随着人工智能技术的飞速发展,大型语言模型(LLM)在自然语言处理(NLP)领域扮演着越来越重要的角色。然而,预训练的模型往往需要针对特定任务进行微调,以提高其在特定领域的性能。LLaMA-Factory作为一个高效、易用的微调工具,为广大开发者带来了极大的便利性。
1.大模型微调的基本概念
1.1 什么是大模型微调
大模型微调就像是对一个已经很厉害的 “学霸” 进行针对性辅导。
比如目前有一个通用的大模型,它就像一个知识渊博的学霸,已经通过海量的数据学习,在很多领域都有不错的理解和能力。但当你有一个特定的任务,比如让你这个学霸专门去解答某一种特别难的数学题型,或者精准地分析某一类特定的文学作品风格,这时候就需要进行微调。
微调就是在这个学霸原有的强大知识基础上,用专门针对这个任务的一小部分数据,对它进行再训练。就好比给学霸做专项练习,让它在特定任务上的表现更好、更精准,更符合你的具体要求。例如,原模型能进行通用的文本生成,但微调后,它能按照某种特定的写作风格生成符合要求的文本,比如模仿古代文言文风格来写故事。
大模型微调通过在特定任务的数据集上继续训练预训练模型来进行,使得模型能够学习到与任务相关的特定特征和知识。这个过程通常涉及到模型权重的微幅调整,而不是从头开始训练一个全新的模型。
1.2 模型微调的过程
微调过程主要包括以下几个步骤:
- 数据准备:收集和准备特定任务的数据集。
- 模型选择:选择一个预训练模型作为基础模型。
- 迁移学习:在新数据集上继续训练模型,同时保留预训练模型的知识。
- 参数调整:根据需要调整模型的参数,如学习率、批大小等。
- 模型评估:在验证集上评估模型的性能,并根据反馈进行调整。
1.3 模型微调的优势
微调技术带来了多方面的优势:
- 资源效率:相比于从头开始训练模型,微调可以显著减少所需的数据量和计算资源。
- 快速部署:微调可以快速适应新任务,加速模型的部署过程。
- 性能提升:针对特定任务的微调可以提高模型的准确性和鲁棒性。
- 领域适应性:微调可以帮助模型更好地理解和适应特定领域的语言特点。
通过微调,可以使得预训练模型在这些任务上取得更好的性能,更好地满足实际应用的需求。
2. LlaMaFactory简介
LlamaFactory 由北京航空航天大学开源的一款模型微调框架, 致力于简化大型语言模型的定制过程。它集成了多种训练策略和监控工具,提供了命令行和WebUI等多种交互方式,大幅降低了模型微调的技术门槛。

LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调,框架特性包括: - 模型种类:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、 - ChatGLM、Phi 等等。 - 训练算法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO - 训练、KTO 训练、ORPO 训练等等。 - 运算精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 - AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。 - 优化算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、 - LoRA+、LoftQ 和 PiSSA。 - 加速算子:FlashAttention-2 和 Unsloth。 - 推理引擎:Transformers 和 vLLM。 - 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
是否可以微调你需要的模型,可以在github上查看。
2.1 核心功能
- 多模型兼容:支持包括LLama、Mistral、Falcon在内的多种大型语言模型。
- 训练方法多样:涵盖全参数微调及LoRA等先进的微调技术。
- 用户界面友好:LLama Board提供了一个直观的Web界面,使用户能够轻松调整模型设置。
- 监控工具集成:与TensorBoard等工具集成,便于监控和分析训练过程。
2.2 LLaMA-Factory特点
- 易用性:简化了机器学习算法的复杂性,通过图形界面即可控制模型微调。
- 微调效率:支持DPO、ORPO、PPO和SFT等技术,提升了模型微调的效率和效果。
- 参数调整灵活性:用户可根据需求轻松调整模型参数,如dropout率、epochs等。
- 多语言支持:界面支持英语、俄语和中文,面向全球用户提供服务。
2.3 使用场景
LLaMA-Factory适用于广泛的NLP任务,包括但不限于:
- 文本分类:实现情感分析、主题识别等功能。
- 序列标注:如NER、词性标注等任务。
