GPT-2(Generative Pre-trained Transformer 2)是 OpenAI 在 2019 年提出的 第二代 GPT 模型,是一个 大规模自回归语言模型,用于 文本生成(NLG)任务。
1.GPT-2简介
GPT-2(Generative Pre-trained Transformer 2)是由OpenAI在2019年发布的一款基于Transformer架构的语言模型。它是一个深度学习模型,设计用于生成自然语言文本,能够根据给定的文本片段预测并生成后续的文本内容。GPT-2通过大规模无监督学习训练,在互联网上抓取的大量文本数据上进行了预训练,使其能够理解和生成多种类型的文本,包括文章、故事、诗歌等。
GPT-2有四种不同的大小,最小的是124M,即1.24亿参数(上图中计算有误),它有12层Transformer,有768个通道。
GPT-2 采用 四种不同规模的模型:

OpenAI的GPT-2: https://github.com/openai/gpt-2/tree/master(TensorFlow完成的,设计比较复杂)
transformers的GPT-2:https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt2/modeling_gpt2.py。(PyTorch完成的,中等可读)
GPT-2 的核心思想基于:
- 更大的 Transformer 解码器(Decoder)架构
- 更大规模的训练数据
- 更强的无监督学习能力
- 自回归文本生成
- 多任务适应性(Zero-shot, Few-shot, Fine-tuning)
2.GPT-2网络结构介绍
2.1 加载模型与查看网络参数
可以使用transformers加载GPT-2模型:
from transformers import GPT2LMHeadModel
import matplotlib.pyplot as plt
if __name__ == '__main__':
model = GPT2LMHeadModel.from_pretrained("./gpt2") # 124M
sd = model.state_dict()
for k, v in sd.items():
print(k, v.shape)
默认情况下使用transformers加载时,加载的是124M的模型。 print(k,v.shape) 这一行是用来打印模型参数的名字及其形状的。
- 获取模型状态字典: model.state_dict() 返回的是一个包含模型所有可学习参数的状态字典。这个字典的键是参数的名字,值是对应的参数张量。
- 遍历状态字典:通过 for k, v in sd.items(): 这一行代码,你遍历了状态字典中的每一个键值对。在这里, k 表示参数的名字,而 v 表示对应的参数张量。
- 打印参数名字和形状:print(k, v.shape) 这一行代码的作用是打印每个参数的名字(k)以及该参数张量的形状( v.shape)。 v.shape 返回的是一个PyTorch 的 torch.Size 对象,表示张量的维度大小。
输出结果:
transformer.wte.weight torch.Size([50257, 768])
transformer.wpe.weight torch.Size([1024, 768])
transformer.h.0.ln_1.weight torch.Size([768])
transformer.h.0.ln_1.bias torch.Size([768])
transformer.h.0.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.0.attn.c_attn.bias torch.Size([2304])
transformer.h.0.attn.c_proj.weight torch.Size([768, 768])
transformer.h.0.attn.c_proj.bias torch.Size([768])
transformer.h.0.ln_2.weight torch.Size([768])
transformer.h.0.ln_2.bias torch.Size([768])
transformer.h.0.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.0.mlp.c_fc.bias torch.Size([3072])
transformer.h.0.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.0.mlp.c_proj.bias torch.Size([768])
transformer.h.1.ln_1.weight torch.Size([768])
transformer.h.1.ln_1.bias torch.Size([768])
transformer.h.1.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.1.attn.c_attn.bias torch.Size([2304])
transformer.h.1.attn.c_proj.weight torch.Size([768, 768])
transformer.h.1.attn.c_proj.bias torch.Size([768])
transformer.h.1.ln_2.weight torch.Size([768])
transformer.h.1.ln_2.bias torch.Size([768])
transformer.h.1.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.1.mlp.c_fc.bias torch.Size([3072])
transformer.h.1.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.1.mlp.c_proj.bias torch.Size([768])
transformer.h.2.ln_1.weight torch.Size([768])
transformer.h.2.ln_1.bias torch.Size([768])
transformer.h.2.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.2.attn.c_attn.bias torch.Size([2304])
transformer.h.2.attn.c_proj.weight torch.Size([768, 768])
transformer.h.2.attn.c_proj.bias torch.Size([768])
