Tokenizer(分词器)是NLP中的一个基本组件,其作用是将输入的文本序列分解为更小的片段(称为"token"),Tokenizer这是将文本转化为结构化数据的第一步。
1.Tokenizer
Tokenizer,分词器,用于将输入的文本字符串拆分为有意义的标记(tokens),这些标记可以是单词、子词、字符或符号。
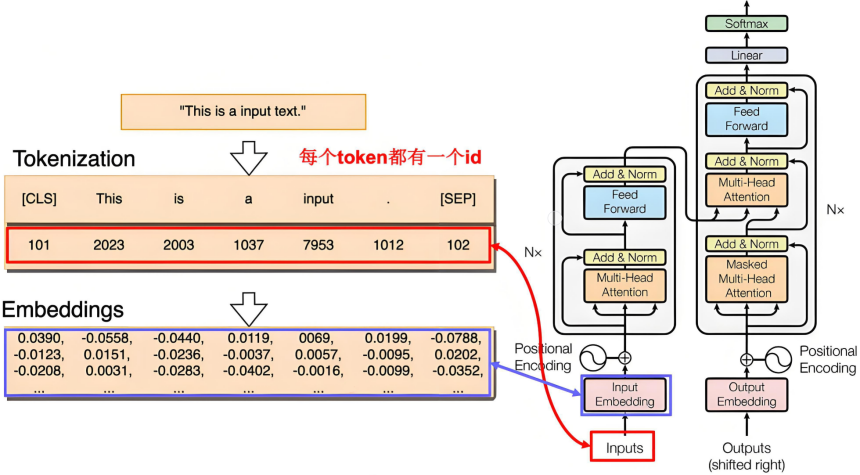
将文本序列转化为数字序列,也就是==token编号==
直观感受:https://huggingface.co/spaces/Xenova/the-tokenizer-playground
2.Tokenizer实现
Tokenizer的实现通常按粒度可分为三大类:Word-based、Character-based、Subword-based
2.1. Word-based Tokenizer(基于单词的分词器)
粒度:以单词为单位进行分割。 工作方式:将句子拆分为一个个独立的单词。
例子: 输入:"我昨天去超市买了苹果。" 分词结果:["我", "昨天", "去", "超市", "买", "了", "苹果", "。"]
优点: - 直观,符合人类的语言习惯。 - 保留了单词的完整语义。
缺点: - 对于未知单词(OOV,Out-of-Vocabulary)无法处理,比如生僻词或拼写错误。 - 在处理语言中没有明确单词边界的情况(如中文)时,需要额外的分词工具。
适用场景:适用于词汇表固定且单词边界明确的语言(如英文)。
2.2. Character-based Tokenizer(基于字符的分词器)
粒度:以单个字符为单位进行分割。 工作方式:将句子拆分为一个个字符。
例子: 输入:"我昨天去超市买了苹果。" 分词结果:["我", "昨", "天", "去", "超", "市", "买", "了", "苹", "果", "。"]
优点: - 不会遇到未知单词的问题,因为所有字符都在词汇表中。 - 适用于没有明确单词边界的语言(如中文)。
缺点: - 丢失了单词级别的语义信息。 - 需要处理大量字符,模型复杂度可能增加。
适用场景:适用于字符级别的任务(如拼写检查)或没有明确单词边界的语言。
2.3. Subword-based Tokenizer(基于子词的分词器)
粒度:以介于单词和字符之间的子词(subword)为单位进行分割。 工作方式:将单词拆分为更小的单元(子词),这些子词可以是前缀、后缀或词根。
例子: 输入:"unhappiness" 分词结果:["un", "happi", "ness"] 输入:"我昨天去超市买了苹果。" 分词结果:["我", "昨天", "去", "超市", "买", "了", "苹果", "。"](中文中可能不需要子词分割)
优点: - 平衡了单词和字符的优缺点。 - 可以处理未知单词(通过拆分为已知的子词)。 - 适用于多语言和词汇表较大的场景。
缺点: - 需要训练子词分割规则(如BPE、WordPiece)。 - 分词规则可能因语言或数据集而异。
适用场景:适用于需要处理大量未知单词或多语言的场景(如机器翻译、预训练模型)。
总结对比:
| 分类 | 粒度 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Word-based | 单词 | 直观,保留单词语义 | 无法处理未知单词 | 固定词汇表的语言(如英文) |
| Character-based | 字符 | 不会遇到未知单词问题 | 丢失单词语义,模型复杂度高 | 没有明确单词边界的语言(如中文) |
| Subword-based | 子词 | 平衡单词和字符的优缺点,处理未知单词 | 需要训练分词规则 | 多语言、未知单词较多的场景(如机器翻译) |
通俗比喻:
- Word-based:像把一个句子拆成一块块积木,每块积木是一个单词。
- Character-based:像把积木再拆成一个个小颗粒(字符)。
- Subword-based:像把积木拆成小块,但比整块积木小,比颗粒大(子词)。
3.Pytorch实现分词器
以下是一个使用 PyTorch实现的中文分词器的简单例子。这里我们使用基于词典的分词算法。这种算法通过构建一个词典,包含常见的中文词组,然后在分词时根据词典中的词组进行匹配。以下是基于词典的分词算法的实现。
import re
# 示例中文语料
corpus = [
"我昨天去超市买了苹果。",
"苹果很好吃。",
"超市的东西很便宜。",
"我明天还会去超市。",
"今天天气很好。",
"我打算买一些水果。",
"苹果、香蕉和橙子都是水果。",
"超市里有很多水果。",
"我昨天买了很多东西。",
"今天我要去上班。",
"超市的苹果很便宜。",
"我去超市买水果。",
"超市里的东西很多。",
"超市很大,有很多商品。",
"我在超市买了很多水果。",
"超市的水果很新鲜。",
"我经常去超市购物。",
"超市的环境很好。",
"超市的服务态度很好。",
"超市的商品种类很多。"
]
# 构建词典
word_dict = set()
for sentence in corpus:
words = re.findall(r'[\u4e00-\u9fa5]+', sentence) # 提取中文词组
for word in words:
word_dict.add(word)
# 添加常见词组
word_dict.update(
["超市", "苹果", "香蕉", "橙子", "水果", "东西", "天气", "上班", "买", "很多", "昨天", "便宜", "新鲜", "环境",
"服务态度", "商品种类"])
# 分词函数
def tokenize(sentence, word_dict):