- 文本生成:自动生成文本摘要、对话等。
- 机器翻译:优化特定语言对的翻译质量。
- LLaMA-Factory通过其强大的功能和易用性,助力用户在自然语言处理领域快速实现模型的定制和优化。
2.4 微调时参数量与硬件需求
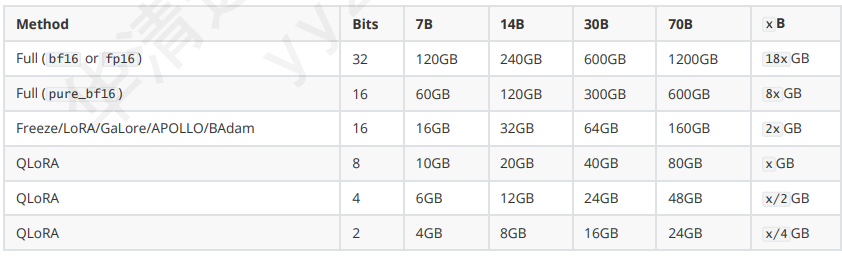
Method (方法):列出了不同的微调方法,包括:
- Full (bf16 or fp16): 全参数微调,使用 bf16 或 fp16 精度。
- Full (pure_bf16): 全参数微调,强制使用 bf16 精度。
- Freeze/LoRA/GaLore/APOLLO/BAdam: 参数高效微调方法,这些方法只微调模型的一小部分参数或引入额外的少量参数。
- QLORA: 量化低秩适配器 (Quantized Low-Rank Adapters) 方法,通过量化模型权重并在低秩子空间中进行微调来显著降低内存需求。
Bits (位数):表示模型权重在微调过程中使用的精度位数。较低的位数意味着更低的内存占用,但也可能影响模型性能。 - 32 位 (bf16 or fp16) - 16 位 (pure_bf16, Freeze/LoRA/GaLore/APOLLO/BAdam) - 8 位 (QLORA) - 4 位 (QLORA) - 2 位 (QLORA)
7B, 14B, 30B, 70B, x B: 表示不同大小的语言模型,这里的数字代表模型拥有的参数量(以十亿为单位)。例如,7B 表示拥有 70 亿参数的模型。 "x B" 是一个更大的未知参数量的模型。 Hardware Requirement (硬件需求): 表格中的数值表示在对应的微调方法、精度和模型大小下,估计所需的 GPU 内存大小(以 GB 为单位)。
2.AutoDL算力云服务器基本使用
由于使用LlamaFactory进行大模型微调对电脑GPU的显存要求比较高,一般的笔记本电脑很难胜任大模型微调任务。因此我们需要租用AutoDL算力云服务器来完成微调任务。
以下示例基于 AutoDL 云计算资源。
在云计算平台选择可用的云计算资源实例,如果有3090实例可用,推荐选择3090实例(性价比更高)。同时注意镜像的选择,所以镜像会包含特定的环境,省去一些基础环境的安装步骤,不过这里镜像在实例启动之后也可以进行切换。
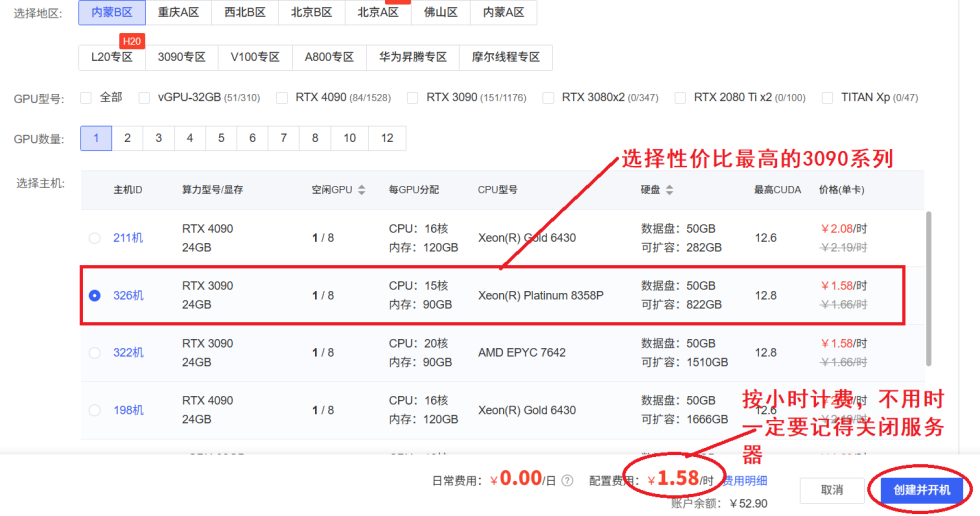
选择镜像环境。

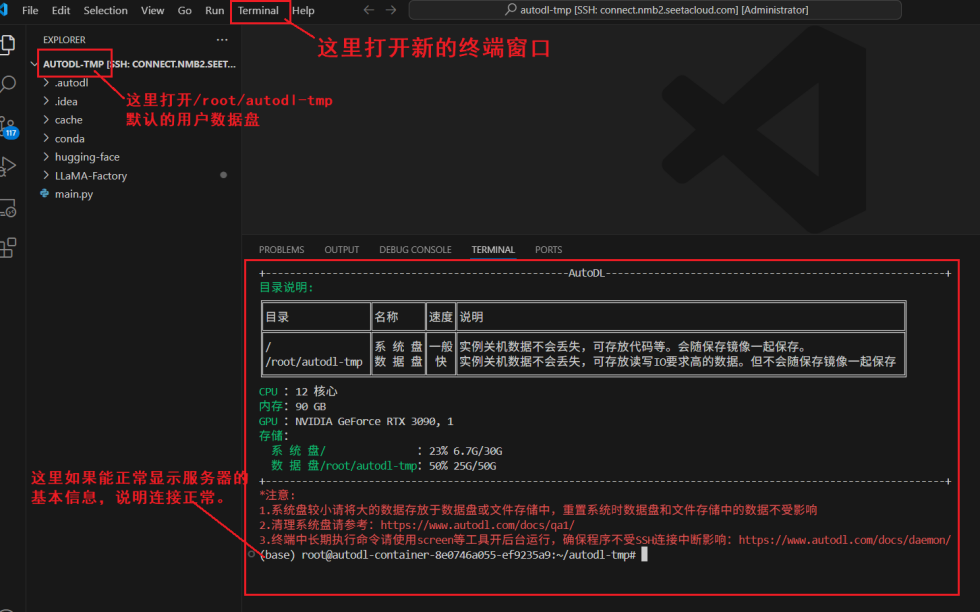
创建实例之后,开机后,通过SSH连接远程服务器。

这里我使用 VS Code的 Remote-SSH 插件进行连接,连接进去之后可以看到实例中有两个盘,其中/root/autodl-tmp是数据盘,推荐运行环境、模型文件都放在数据盘,避免后续因为实例关机回收导致数据文件丢失。
3.在AutoDL算力云服务器上安装LlamaFactory
LLaMa-Factory 的 git 地址如下,通过 git 命令拉取:
git clone https://github.com/hiyouga/LLaMA-Factory.git
安装依赖环境:
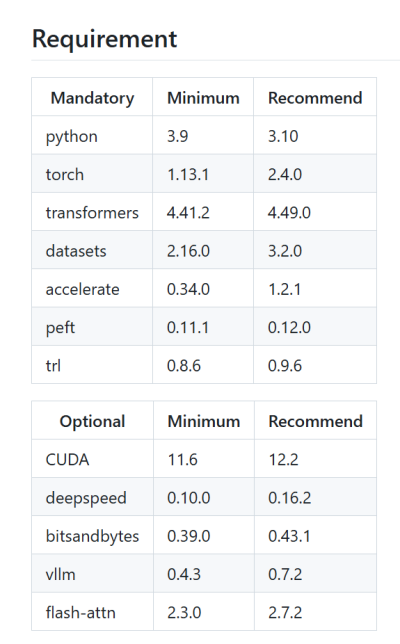
LLaMa-Factory 依赖 Python 特定版本,这里使用 Conda 来进行 Python 虚拟环境管理,大语言模型相关的框架对运行环境的依赖比较严重,推荐通过虚拟环境进行隔离。
而在创建虚拟环境之前,推荐设置一下 Conda 虚拟环境和 Python 包的保存路径,还是那个原因,避免因为云计算资源回收导致数据丢失。
mkdir -p /root/autodl-tmp/conda/pkgs
conda config --add pkgs_dirs /root/autodl-tmp/conda/pkgs
mkdir -p /root/autodl-tmp/conda/envs
conda config --add envs_dirs /root/autodl-tmp/conda/envs/
下来创建虚拟环境:
conda create -n llama-factory python=3.10
虚拟环境创建完成之后,通过以下命令初始化以下Conda,并刷新一下命令行环境变量,再激活环境:
conda init
source ~/.bashrc
conda activate llama-factory
之后进入 LLaMa-Factory 文件夹,通过以下命令进行 LLaMa-Factory 相关依赖包的安装。
pip install -e ".[torch,metrics]"
#解决包冲突。(可选)
pip install --no-deps -e .