transformer.h.2.ln_2.weight torch.Size([768])
transformer.h.2.ln_2.bias torch.Size([768])
transformer.h.2.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.2.mlp.c_fc.bias torch.Size([3072])
transformer.h.2.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.2.mlp.c_proj.bias torch.Size([768])
transformer.h.3.ln_1.weight torch.Size([768])
transformer.h.3.ln_1.bias torch.Size([768])
transformer.h.3.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.3.attn.c_attn.bias torch.Size([2304])
transformer.h.3.attn.c_proj.weight torch.Size([768, 768])
transformer.h.3.attn.c_proj.bias torch.Size([768])
transformer.h.3.ln_2.weight torch.Size([768])
transformer.h.3.ln_2.bias torch.Size([768])
transformer.h.3.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.3.mlp.c_fc.bias torch.Size([3072])
transformer.h.3.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.3.mlp.c_proj.bias torch.Size([768])
transformer.h.4.ln_1.weight torch.Size([768])
transformer.h.4.ln_1.bias torch.Size([768])
transformer.h.4.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.4.attn.c_attn.bias torch.Size([2304])
transformer.h.4.attn.c_proj.weight torch.Size([768, 768])
transformer.h.4.attn.c_proj.bias torch.Size([768])
transformer.h.4.ln_2.weight torch.Size([768])
transformer.h.4.ln_2.bias torch.Size([768])
transformer.h.4.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.4.mlp.c_fc.bias torch.Size([3072])
transformer.h.4.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.4.mlp.c_proj.bias torch.Size([768])
transformer.h.5.ln_1.weight torch.Size([768])
transformer.h.5.ln_1.bias torch.Size([768])
transformer.h.5.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.5.attn.c_attn.bias torch.Size([2304])
transformer.h.5.attn.c_proj.weight torch.Size([768, 768])
transformer.h.5.attn.c_proj.bias torch.Size([768])
transformer.h.5.ln_2.weight torch.Size([768])
transformer.h.5.ln_2.bias torch.Size([768])
transformer.h.5.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.5.mlp.c_fc.bias torch.Size([3072])
transformer.h.5.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.5.mlp.c_proj.bias torch.Size([768])
transformer.h.6.ln_1.weight torch.Size([768])
transformer.h.6.ln_1.bias torch.Size([768])
transformer.h.6.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.6.attn.c_attn.bias torch.Size([2304])
transformer.h.6.attn.c_proj.weight torch.Size([768, 768])
transformer.h.6.attn.c_proj.bias torch.Size([768])
transformer.h.6.ln_2.weight torch.Size([768])
transformer.h.6.ln_2.bias torch.Size([768])
transformer.h.6.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.6.mlp.c_fc.bias torch.Size([3072])
transformer.h.6.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.6.mlp.c_proj.bias torch.Size([768])
transformer.h.7.ln_1.weight torch.Size([768])
transformer.h.7.ln_1.bias torch.Size([768])
transformer.h.7.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.7.attn.c_attn.bias torch.Size([2304])
transformer.h.7.attn.c_proj.weight torch.Size([768, 768])
transformer.h.7.attn.c_proj.bias torch.Size([768])
