1.硅基流动简介
硅基流动(SiliconCloud)是硅基流动公司推出的一站式大模型云服务平台,致力于为开发者和企业提供高效、低成本且全面的生成式人工智能(GenAI)模型服务,包括 IaaS、PaaS 和 MaaS。其核心目标是通过优化大模型使用体验,帮助用户实现 “Token 自由”,即以更低成本和更高效率使用先进的大语言模型(LLMs)及其他生成式人工智能(AI)模型。
硅基流动提供了一系列高效、低成本的AI解决方案,主要包括:
- SiliconCloud:一个基于优秀开源基础模型的云服务平台,支持多种主流大语言模型(如Qwen、DeepSeek、GLM、Yi、Mistral、LLaMA 3等)和图像生成模型(如SDXL、InstantID等)的API调用。与其他平台不同,SiliconCloud不仅提供自家模型接口,还聚合了多种开源模型,具备高性价比和灵活性,适用于开发者测试和企业应用。
- SiliconLLM:一款低时延、高吞吐的大语言模型推理引擎,优化了复杂自然语言处理任务的性能。
- OneDiff:高性能的文生图和视频生成加速库,支持快速图像和视频生成,广泛应用于创意设计和内容生产。
2.使用大模型api接口
1.1获取 API 密钥
前往想要调用的大模型厂商的官网注册登录申请 api key,查看调用文档记录base_url 和 api_key。 以硅基流动举例,网站:https://docs.siliconflow.cn/quickstart(该网站送14元,并且有免费模型,后续如果收费的话可以酌情操作),根据快速上手获取API。其它网站都差不多,例如百度的千帆。在模型广场中找“只看免费”的,这里可以看到Qwen2.5-7B是免费的。
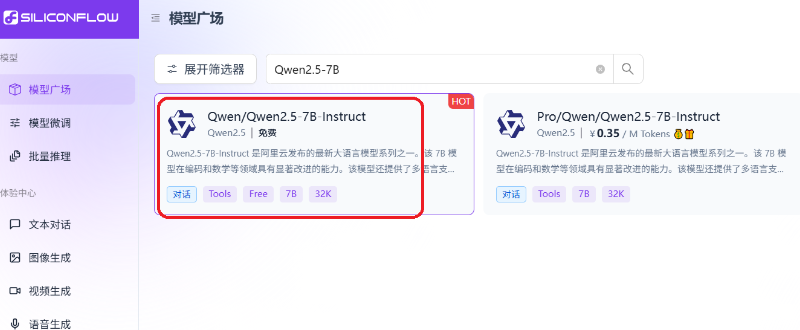
申请一个秘钥:
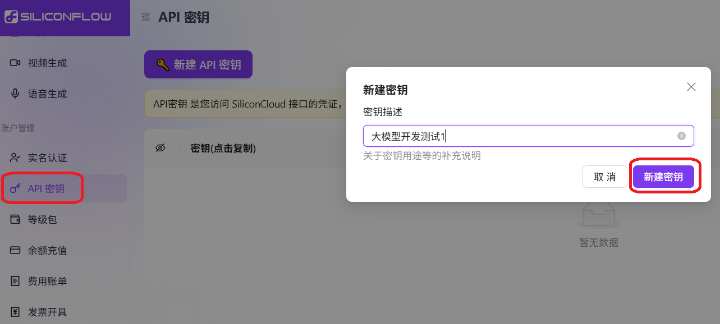
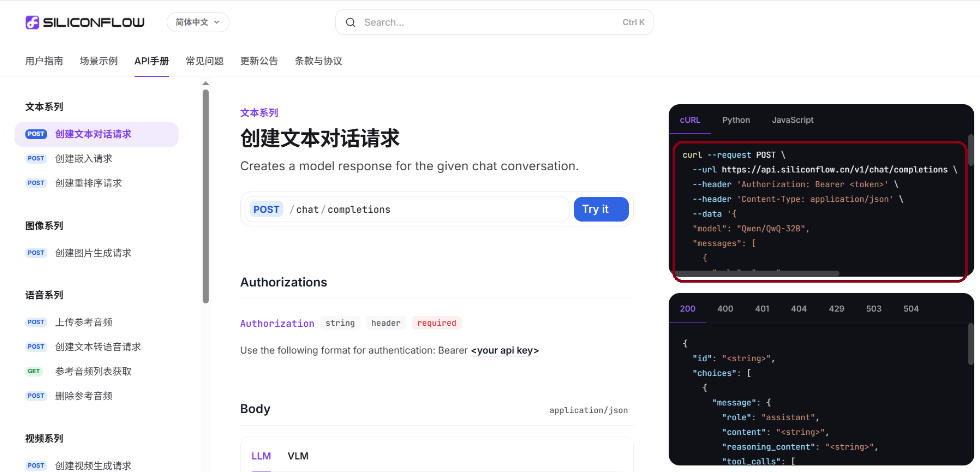
同时可以查看API手册以获取自己想要对接的功能:
1.2 发起API请求
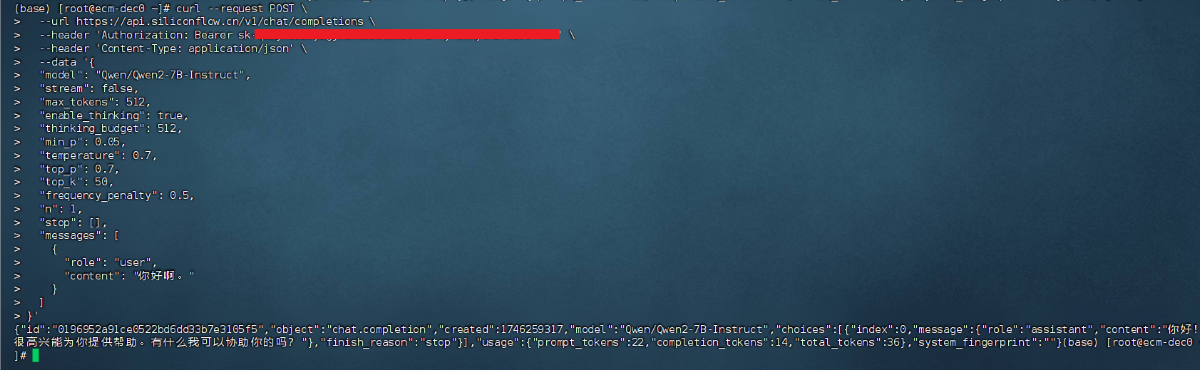
使用Linux的的terminal运行以下命令:
curl --request POST \
--url https://api.siliconflow.cn/v1/chat/completions \
--header 'Authorization: Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' \
--header 'Content-Type: application/json' \
--data '{
"model": "Qwen/Qwen2-7B-Instruct",
"stream": false,
"max_tokens": 512,
"enable_thinking": true,
"thinking_budget": 512,
"min_p": 0.05,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"stop": [],
"messages": [
{
"role": "user",
"content": "你好啊。"
}
]
}'
注意:header 参数替换为自己APK-KEY。运行效果如下:
1.3 使用request请求
安装依赖:
pip install requests
示例代码:
import requests
url = "https://api.siliconflow.cn/v1/chat/completions"
payload = {
"model": "Qwen/Qwen2-7B-Instruct",