注意:咱们使用了AutoDL算力云服务器,默认已经安装cuda版本的pytorch,如果咱们需要在自己的windows电脑使用LlamaFactory微调,首先要确保安装了cuda版本的pytorch,可以使用以下命令安装:
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu121
其它可选的安装依赖:
pip install deepspeed==0.16.4 bitsandbytes==0.43.1 vllm==0.7.3 flashattn==2.7.3 -i http://mirrors.aliyun.com/pypi/simple
安装完成之后,通过以下命令测试一下 LLaMa-Factory 是否正常安装:
llamafactory-cli version

通过以下命令启动 LLaMa-Factory 可视化微调界面:
llamafactory-cli webui

==注意:输入这个命令必须在LLaMA-Factory目录下启动。==
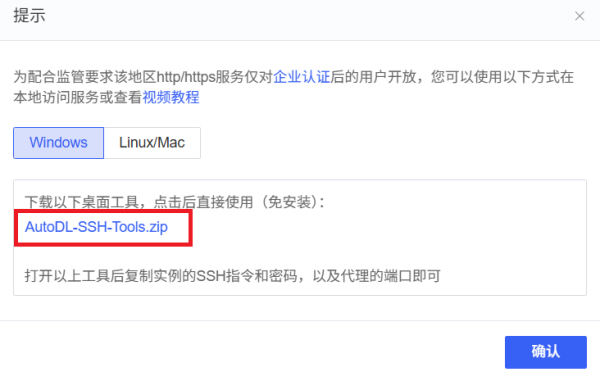
通过 VS Code 中的 Remote-SSH 插件连接云服务器的情况,启动可视化界面之后,Remote-SSH 会自动进行端口转发,从而自动在本地浏览器打开相应的页面。如果是其他工具的话,可能需要在云平台配置一下相应的端口,之后通过云平台暴漏出来的域名打开。
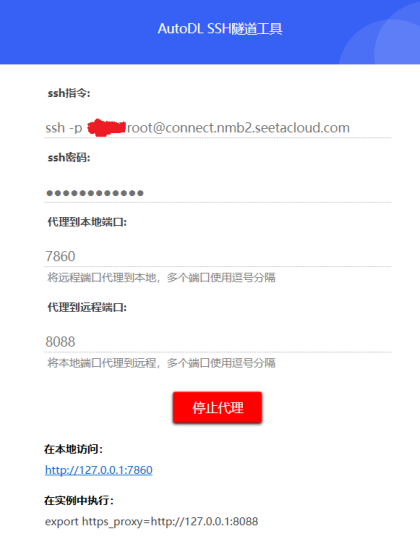
其他工具的话,需要安装AutoDL官网提供的网络穿透工具,才能实现端口转发。在实例界面选择:自定义服务。 下载网络穿透工具。
4. 从 Huggingface下载模型
首先创建一个文件夹用于存放模型文件:
mkdir hugging-face