transformer.h.7.ln_2.weight torch.Size([768])
transformer.h.7.ln_2.bias torch.Size([768])
transformer.h.7.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.7.mlp.c_fc.bias torch.Size([3072])
transformer.h.7.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.7.mlp.c_proj.bias torch.Size([768])
transformer.h.8.ln_1.weight torch.Size([768])
transformer.h.8.ln_1.bias torch.Size([768])
transformer.h.8.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.8.attn.c_attn.bias torch.Size([2304])
transformer.h.8.attn.c_proj.weight torch.Size([768, 768])
transformer.h.8.attn.c_proj.bias torch.Size([768])
transformer.h.8.ln_2.weight torch.Size([768])
transformer.h.8.ln_2.bias torch.Size([768])
transformer.h.8.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.8.mlp.c_fc.bias torch.Size([3072])
transformer.h.8.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.8.mlp.c_proj.bias torch.Size([768])
transformer.h.9.ln_1.weight torch.Size([768])
transformer.h.9.ln_1.bias torch.Size([768])
transformer.h.9.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.9.attn.c_attn.bias torch.Size([2304])
transformer.h.9.attn.c_proj.weight torch.Size([768, 768])
transformer.h.9.attn.c_proj.bias torch.Size([768])
transformer.h.9.ln_2.weight torch.Size([768])
transformer.h.9.ln_2.bias torch.Size([768])
transformer.h.9.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.9.mlp.c_fc.bias torch.Size([3072])
transformer.h.9.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.9.mlp.c_proj.bias torch.Size([768])
transformer.h.10.ln_1.weight torch.Size([768])
transformer.h.10.ln_1.bias torch.Size([768])
transformer.h.10.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.10.attn.c_attn.bias torch.Size([2304])
transformer.h.10.attn.c_proj.weight torch.Size([768, 768])
transformer.h.10.attn.c_proj.bias torch.Size([768])
transformer.h.10.ln_2.weight torch.Size([768])
transformer.h.10.ln_2.bias torch.Size([768])
transformer.h.10.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.10.mlp.c_fc.bias torch.Size([3072])
transformer.h.10.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.10.mlp.c_proj.bias torch.Size([768])
transformer.h.11.ln_1.weight torch.Size([768])
transformer.h.11.ln_1.bias torch.Size([768])
transformer.h.11.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.11.attn.c_attn.bias torch.Size([2304])
transformer.h.11.attn.c_proj.weight torch.Size([768, 768])
transformer.h.11.attn.c_proj.bias torch.Size([768])
transformer.h.11.ln_2.weight torch.Size([768])
transformer.h.11.ln_2.bias torch.Size([768])
transformer.h.11.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.11.mlp.c_fc.bias torch.Size([3072])
transformer.h.11.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.11.mlp.c_proj.bias torch.Size([768])
transformer.ln_f.weight torch.Size([768])
transformer.ln_f.bias torch.Size([768])
lm_head.weight torch.Size([50257, 768])
这里每一行都表示一个模型参数的名字和它的形状。
- 第一行: transformer.wte.weight 是词嵌入矩阵,其中 wte 是 "word token embeddings" 的缩写。形状为 [50257, 768],表示有 50257 个词汇tokens,每个tokens的嵌入向量维度为 768。
