU),如果有,则设置为使用GPU,否则使用CPU。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 使用预训练模型Qwen2.5-0.5的分词器实例化tokenizer对象。
tokenizer = AutoTokenizer.from_pretrained("models/Qwen/Qwen2___5-0___5B-Instruct")
# 实例化一个预训练的因果语言模型,并将其移动到指定的device上执行。
model = AutoModelForCausalLM.from_pretrained("models/Qwen/Qwen2___5-0___5B-Instruct").to(device)
# 设置对话的提示词。
prompt = "给我讲个笑话。"
# 定义对话历史,包括系统信息(指示助手的角色)和用户输入的提示。
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
# 使用分词器将对话历史转换为适用于模型输入的格式,并添加生成提示。
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 对输入文本进行分词处理,并转换为PyTorch张量格式,然后移动到指定的device上执行。
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 使用模型生成新的token序列,最大生成新的token数量为512。
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
)
# 截取生成的token序列,去除原始输入的部分。
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 将生成的token序列解码回文本,并忽略特殊token。
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出生成的响应文本。
print(response)
运行效果:
cuda
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)
小明:你这人真是奇怪,总是问我答案。
老王:嘿嘿,我就是想问一下,你到底在干什么?
小明:我一直在搞这个。
老王:搞什么?是搞网络吗?还是搞人工智能?
小明:搞人工智能嘛,就是让机器能像人一样思考和决策。
老王:哦,那你说说看,你是怎么做到的?
小明:我用代码和算法来实现这些功能,然后通过各种方式让它执行。
老王:哇,你的技术真的很厉害啊!
小明:谢谢夸奖,我也觉得挺开心的。
如果我们运行的是Qwen2___5-7B-Instruct,这种参数量更大的模型,运行时会报以下错误:
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 260.00 MiB. GPU 0 has a total capacity of 23.68 GiB of which 190.69 MiB is free. Process 221644 has 23.49 GiB memory in use. Of the allocated memory 23.10 GiB is allocated by PyTorch, and 150.90 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
我们需要修改模型加载时的精度,修改代码如下:
model = AutoModelForCausalLM.from_pretrained("models/Qwen/Qwen2___5-7B-Instruct",torch_dtype=torch.float16).to(device)