增加环境变量,修改 HuggingFace 镜像源为国内镜像网站:
export HF_ENDPOINT=https://hf-mirror.com
修改模型默认存储路径:
export HF_HOME=/root/autodl-tmp/hugging-face

之后还是切换到 llama-factory 虚拟环境,安装 HuggingFace官方下载工具:
pip install -U huggingface_hub
安装完成之后,通过以下命令下载模型:
huggingface-cli download --resume-download Qwen/Qwen2.5-0.5B-Instruct
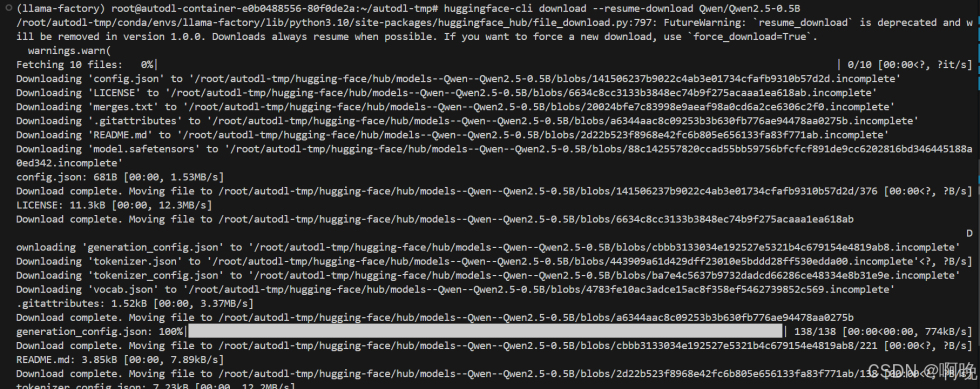
这里为了下载和后面的微调演示快点就下载0.5B的模型了,具体的模型大家可以根据实际情况去选择自己需要的模型,在huggingface上搜索模型名称,之后进入模型主页,复制名称即可。