- 第二行: transformer.wpe.weight 是位置嵌入矩阵, wpe 是 "word position embeddings" 的缩写,形状为 [1024, 768], [max_position_embeddings,embedding_size] 的维度。 max_position_embeddings 是 1024,意味着最多支持 1024 个词的序列,embedding_size 通常是 768。
在前向传播过程中,输入序列中的每个词不仅会被转换成词嵌入向量,还会被加上对应位置的位置嵌入向量。例如,假设输入序列的第一个词的词嵌入向量是 e_1,那么加上位置嵌入向量 p_1 后,得到的最终向量为 e_1 + p_1。
2.2拿出前20个位置编码的数据
# 展平位置嵌入矩阵并取出前20个元素
print(sd["transformer.wpe.weight"].view(-1)[:20])
import matplotlib.pyplot as plt
plt.imshow(sd["transformer.wpe.weight"], cmap="gray")
plt.show()
运行结果:
tensor([-0.0188, -0.1974, 0.0040, 0.0113, 0.0638, -0.1050, 0.0369, -0.1680,
-0.0491, -0.0565, -0.0025, 0.0135, -0.0042, 0.0151, 0.0166, -0.1381,
-0.0063, -0.0461, 0.0267, -0.2042])
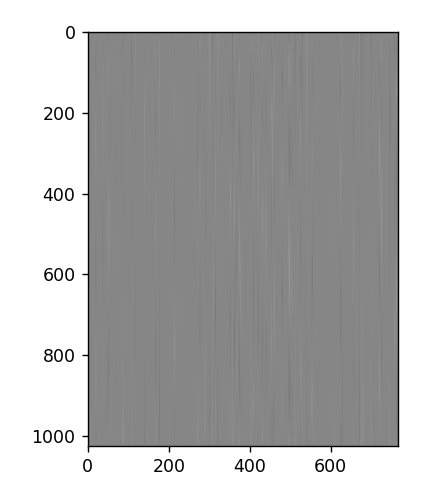
这张图展示的是 GPT-2 模型中位置嵌入矩阵 transformer.wpe.weight 的可视化结果。由于使用了 imshow 函数并将 cmap 参数设置为 "gray",所以图像是以灰度形式呈现的。 在这个灰度图像中,每一条垂直线代表了位置嵌入矩阵的一个列向量。由于矩阵的形状是 [1024, 768],所以图像中有 1024 条垂直线,每条线的高度为 768 像素。
灰度图像解释:
- 图像中的每一行代表输入序列中某个具体位置的嵌入向量(最多 1024 个位置)。
- 每一列代表嵌入向量的一个维度。
- 每个像素的灰度值表示该特定位置和维度上的权重值,颜色越暗表示值越低,颜色越亮表示值越高。
模式解释:
- 图像中出现了纵向的条纹或变化,这表明嵌入权重在不同位置上的变化情况。某些位置可能在特定维度上具有相似的嵌入值,从而形成这些条纹。
- GPT-2 的位置嵌入是可学习的,这意味着模型根据训练数据优化了它们,而不是像 BERT 那样使用固定的正弦曲线模式。因此,这些嵌入呈现出较复杂的、非均匀的模式。
随机拿出来三个展示一下:
plt.plot(sd["transformer.wpe.weight"][:, 150])
plt.plot(sd["transformer.wpe.weight"][:, 200])
plt.plot(sd["transformer.wpe.weight"][:, 250])
plt.show()
可以看到:
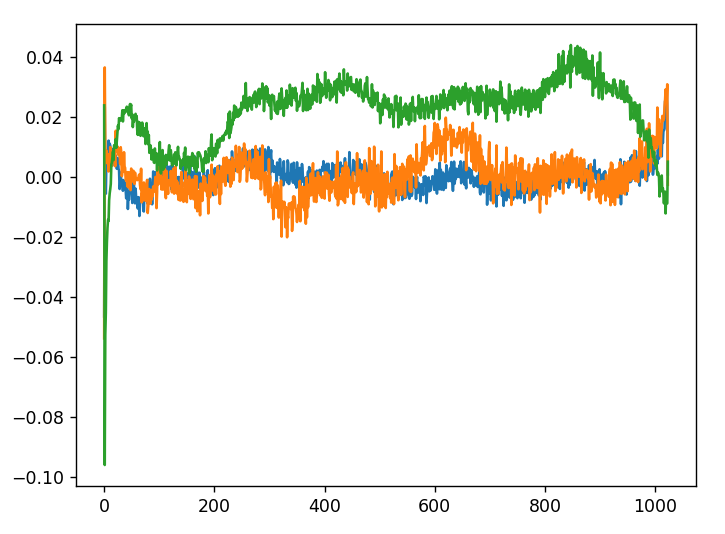
这张图展示了 GPT-2 模型的三个特定维度(150、200 和 250)在位置嵌入矩阵中随着序列位置(从 0 到 1024)的权重变化情况。图中三条曲线分别对应transformer.wpe.weight 矩阵中第 150 列、第 200 列和第 250 列的值,即每个序列位置(行)在这些维度上的权重变化。
三条曲线(绿色、橙色和蓝色)各自表示一个特定维度的权重值随位置的变化。可以看到,不同维度的曲线形状和波动模式并不完全相同,表明 GPT-2 学习到不同维度在位置嵌入中的作用各不相同。例如,绿色曲线在整体上有更明显的正向趋势,而橙色和蓝色曲线则围绕 0 上下波动。不同的模式反映了模型在不同维度上对位置的差异化编码方式。这些波动与 GPT-2 的学习目标相关,它通过在训练数据中优化位置嵌入,使得每个位置的嵌入具有独特的模式,帮助模型编码输入序列中的位置依赖信息。
位置嵌入不是简单的线性或周期性变化,有点像正余弦曲线,但是又不同,因为经过优化的之后的结果,反映 GPT-2 模型在自然语言序列上学习到的位置信息。
2.3 快速语言生成
from transformers import pipeline, set_seed
if __name__ == '__main__':
generator = pipeline("text-generation", model="./gpt2")
set_seed(42)
print(generator("Hello, I'm a language model", max_length=30, num_return_sequences=5))
所以可以根据生成提示: "Hello, I'm a language model" 从而生成文本的最大长度为 30 个字符、5 个不同的文本序列。功能其实就是在续写。生成结果(不同电脑可能会不同):
输出结果:
[{'generated_text': "Hello, I'm a language modeler. I'm fluent in several languages. I know a lot about each one, but I don't usually write"}, {'generated_text': "Hello, I'm a language modeler, not a compiler and never got the time to learn this idea. I've also been working on my own"}, {'generated_text': "Hello, I'm a language model, but there's so little interaction that those things get out of hand at different moments, so that has to be"}, {'generated_text': "Hello, I'm a language model, one of the key tenets of the open source, open source computing ecosystem. I'm the founder, co-"}, {'generated_text': "Hello, I'm a language model. I take for granted the limitations of the English-speaking world and the vast resources of knowledge it offers. I"}]