tokens = []
i = 0
while i < len(sentence):
max_len = min(5, len(sentence) - i) # 尝试匹配最长的词
found = False
for j in range(max_len, 0, -1):
subword = sentence[i:i + j]
if subword in word_dict:
tokens.append(subword)
i += j
found = True
break
if not found:
tokens.append(sentence[i])
i += 1
return tokens
# 测试
test_sentence = "我昨天去超市买了苹果。"
tokens = tokenize(test_sentence, word_dict)
print("输入句子:", test_sentence)
print("分词结果:", tokens)
运行效果:
输入句子: 我昨天去超市买了苹果。
分词结果: ['我', '昨天', '去', '超市', '买', '了', '苹果', '。']
当然实际工作实践中,实现中文分词的最佳手段是使用Hugging Face的Transformers库,Hugging Face的transformers库提供了许多预训练的模型,包括针对中文的模型,如bert-base-chinese。你可以通过以下步骤使用这些模型进行中文分词:
from transformers import BertTokenizer, BertModel
# 加载分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
text = "我昨天去超市买了苹果。"
# 对文本进行分词
tokens = tokenizer.tokenize(text)
print(tokens)
4.常用的中文分词器
常用的中文分词技术及工具包括以下几种:
- jieba:支持精确模式、全模式和搜索引擎模式,基于前缀词典和 HMM 模型,适合文本分析和搜索引擎分词。
- HanLP:集成了词典与统计模型,支持多任务(如词性标注、命名实体识别),并提供 CRF 和感知机词法分析。
- LAC:百度开发的分词工具,支持分词和词性标注,适用于多种应用场景。
- SnowNLP:功能全面,支持分词、词性标注、情感分析等,基于字符生成模型。
- THULAC:清华大学开发的工具,结合 CRF 和深度学习,支持分词和词性标注,准确率高。
- NLPIR:支持分词和关键词提取,适合文本分析。
- FoolNLTK:基于 BiLSTM-CRF 模型,支持分词、词性标注和命名实体识别,准确率高。
- LTP:基于机器学习框架,支持分词、词性标注、命名实体识别等任务。
- Jcseg:轻量级 Java 分词器,支持多种切分模式,适合不同应用场景。
- sego:高效分词工具,支持多种分词模式。
- Ansj 中文分词:基于 HMM 和词典的分词工具。
- PkuSeg:支持多领域分词,提供新闻、医药、旅游等领域的预训练模型。
这些工具各有特点,适用于不同的应用场景和需求。
4.1.bert-base-chinese分词效果:
from transformers import BertTokenizer, BertModel
# 加载分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
text = "我昨天去超市买了苹果。"
# 对文本进行分词
tokens = tokenizer.tokenize(text)
print(tokens)
运行效果:
['我', '昨', '天', '去', '超', '市', '买', '了', '苹', '果', '。']
4.2.jieba分词器效果:
import jieba
sentence = "我昨天去超市买了苹果。"
result = jieba.lcut(sentence)
print(result)
运行效果:
['我', '昨天', '去', '超市', '买', '了', '苹果', '。']
4.3 HanLP分词器效果:
import hanlp
# 加载分词模型
tokenizer = hanlp.load('FINE_ELECTRA_SMALL_ZH') # 使用推荐的分词模型
# 对句子进行分词
sentence = "我昨天去超市买了苹果。"
result = tokenizer(sentence)
print(result)
运行效果:
['我', '昨天', '去', '超市', '买', '了', '苹果', '。']
4.4. LAC分词器效果
首先安装依赖:
pip install LAC
pip install paddlepaddle==2.5.2
pip install lac
from LAC import LAC
# 装载分词模型
lac = LAC(mode='seg')
# 对句子进行分词
sentence = "我昨天去超市买了苹果。"
seg_result = lac.run(sentence)
print(seg_result)
运行效果:
['我', '昨天', '去', '超市', '买', '了', '苹果', '。']
4.5.SnowNLP分词器效果:
from snownlp import SnowNLP
# 对句子进行分词
sentence = "我昨天去超市买了苹果。"
s = SnowNLP(sentence)
seg_result = s.words
print(seg_result)
运行效果:
['我', '昨天', '去', '超市', '买', '了', '苹果', '。']