模型文件都比较大,在线下载的话需要等待一段时间,下载完成之后,可以看到模型文件就在 hugging-face 文件夹下了。
下载完成模型之后,我们需要验证模型文件是否可以正常加载、运行,可以通过 LLaMa-Factory 的可视乎界面加载运行模型:
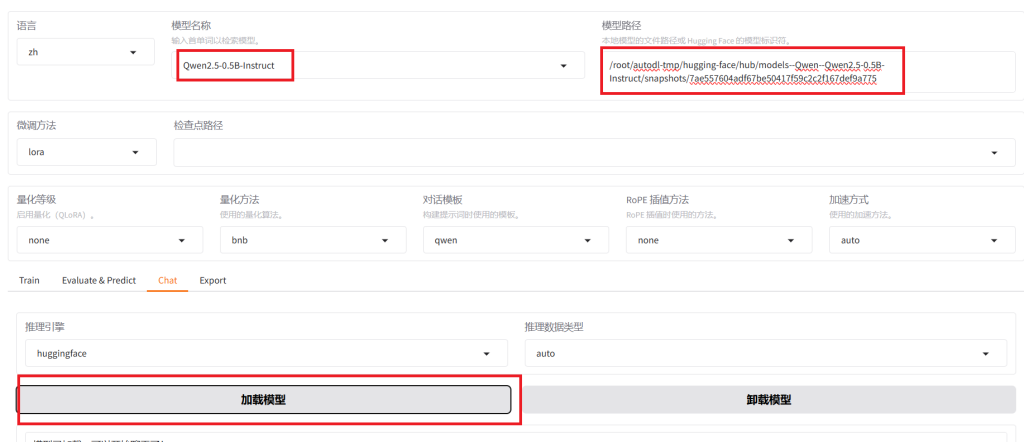
需要注意的是,加载本地模型的时候,需要修改填写模型本地路径,这里的路径是模型快照的唯一哈希值,而不是模型文件夹的路径。
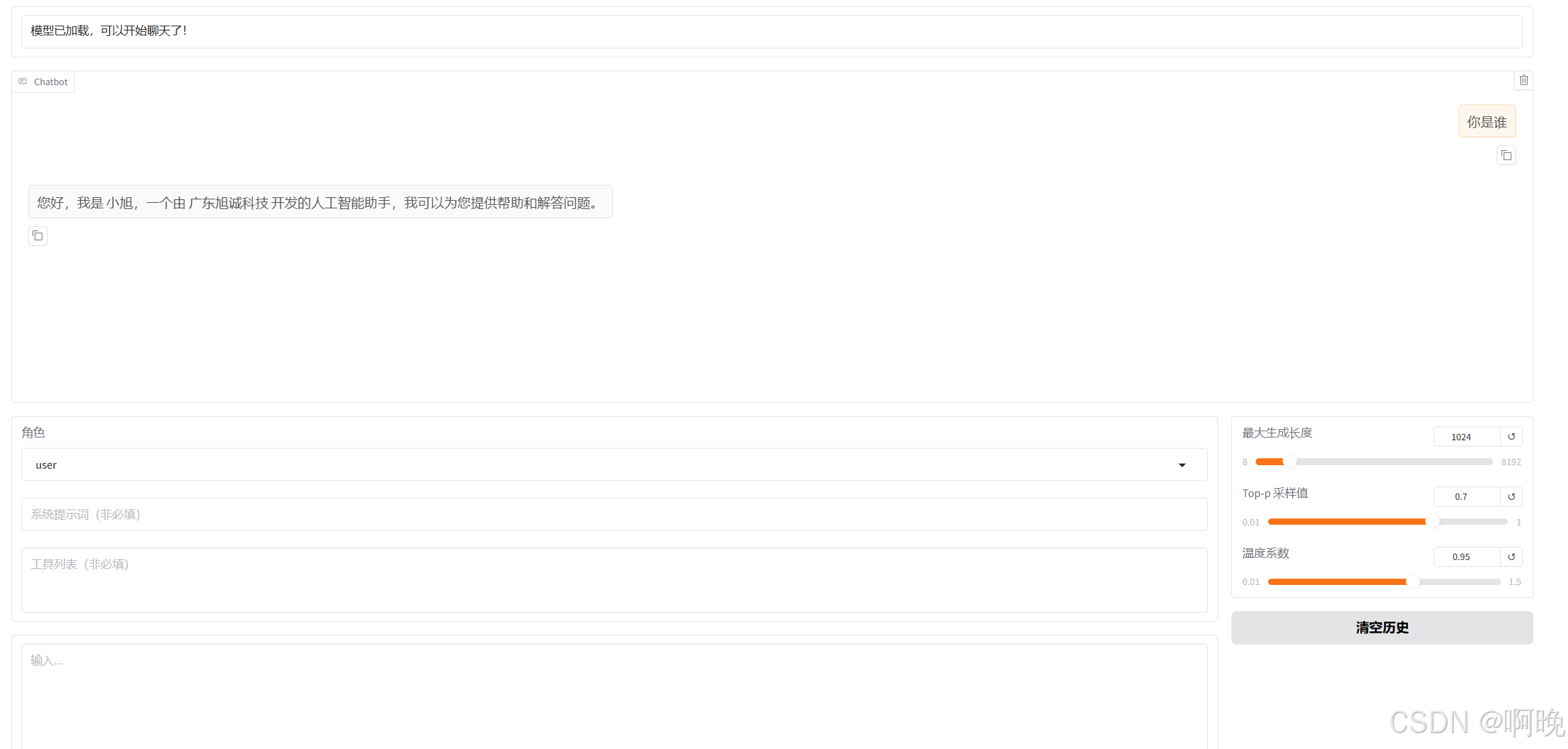
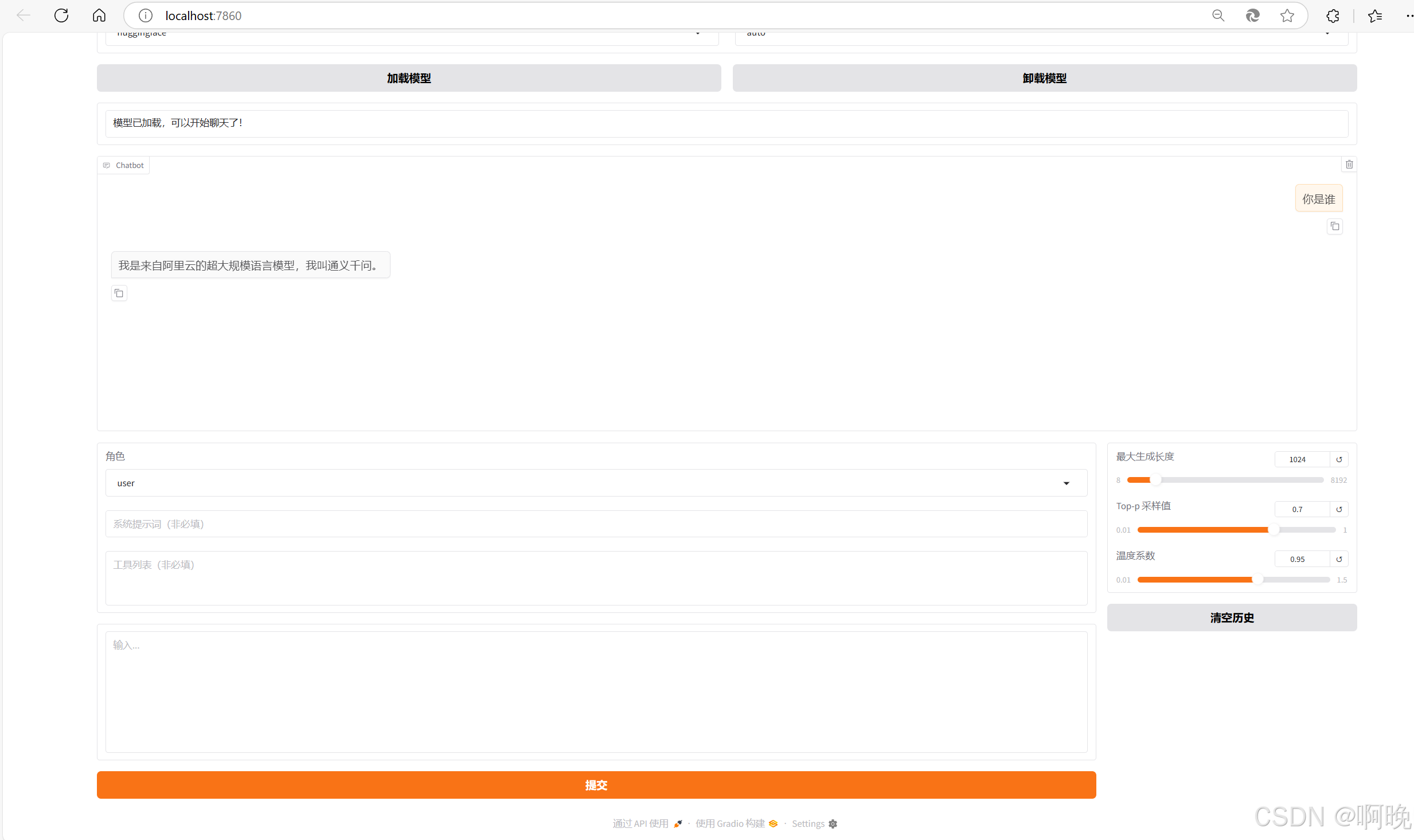
之后就可通过和模型进行对话,测试下载下来的模型是否正常了,也可以看下对话中模型输出的风格,和我们微调之后的做下对比。
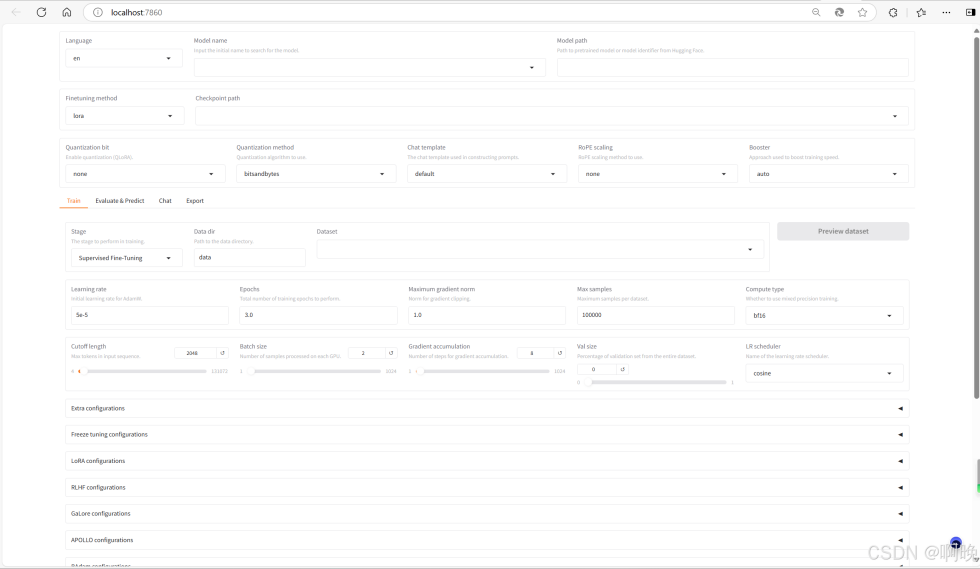