也可以通过调整温度(temperature)、Top-k 采样、Top-p 采样 可以控制 GPT-2生成文本的多样性和连贯性。
result = generator("Hello, I'm a language model", max_length=30, temperature=0.7, top_k=50, top_p=0.9,
do_sample=True,
num_return_sequences=5)
print(result)
"""
output = model.generate(
input_ids,
max_length=50,
temperature=0.7, # 控制随机性,值越低越确定
top_k=50, # 仅从前 50 个可能的单词中采样
top_p=0.9, # 仅从累积概率为 0.9 的单词中采样
do_sample=True # 允许随机采样
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
"""
3.手写GPT-2
3.1 GPT-2网络结构介绍
Decoder Only 结构,GPT-2 采用了一种新的结构,在整个模型中只存在 Decoder 模块,称为 Decoder Only 结构。由于没有 Encoder,Decoder 模块的 encoder-decode 注意力就没有意义了,因此它也被移除了。可以回看本文 Encoder-Decoder 结构的图示,其中把 Decoder 的 Multi-Head Attention 和它的 Add&Norm 删掉,便是 GPT-2 的 Decoder 结构了(其实也可以看作把 Encoder 的 Multi-Head Attention 换成 Masked Multi-Head Attention)。
以下便是 GPT-2 的总体结构了:
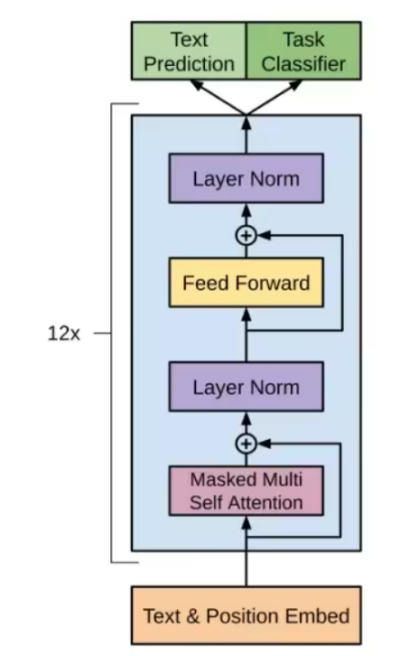
GPT-2对比Transformer,去掉了Encoder部分,同时去掉了交叉注意力。其中Layer normalization层归一化被移动到每个子块的输入中,类似于预激活残差网络(1),并在最后一个自注意力块之后添加了一个额外的层归一化(2)。使用修改后的初始化,该初始化考虑了模型深度上的残差路径的累积。我们在初始化时将残差层的权重乘以1/N,其中 N 是残差层的数量(3)。
- 在传统的残差网络中,层归一化通常放在残差块的输出处。而在 GPT-2 中,层归一化被移到了每个子块的输入处,类似于预激活残差网络(Pre-activationResidual Network)的做法。
- 在最后一个自注意力块(Self-Attention Block)之后添加了一个额外的层归一化层。进一步增强了模型的稳定性和性能。
- 这种缩放方法有助于平衡不同深度的残差路径上的信号,使得模型在训练初期更加稳定,减少梯度消失和梯度爆炸的风险。
3.2 手写GPT2
import math
import torch
import torch.nn as nn
from torch.nn import functional as F
from dataclasses import dataclass
import tiktoken
@dataclass
class GPTConfig:
block_size: int = 1024
vocab_size: int = 50257
n_layer: int = 12
n_head: int = 12
n_embd: int = 768
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super(CausalSelfAttention, self).__init__()
# 确保嵌入维度可以被注意力头整除
assert config.n_embd % config.n_head == 0
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd)
self.c_proj = nn.Linear(config.n_embd, config.n_embd)
self.n_head = config.n_head
self.n_embd = config.n_embd
# 做一个mask
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x):
# bs, seq_len, embd
B, T, C = x.size()
qkv = self.c_attn(x)
q, k, v = qkv.split(self.n_embd, dim=2)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:, :, :T, :T] == 0 , float("-inf"))
att = F.softmax(att, dim=-1)
y = att @ v # (B, nh, T, T) X (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C)
y = self.c_proj(y)
return y
class MLP(nn.Module):
def __init__(self, config):
super(MLP, self).__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd)
self.gelu = nn.GELU(approximate="tanh")
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd)
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
return x
class Block(nn.Module):
def __init__(self, config):
super(Block, self).__init__()
self.ln_1 = nn.LayerNorm(config.n_embd)
self.attn = CausalSelfAttention(config)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = MLP(config)
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
class GPT(nn.Module):
def __init__(self, config):
super(GPT, self).__init__()
self.config = config
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = nn.LayerNorm(config.n_embd),
))