"stream": False,
"max_tokens": 512,
"enable_thinking": True,
"thinking_budget": 512,
"min_p": 0.05,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"stop": [],
"messages": [
{
"role": "user",
"content": "请介绍一下你自己。"
}
]
}
headers = {
"Authorization": "Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"Content-Type": "application/json"
}
response = requests.request("POST", url, json=payload, headers=headers)
print(response.text)
运行效果:
{"id":"0196953487a24998a0699509694bc7e2","object":"chat.completion","created":1746259969,"model":"Qwen/Qwen2-7B-Instruct","choices":[{"index":0,"message":{"role":"assistant","content":"我是一个大模型,我叫通义千问。我是阿里云推出的一种超大规模语言模型,能够回答问题、创作文字,还能表达观点、撰写代码。我是在海量的互联网文本上进行训练得到的,所以可以生成各种主题的高质量文本。同时,我也经过了多轮调优和优化,以提供更准确、流畅的回答。如果您有任何问题或需要帮助,请随时告诉我,我会尽力提供支持。"},"finish_reason":"stop"}],"usage":{"prompt_tokens":23,"completion_tokens":92,"total_tokens":115},"system_fingerprint":""}
1.4 使用openai接口请求
安装依赖:
pip install openai==1.77.0
示例代码:
# 使用openai接口请求
from openai import OpenAI
api_key = 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
base_url = 'https://api.siliconflow.cn/v1'
client = OpenAI(api_key=api_key, base_url=base_url)
# # 发送请求到GPT模型, 流式输出
# response = client.chat.completions.create(
# model='Qwen/Qwen2.5-7B-Instruct', # 使用的模型,可以选择gpt-3.5-turbo等
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "你好"},
# ],
# max_tokens=150, # 返回文本的最大长度
# temperature=0.7, # 控制生成文本的随机性,值越低,输出越确定
# stream=True
# )
# # 逐块打印返回结果
# for chunk in response:
# print(chunk)
# 发送请求到GPT模型, 非流式输出
response = client.chat.completions.create(
model='Qwen/Qwen2.5-7B-Instruct', # 使用的模型,可以选择gpt-3.5-turbo等