5.模型微调
接下来就可以通过 LLaMa-Factory 进行微调了,这里先做一个简单的演示,为了不让这篇文章篇幅过长,先不具体讲解各种微调参数的含义和作用,数据集也只使用 LLaMa-Factory 自带的示例数据集,演示一下对模型认知设定的微调。
修改一下默认的 identity.json 数据集,将其中的{{name}}、{{author}}替换为我们自己的设定,并保存文件。
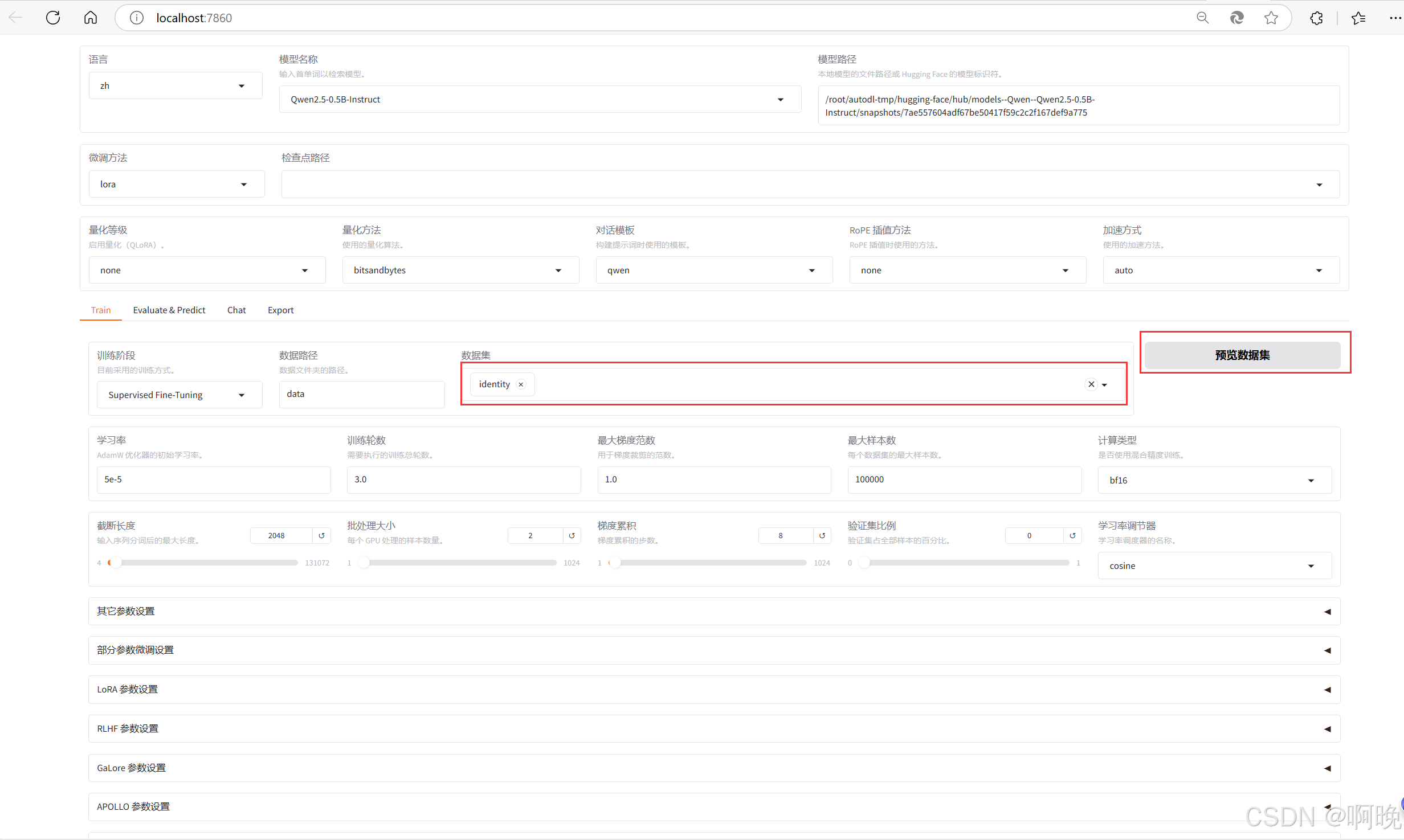
之后在 LLaMa-Factory Web界面中加载预览数据集,并且稍微调整一下超参,主要是学习率先保存不变,主要是训练轮次,以及验证集比例。
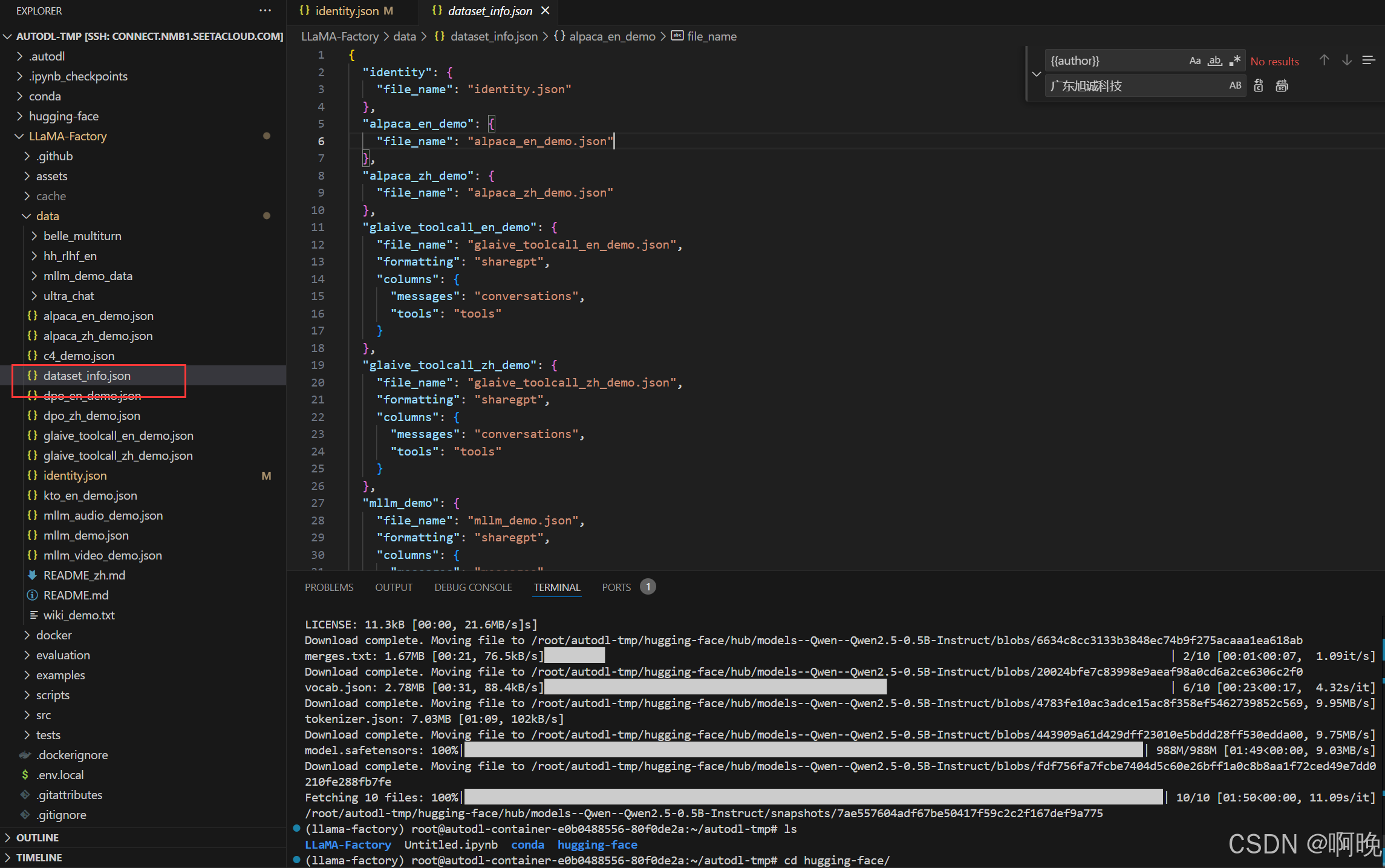
