1.大模型基础-前向与反向
由于大模型也属于深度学习,所以遵循2012年开始的深度学习的基本法则!那就是前向过程与反向过程。
前向过程如下图所示:
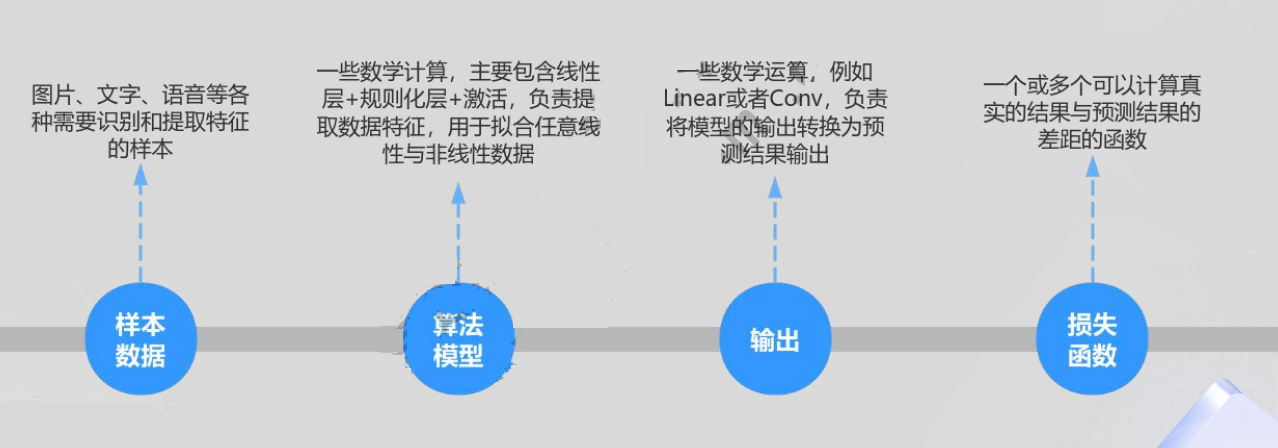
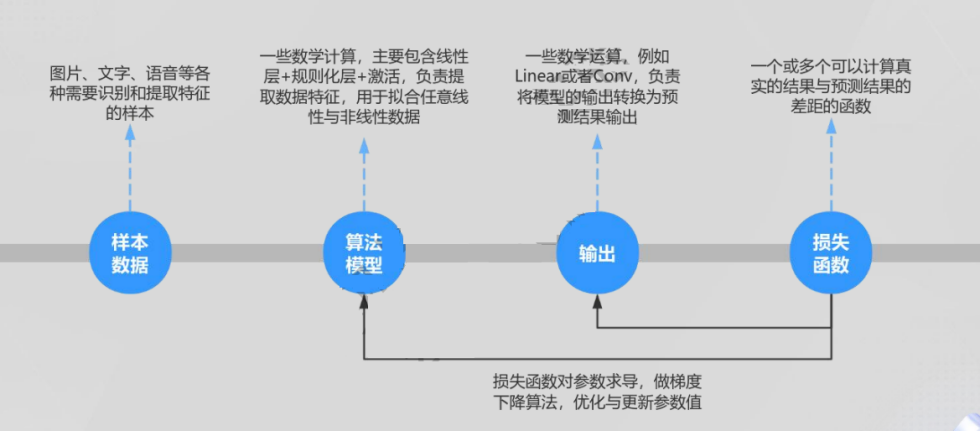
反向过程如下图所示:
预测过程如下图所示:
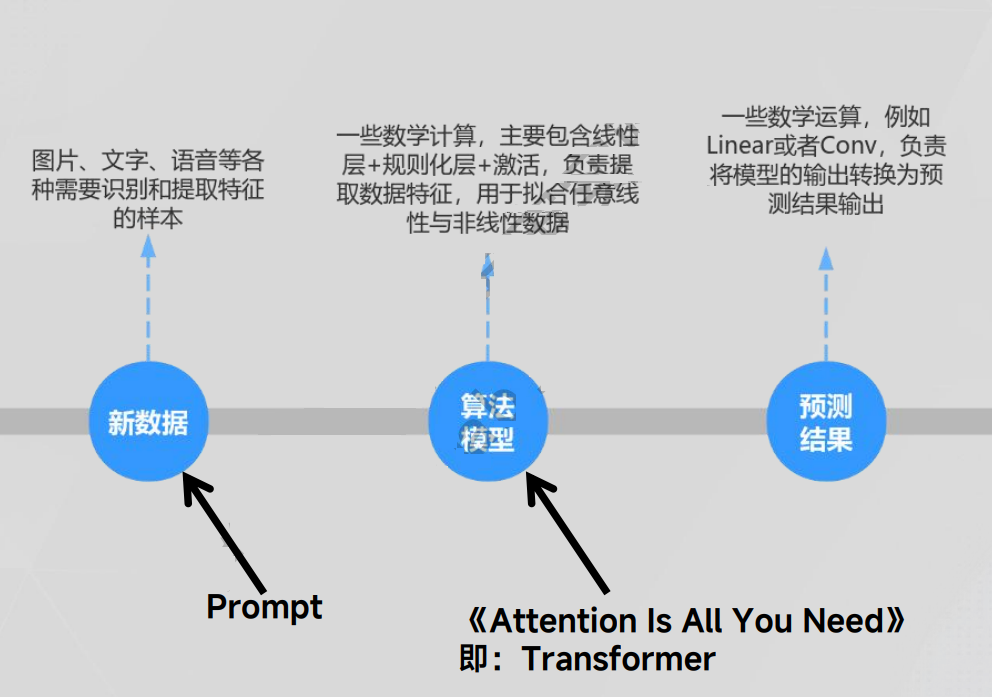 我们发现预测过程与前向过程非常类似,仅仅是把样本数据替换为新数据,同时去除损失函数而已。
我们发现预测过程与前向过程非常类似,仅仅是把样本数据替换为新数据,同时去除损失函数而已。
2.了解自然语言的特点与RNN的简单原理
2.1 RNN的处理方式
RNN最大的特点用一句话总结就是:一维性和时序性。
一维特征的理解:
定义 :一维特征意味着 RNN(循环神经网络)在处理数据时,主要沿着一个时间步的方向进行信息传播。它与二维卷积神经网络(CNN)等处理空间二维数据(如图像的宽和高)的网络不同。在 RNN 中,数据被看作是一个序列,这些数据点按照一定的时间顺序排列,网络的结构是沿着时间维度构建的。
举例说明 :以文本数据处理为例,文本是典型的一维序列数据。假设我们有一段句子 “我爱学习”,每个字依次输入到 RNN 中。在第一个时间步,输入 “我”,网络对 “我” 进行处理;在第二个时间步,输入 “爱”,网络在处理 “爱” 的同时,会结合之前 “我” 的信息;第三个时间步输入 “学”,同样结合前面两个字的信息进行处理。这个过程体现了一维性,即沿着时间步这个一维的方向逐个处理数据。
时序性特征的理解:
定义 :时序性表明 RNN 能够处理具有时间先后顺序的数据。它能够捕捉数据在时间维度上的变化和关联,前一个时间步的输出状态会被传递到下一个时间步,作为下一个时间步的输入的一部分。这种机制使得 RNN 可以对序列数据中存在的动态行为、趋势和周期性等时序特征进行建模。
举例说明 :上例在处理 “我爱学习” 这个文本序列时,RNN 展现出了时序性。当输入 “我” 时,RNN 会产生一个隐藏状态,这个状态包含了 “我” 的相关信息。接着输入 “爱” 时,RNN 不仅会处理 “爱” 自身的信息,还会结合之前 “我” 的隐藏状态,将两者的信息进行整合,生成新的隐藏状态。同样地,输入 “学” 时,网络会结合前两个字的信息以及当前 “学” 的信息来更新隐藏状态。最后输入 “习” 时,也是基于前面所有字的信息来进行处理。这一过程体现了 RNN 对文本序列中字符按照时间先后顺序(即文本的自然顺序)进行处理,并且每个时间步的处理都依赖于之前时间步的隐藏状态,从而捕捉到了文本序列在时间维度上的先后顺序关系,也就是时序性特征。。
