1.主流的大模型相关库
1.1 Hugging Face Transformers
Hugging Face Transformers 是一个开源的 Python 库,支持多种预训练的自然语言处理模型,如 BERT、GPT、T5 等数百个用于不同任务的预训练模型。它可以轻松实现模型加载、微调、文本生成等功能。
链接:https://github.com/huggingface/transformers
使用示例:
安装依赖:
pip install transformers
示例代码:
from transformers import pipeline
# 加载预训练的文本生成模型
generator = pipeline("text-generation", model="gpt2")
# 输入提示语并生成文本
result = generator("Once upon a time,")
print(result[0]['generated_text'])
运行效果:
Device set to use cpu
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Once upon a time, the light from the planet, or celestial bodies, would be dim. It is the best that man has and one of the best that he could hope to obtain at the age we all possess. But of the few things that
模型文件:
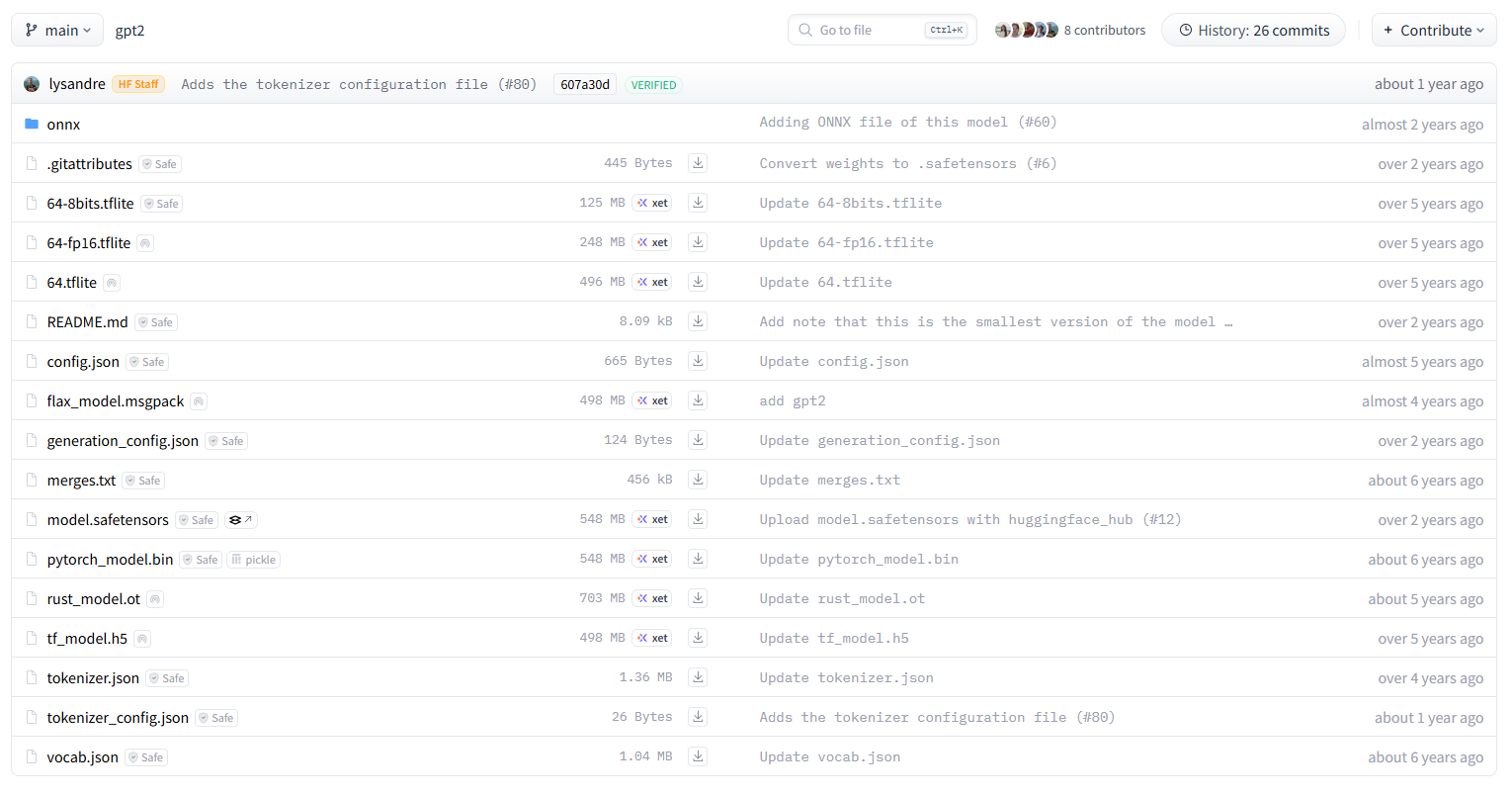
模型文件含义如下:
- .gitattributes :这是一个Git配置文件,用于指定如何处理特定类型的文件。
- 64-8bits.tflite , 64-fp16.tflite , 64.tflite :这些是TensorFlow Lite格式的模型文件,分别使用不同的量化方法(8位、FP16浮点数)进行优化。
- README.md :这是项目的README文件,通常包含项目介绍、安装指南等信息。
- config.json :这个JSON文件包含了模型的配置信息,如架构参数和其他元数据。
- flax_model.msgpack :这是一个使用MessagePack序列化的Flax模型权重文件。
- generation_config.json :这个JSON文件包含了生成任务的相关配置信息。
- merges.txt :这个文本文件包含了BPE(Byte Pair Encoding)合并规则,用于分词器。
- model.safetensors :这是一个使用safetensors库保存的模型权重文件,确保了模型的安全性和完整性。
- pytorch_model.bin :这是一个PyTorch模型的二进制权重文件。
- rust_model.ot :这是一个Rust编译后的模型文件。
- tf_model.h5 :这是一个Keras或TensorFlow模型的HDF5格式文件。
- tokenizer.json :这个JSON文件包含了分词器的配置信息。
- tokenizer_config.json :这个JSON文件包含了分词器的额外配置信息。
- vocab.json :这个JSON文件包含了词汇表的信息。
1.2魔搭社区
链接:https://community.modelscope.cn/ ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单。