后续如果需要使用我们自定义的数据集的话,也只要将数据集文件放到 LLaMa-Factory 的 data 文件夹,再在 dataset_info.json 中进行配置,就可以在 Web 界面进行加载使用。这里就先展开细说了。
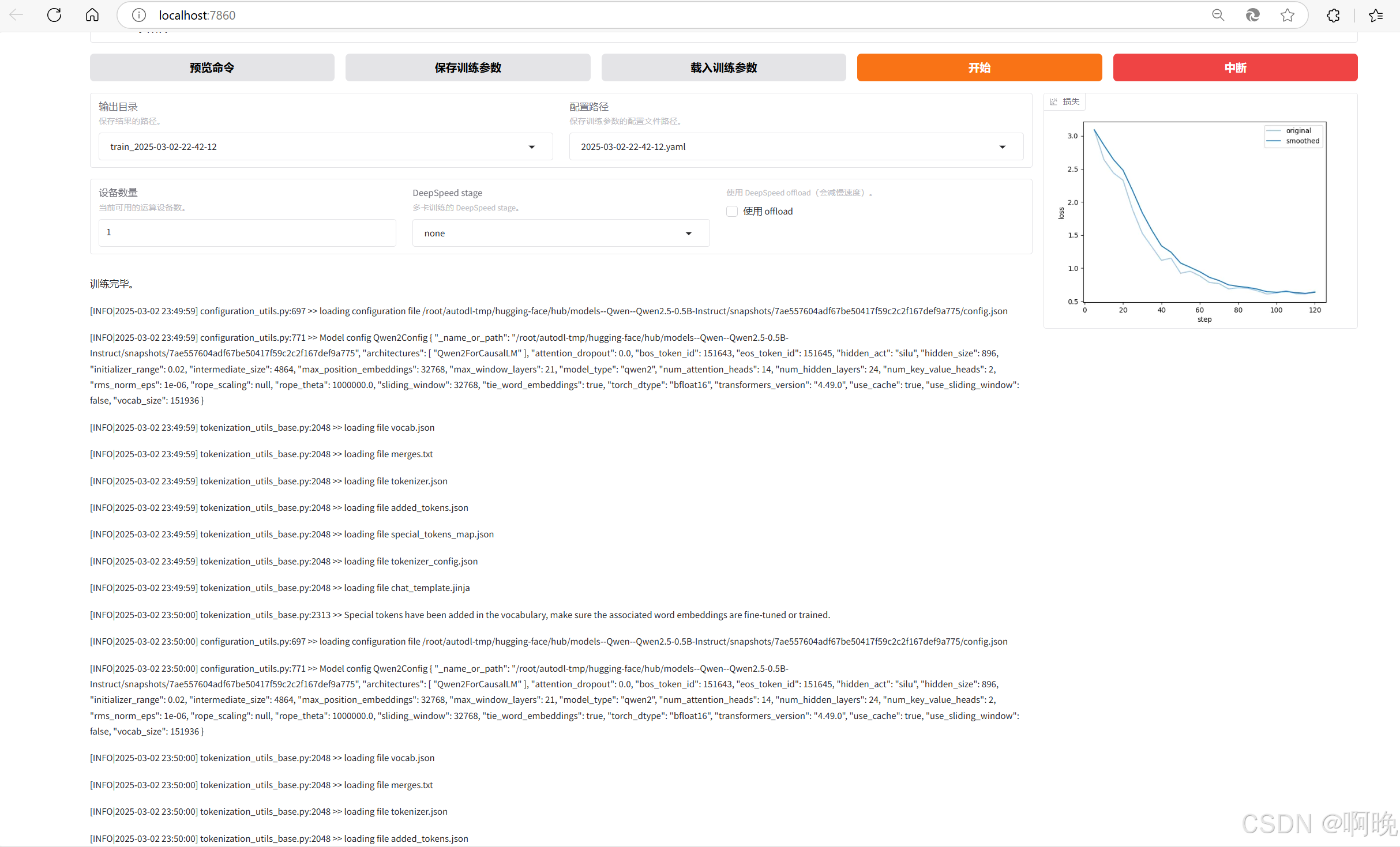
之后点击开始,可以看到微调任务的执行进度,以及损失函数的变化情况。

0.5B 的模型,再加上数据集数据量不多,只有不到100条,所以微调过程还是很快的,可以看到最终的损失函数降到了 0.5 左右。不过这是因为训练数据太少,而且一些超参设置比较不合理,才有这样的较低损失函数,实际微调用于生产环境的模型时,要注意防止过拟合的情况。
之后,还是用 LLaMa-Factory 加载微调之后的模型文件进行测试,这里通过检查点路径添加刚刚训练完成的模型文件:
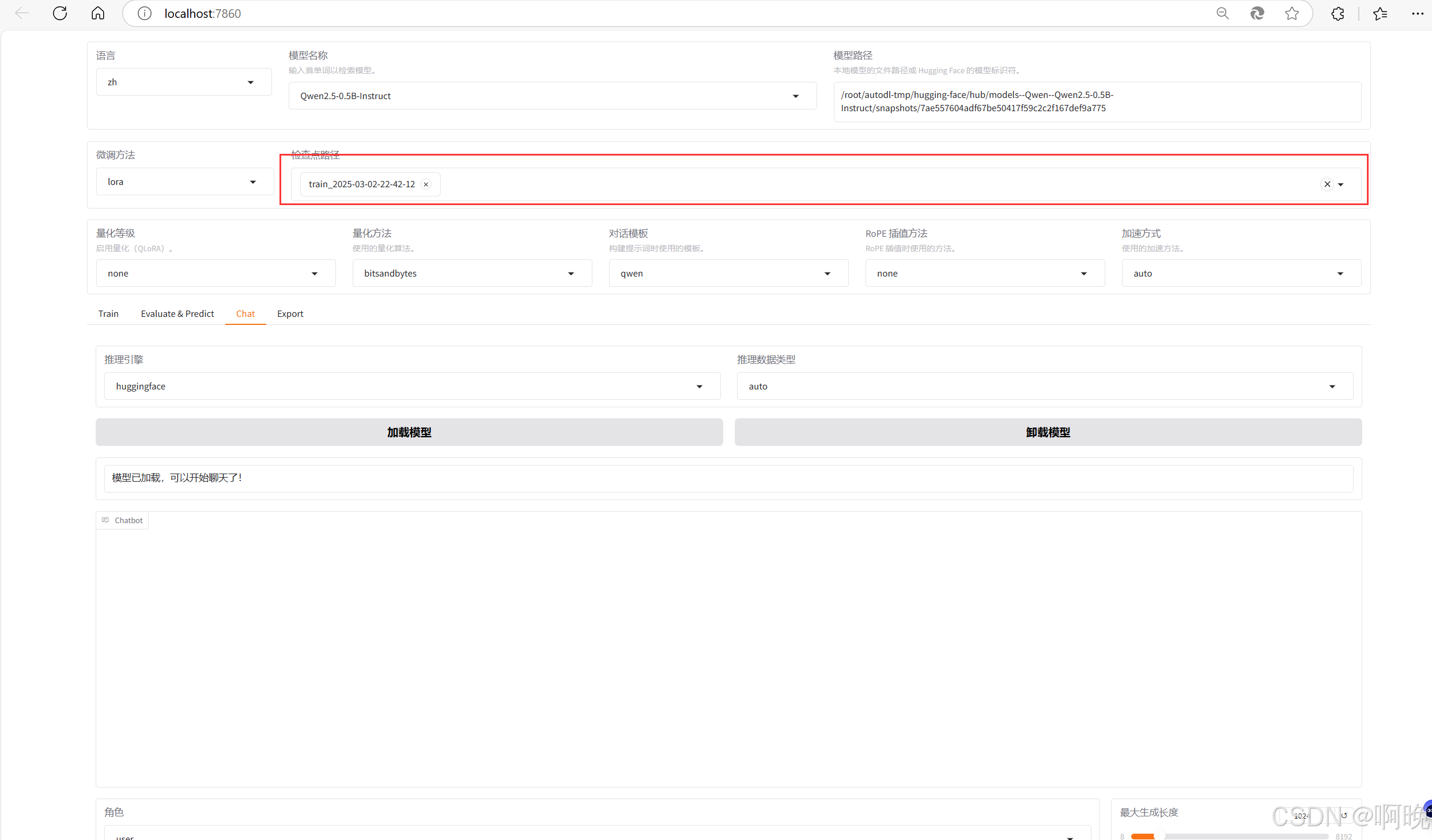
之后就可以和我们微调之后的模型进行对话了。