一维性和时序性这两个特征使得 RNN 在处理序列数据任务(如自然语言处理、语音识别、时间序列预测等)中表现出色。在自然语言处理中,能够理解文本的语义顺序;在语音识别中,可以捕捉语音信号随时间的变化;在时间序列预测中,可以基于历史数据预测未来趋势。例如,在机器翻译任务中,RNN 利用其一维和时序性特征,能够根据源语言句子的单词顺序(一维序列)来生成目标语言句子,并且在生成过程中利用之前生成的单词(时序性)来保证翻译的连贯性和准确性。
2.2 RNN的缺陷
- 网络的输出具有先后顺序性:每一步运行输出取决于当前的输入与先前的隐藏状态,上一步执行完,才会执行下一步,无法并行计算。
- 记忆丢失:先前的隐藏状态越往后,越记不住更早的记忆,会造成记忆丢失,导致没办法处理长文本,无法捕获长距离的语义关系。
LSTM/GRU的出现仅仅是缓解了第二个问题,但依然远远不够。
3.了解Transformer对比RNN的优势
3.1 Transformer结构
目的:学习所有词的相关性和上下文特征。
为什么能学习? 自注意力机制:Transformer在处理上下文的时候,不仅会注意到它自己的词和附近的词,还会注意到序列里其他的词,并为其赋予不同的权重。所以能够拿到每一个词与其它所有词的相关性,所以与距离无关。
3.2自注意力机制权重分配
比如下面的句子是我们要翻译的输入句子:
”The animal didn’t cross the street because it was too tired”
这句话中的“它”指的是什么? 是指街道还是动物? 对人类来说,这是一个简单的问题,但对算法而言却不那么简单。当模型处理单词“ it”时,自我关注使它可以将“ it”与“ animal”相关联。如下图所示:
![]()
与it关联的词中,颜色越深表示关系越紧密。同时我们发现,这里启用了多态注意力机制,上图总共 8 个头之中只启用 2 个头(橙黄色、绿色),可以看出橙黄色的头把 it 关注的细分语义逻辑重点放在了“The”、“animal”上,而绿色的头把 it 关注的细分语义逻辑重点放在了“tired”身上。
3.3 Transformer是如何解决时序问题
由于 Transformer 模型本身不含像 RNN 那样的循环结构或 CNN 中的卷积结构,并不能天然地感知序列中元素的顺序,因此需要引入位置编码来为模型提供时间序列数据中的时间顺序信息。准确的说应该是词嵌入+位置编码。
输入:文本 -> token -> token ID(数字) -> Embedding向量 解决:Embedding向量 + 位置的向量。
另外一点,与传统的 RNN 或 LSTM 等循环神经网络不同,Transformer 可以并行地处理序列数据中的各个时间步的数据,这极大地提高了模型对序列数据的处理效率,使其能够在更短的时间内对大规模的时序数据进行训练和预测。