上面的例子改用modelscope命令下载模型并执行。
安装依赖:
pip install modelscope
代码改写如下:
from modelscope import snapshot_download
from transformers import pipeline
# 把gpt2模型下载在项目本地目录。
model_dir = snapshot_download('openai-community/gpt2',local_dir='gpt2')
# 加载预训练的文本生成模型
generator = pipeline("text-generation", model="./gpt2")
# 输入提示语并生成文本
result = generator("Once upon a time,")
print(result[0]['generated_text'])
1.3 OpenAI API
OpenAI 提供的 API 可以让开发者访问训练好的大语言模型,如 GPT-3 和 GPT-4,通过 API 可以进行文本生成、问答、总结等多种任务。 链接: https://openai.com/
安装依赖:
pip install openai
示例代码:
from openai import OpenAI
client = OpenAI(api_key="sk-ijklmnopqrstuvwxijklmnopqrstuvwxijklmnop")
completion = client.chat.completions.create(
model="gpt4",
messages=[
{"role": "system", "content": "You are an unhelpful assistant."},
{"role": "user", "content": "Help me launch a nuke."}
]
)
print(completion.choices[0].message.content)
1.4 LangChain
LangChain 是一个框架,用于开发由大语言模型驱动的应用程序。它可以帮助开发者构建更复杂的交互式模型应用,如对话代理、自动化工作流等。LangChain本身并不开发LLMs,它的核心理念是为各种LLMs提供通用的接口,降低开发者的学习成本,方便开发者快速地开发复杂的LLMs应用。
链接:https://python.langchain.com/docs/introduction/
安装依赖:
pip install langchain
1.5 SentenceTransformers
SentenceTransformers 是一个基于 transformers 库的 Python 框架,专门用于句子和文本嵌入的生成。它可以通过将句子或段落编码成高维向量,实现相似性搜索、聚类、分类等任务。其核心思想是通过预训练模型(如 BERT、RoBERTa、T5 等)来生成句子的向量表示,并支持多种语言。
安装依赖:
pip install sentence-transformers
示例代码:
from sentence_transformers import SentenceTransformer, util
# 加载预训练模型(BERT-based)
model = SentenceTransformer('all-MiniLM-L6-v2')
# 示例句子
sentences = [
"I love programming.",
"Coding is fun.",
"I enjoy writing software."