# softmax前的linear层
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
def forward(self, idx):
B, T = idx.size()
assert T <= self.config.block_size, f"不能让seq_len {T} 大于 block_size {self.config.block_size}"
pos = torch.arange(0, T, dtype=torch.long, device=idx.device)
pos_emb = self.transformer.wpe(pos) # (T, n_embd)
tok_emb = self.transformer.wte(idx) # (B, T, n_embd)
x = pos_emb + tok_emb
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
logits = self.lm_head(x) # (B, T, vocab_size)
return logits
@classmethod
def from_pretrained(cls, model_type):
assert model_type in {"gpt2", "gpt2-medium", "gpt2-large", "gpt2-xl"}
from transformers import GPT2LMHeadModel
print("从预训练的GPT中加载模型:", model_type)
# 根据模型类型确认参数
config_args = {
"gpt2": dict(n_layer=12, n_head=12, n_embd=768), # 124M param
"gpt2-medium": dict(n_layer=24, n_head=16, n_embd=1024), # 350M param
"gpt2-large": dict(n_layer=36, n_head=20, n_embd=1280), # 774M param
"gpt2-xl": dict(n_layer=48, n_head=25, n_embd=1600), # 1558M param
}[model_type]
config_args["vocab_size"] = 50257
config_args["block_size"] = 1024
# 创建GPT模型
config = GPTConfig(**config_args)
model = GPT(config)
sd = model.state_dict()
sd_keys = sd.keys()
sd_keys = [k for k in sd_keys if not k.endswith(".attn.bias")]
# 从huggingface/transformers模型中初始化
model_hf = GPT2LMHeadModel.from_pretrained(model_type)
sd_hf = model_hf.state_dict()
# 将参数逐一对齐并复制
sd_keys_hf = sd_hf.keys()
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith(".attn.masked_bias")]
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith(".attn.bias")]
transposed = ["attn.c_attn.weight", "attn.c_proj.weight", "mlp.c_fc.weight", "mlp.c_proj.weight"]
assert len(sd_keys_hf) == len(sd_keys), f"键不匹配, {len(sd_keys_hf)} != {len(sd_keys)}"
for k in sd_keys_hf:
# openai使用了一个叫conv1d的模型,功能与linear一致,我们使用linear,需要单独处理它。需要转置
if any(k.endswith(w) for w in transposed):
assert sd_hf[k].shape[::-1] == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k].t())
else: # 其余的直接复制
assert sd_hf[k].shape == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k])
return model
model = GPT.from_pretrained("gpt2")
print("没报错!!!")
model.eval()
model.to("cpu")
#model.to("gpu")
enc = tiktoken.get_encoding("gpt2")
tokens = enc.encode("Hello, I'm a language model")
tokens = torch.tensor(tokens, dtype=torch.long)
print(tokens)
tokens = tokens.unsqueeze(0)
x = tokens.to("cpu")
#x = tokens.to("gpu")
torch.manual_seed(42)
torch.cuda.manual_seed(42)
max_length = 30
while x.size(1) < max_length:
with torch.no_grad():
logits = model(x)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
topk_probs, topk_indices = torch.topk(probs, 50, dim=-1)
ix = torch.multinomial(topk_probs, 1)
xcol = torch.gather(topk_indices, -1, ix)
x = torch.cat((x, xcol), dim=1)
tokens = x[0, :max_length].tolist()
decoded = enc.decode(tokens)
print(">", decoded)
运行效果:
从预训练的GPT中加载模型: gpt2
没报错!!!
tensor([15496, 11, 314, 1101, 257, 3303, 2746])
> Hello, I'm a language modeler, and for my part, being a language modeler and a compiler optimizer, all these things help me