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "请介绍一下你自己"},
],
max_tokens=150, # 返回文本的最大长度
temperature=0.7, # 控制生成文本的随机性,值越低,输出越确定
stream=False
)
print(response)
运行效果:
ChatCompletion(id='0196953a5732e802d971c2b5e057c10c', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='我叫通义千问,是阿里云推出的一种超大规模语言模型。作为一个AI助手,我的目标是帮助用户获得准确、有用的信息,解决他们的问题和困惑。无论是提供知识解答、撰写文章,还是进行创意头脑风暴,我都希望可以成为您的得力助手。如果您有任何问题或需要帮助,请随时告诉我,我会尽力提供支持。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None))], created=1746260350, model='Qwen/Qwen2.5-7B-Instruct', object='chat.completion', service_tier=None, system_fingerprint='', usage=CompletionUsage(completion_tokens=76, prompt_tokens=22, total_tokens=98, completion_tokens_details=None, prompt_tokens_details=None))
使用 OpenAI 接口时,可以通过不同的参数来调整生成的结果: - model: 指定使用的模型。 - messages: 数组类型,必填项。包含对话历史描述的消息列表。 - role 字符串类型,必填项。该消息作者的角色。可选值为 system、user 或assistant。content 字符串类型,必填项。消息的内容。 - max_tokens: 控制输出文本的最大长度(token 是单位,包括单词和标点符号)。 - temperature: 控制生成文本的创造性或随机性。较高的值(如 0.8)会使输出更加随机,较低的值(如 0.2)会使输出更确定。 - top_p: 数字类型,可选。默认为 1。一种称为“核心采样”的采样替代方法,其中模型考虑概率质量值在前 top_p 的标记的结果。因此,0.1 意味着仅考虑概率质量值前 10% 的标记。 - stream: 布尔类型,流式输出,可选。默认为 false。 - n: 整数类型,可选。默认为 1。要生成的每个输入消息的聊天完成选项数量。 - stop: 字符串或数组类型,可选。默认为 null。API 最多将生成 4 个序列,这些序列将停止生成更多标记。 - presence_penalty: 数字类型,可选。默认为 0。介于 -2.0 和 2.0 之间的数字。正值会根据新标记在迄今为止的文本中出现的频率惩罚新标记,增加模型谈论新话题的可能性。 - frequency_penalty: 数字类型,可选。默认为 0。范围在 -2.0 到 2.0 之间的数字。正值会根据其在文本中的现有频率惩罚新标记,从而减少模型重复同一行的可能性。 - logit_bias: Map 类型,可选。默认为 null。修改出现在完成中的指定标记的可能性。 - user: 字符串类型,可选。表示您的最终用户的唯一标识符,可帮助 OpenAI 监视和检测滥用。
解析响应 返回的响应是一个 JSON 格式的数据,其中包含生成的文本。主要结构如下: - choices: 返回生成的文本列表,每个元素对应一个生成的响应。 - usage: 显示请求消耗的 token 数量,包括输入和输出。