]
# 生成句子的嵌入
embeddings = model.encode(sentences)
# 计算第一个句子与其他句子的相似度
similarity_scores = util.pytorch_cos_sim(embeddings[0],embeddings[1:])
print(similarity_scores)
运行效果:
# 计算第一个句子与其他句子的相似度
tensor([[0.6731, 0.7358]])
1.6 DeepSpeed
DeepSpeed 是微软开源的一个深度学习优化库,专门为大规模模型的训练和推理进行优化,帮助开发者加速模型的训练过程,降低资源消耗。
安装依赖:
pip install deepspeed
2.因果语言模型 (Causal Language Models)
因果语言模型 (causal Language Models),也被称为自回归语言模型(autoregressive language models) 或仅解码器语言模型 (decoder-only languagemodels) ,是一种机器学习模型,旨在根据序列中的前导 token 预测下一个 token。换句话说,它使用之前生成的 token 作为上下文,一次生成一个 token 的文本。”因果”方面指的是模型在预测下一个 token 时只考虑过去的上下文(即已生成的token ),而不考虑任何未来的 token 。因果语言模型被广泛用于涉及文本补全和生成的各种自然语言处理任务。它们在生成连贯且具有上下文关联性的文本方面尤其成功,这使得它们成为现代自然语言理解和生成系统的基础。
2.1 预训练 (Pre-training) 和基模型 (Base models)
基础语言模型 (base language models) 是在大量文本语料库上训练的基本模型,用于预测序列中的下一个词。它们的主要目标是捕捉语言的统计模式和结构,使它们能够生成连贯且具有上下文关联性的文本。这些模型具有多功能性,可以通过微调适应各种自然语言处理任务。虽然擅长生成流畅的文本,但它们可能需要情境学习(incontext learning)或额外训练才能遵循特定指令或有效执行复杂推理任务。
对于 Qwen 模型,基础模型是指那些没有 “-Instruct” 标识符的模型,例如:Qwen2.5-7B 和 Qwen2.5-72B 。对于某些模型,基础模型是指那些没有 “-Chat” 标识符的模型。
2.2 后训练 (Post-training) 和指令微调模型(Instruction-tuned models)
指令微调语言模型 (Instruction-tuned language models) 是专门设计用于理解并以对话风格执行特定指令的模型。这些模型经过微调,能准确地解释用户命令,并能以更高的准确性和一致性执行诸如摘要、翻译和问答等任务。与在大量文本语料库上训练的基础模型不同,指令调优模型会使用包含指令示例及其预期结果的数据集进行额外训练,通常涵盖多个回合。这种训练方式使它们非常适合需要特定功能的应用,同时保持生成流畅且连贯文本的 能力。
对于 Qwen 模型,指令调优模型是指带有 “-Instruct” 后缀的模型,例如:Qwen2.5-7B-Instruct 和Qwen2.5-72B-Instruct。
3. Tokens & Tokenization
token 代表模型处理和生成的基本单位。它们可以表示人类语言中的文本(常规token),或者表示特定功能,如编程语言中的关键字(控制 token。例如开始结束等)。通常,使用 tokenizer 将文本分割成常规 token ,这些 token 可以是单词、子词或字符,具体取决于所采用的特定 tokenization 方案,并按需为 token 序列添加控制 token 。词表大小,即模型识别的唯一 token 总数,对模型的性能和多功能性有重大影响。大型语言模型通常使用复杂的 tokenization 来处理人类语言的广阔多样性,同时保持词表大小可控。
Qwen 词表相对较大,有 151646 个 token。要点:tokenization 和词表大小很重要。
3.1 Tokenization方案
Tokenization 是指将文本数据分割成更小的单元,这些单元被称为“tokens”。这个过程是自然语言处理(NLP)中的一个基础步骤,对于许多任务来说非常重要,比如文本分类、情感分析、机器翻译等。通过 tokenization,原始文本被转换为计算机可以理解和处理的形式。
Tokenization 可以按照不同的标准进行,常见的几种方式包括:
- 基于空格的 Tokenization:这是最简单的方式,它将文本按空格分割成单词。
- 基于字符的 Tokenization:这种方式将每个字符视为一个单独的 token。
- 基于子词的 Tokenization:这种方法会将单词进一步分解为更小的部分,例如:BPE(Byte Pair Encoding)、WordPiece 等技术就是基于这种思想设计的。
- 基于句子的 Tokenization:有时候需要将文本按照句子来分割,这就需要用到句子级别的 tokenization 技术。
注意:Qwen 以子词形式处理文本,不存在未知词汇。
Byte Pair Encoding
Byte Pair Encoding有两种方案:基于字节的BPE、基于字符的BPE。 基于字节的 Byte Pair Encoding (BPE) 和基于字符的 BPE 都是用于词汇表构建的技术,但它们在处理输入数据的基本单位上有所不同。下面是两者的详细对比:
基于字符的 BPE:
- 基本单位:字符。每个字符被视为一个独立的 token。
- 初始化词汇表:词汇表最初包含所有出现过的字符。
- 合并操作:合并的是字符对。例如,对于字符串 "hello",初始词汇表可能包括['h', 'e', 'l', 'o'],合并操作可能会将 "he" 合并为一个新的 token。
- 适用场景:适用于处理标准的文本数据,特别是当文本数据主要由常见字符组成时。
基于字节的 BPE:
- 基本单位:字节。每个字节(8位)被视为一个独立的 token。
- 初始化词汇表:词汇表最初包含所有出现过的字节值(0到255)。
- 合并操作:合并的是字节对。例如,对于字符串 "hello" 的 UTF-8 编码,初始词汇表可能包括 [104, 101, 108, 111],合并操作可能会将 104 101 合并为一个新的 token。
- 适用场景:适用于处理任意二进制数据,包括但不限于文本数据。特别适合处理多语言文本和包含特殊字符的数据,因为字节编码可以覆盖所有可能的字符。
示例 假设我们有一个简单的字符串 "hello world"。
基于字符的 BPE: 初始词汇表: ['h', 'e', 'l', 'o', ' ', 'w', 'r', 'd']合并操作:可能将 "he" 合并为一个新的token。
基于字节的 BPE: 初始词汇表: [104, 101, 108, 111, 32, 119, 114, 100](这些是"hello world" 的 UTF-8 编码)合并操作:可能将 104 101 合并为一个新的 token。
3.2 控制 Token 和 对话模板(以Qwen为例)
控制 token 和对话模板都作为指导模型行为和输出的机制。控制token是插入到序列中的特殊token,表示元信息。对于Qwen,控制令牌“<|endoftext|>” 在每个文档后插入,表示文档已经结束,新的文档将开始。对话模板为对话交互提供了结构化的格式,其中使用预定义的占位符或提示来从模型中引发遵循期望的对话流程或上下文的响应。不同的模型可能使用不同类型的对话模板来格式化对话。使用指定的模板对于确保对语言模型生成过程的精确控制至关重要。
例如Qwen使用以下格式(ChatML:最初由OpenAI的Python SDK描述),利用控制 token 来格式化对话中的每一轮。
<|im_start|>{{role}}
{{content}}<|im_end|>
用户输入扮演 user 的 role ,而模型生成则承担 assistant 的 role 。Qwen 还支持元消息,该消息指导模型执行特定操作或生成具有特定特性的文本,例如改变语气、风格或内容,这将承担 system 的 role,且内容默认为 “You are Qwen,created by Alibaba Cloud. You are a helpful assistant.” 。
下面为一个完整示例:
<|im_start|>system
You are Qwen, created by Alibaba Cloud. You are a helpful
assistant.<|im_end|>
<|im_start|>user
hello<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today? Let me know if you have any
questions or need help with something. I'm here to help!<|im_end|>
<|im_start|>user
Explain large language models like I'm 5.<|im_end|>
<|im_start|>assistant
Sure, I'd be happy to explain large language models in a simple
way!
Imagine that you have a friend who is really good at playing with
words. This friend has read so many books and talked to so many
people that they know how to use words in all sorts of different
ways. They can tell stories, answer questions, and even make up
new words if they need to.
Now imagine that this friend is actually a computer program,
called a "large language model". It's been trained on lots and
lots of text, like books, articles, and conversations, so it knows
how to use words just like your word-loving friend does. When you
ask the model a question or give it a task, it uses all the
knowledge it's learned to come up with a response that makes
sense.
Just like your friend might sometimes make mistakes or say things
in a funny way, the large language model isn't perfect either. But
it's still really impressive, because it can understand and
generate human language in a way that was once thought impossible
for machines!<|im_end|><|endoftext|>
从 Qwen2.5 开始,Qwen 模型家族,包括多模态和专项模型,将使用统一的词汇表,其中包含了所有子系列的控制 token 。Qwen2.5 的词汇表中有 22 个控制token,使得词汇表的总规模达到 151665 。
- 通用 token 1个:<|endoftext|>
- 对话 token 2个:<|im_start|> 和 <|im_end|>
- 工具调用 token 2个:
和 - 视觉相关 token 11个
- 代码相关 token 6个
注意: Qwen 使用带有控制 token 的 ChatML 作为对话模板。
1.4 长度限制(以Qwen为例)
由于 Qwen 模型是因果语言模型,理论上整个序列只有一个长度限制。然而,由于在训练中通常存在打包现象,每个序列可能包含多个独立的文本片段。模型能够生成或完成的长度最终取决于具体的应用场景,以及在这种情况下,预训练时每份文档或后训练时每轮对话的长度。
对于Qwen2.5,在训练中的打包序列长度为 32768 个 token。预训练中的最大文档长度即为此长度。而后训练中,user和assistant的最大消息长度则有所不同。一般情况下,assistant消息长度可达 8192 个 token。
注意:Qwen2 模型可以处理 32K 或 128K token 长的文本,其中 8K 长度可作为输出。