Transformers中的注意力机制是深度学习中的一种重要技术,尤其在自然语言处理(NLP)领域有着广泛的应用。注意力机制的核心思想是让模型能够有选择性地关注输入序列中的不同部分,为输入序列的各个部分分配不同的权重,以此来突出对任务更关键的信息。
1.注意力机制
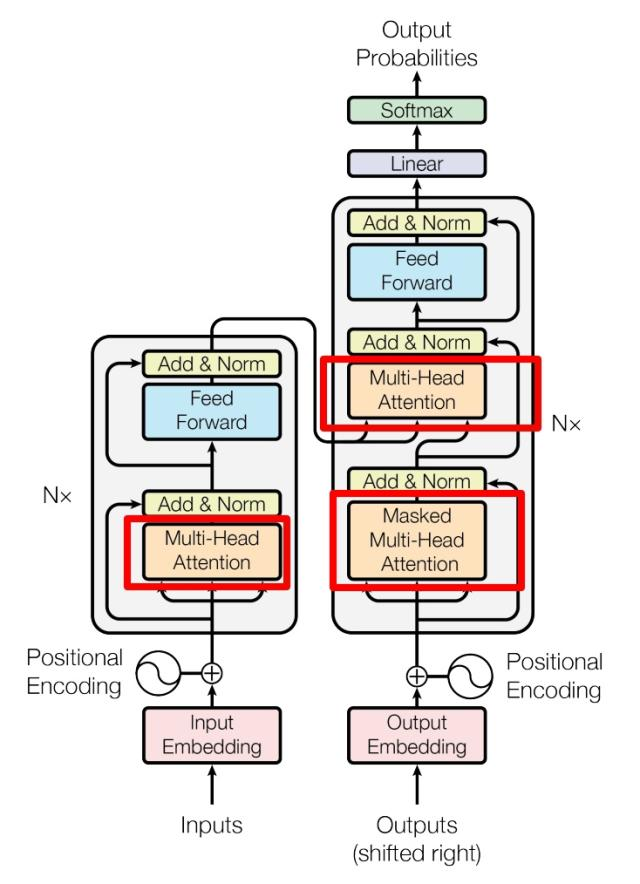
上图是论文中 Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
注意力机制(Attention Mechanism)是Transformer模型的核心技术,它的本质是帮助模型在处理语言时动态地关注最重要的部分,而不是机械地逐词处理。用通俗的话来说,它就像人类在阅读或思考时会“聚焦”某些关键信息,而忽略不重要的内容。
想象你在读一句话:“我昨天去超市买了苹果。” 你的大脑会自动关注“昨天”、“超市”、“买”、“苹果”这些词,因为它们是理解这句话的关键。而“我”、“了”这些词虽然重要,但它们的作用相对次要。注意力机制就是模仿这种“聚焦关键信息”的能力。
1.1 注意力机制的工作原理:
- 输入句子: 模型会把句子中的每个词都看作一个“节点”,比如“我”、“昨天”、“超市”、“买”、“苹果”。
- 计算“相关性”: 模型会问自己:“每个词和其他词之间的关系有多重要?” 比如,“买”和“苹果”关系很近,因为“买”的动作直接作用于“苹果”;而“昨天”和“买”也有关系,因为“昨天”是时间背景。
- 分配“权重”: 模型会给每个词分配一个“重要性分数”,分数高的词会被更多关注。比如,“买”和“苹果”可能会得到更高的分数,而“了”可能得分较低。
- 生成结果: 模型根据这些权重,动态调整对每个词的关注程度,从而更高效地理解句子的意思。
1.2 为什么注意力机制很重要
传统的语言处理模型(比如RNN)是逐词处理的,就像一个厨师只能一道菜一道菜地做,效率低且容易忽略全局关系。而注意力机制可以同时处理所有词,并动态调整关注重点,就像一个厨师能同时做几道菜,效率高且能抓住关键。
总结:
注意力机制的核心是动态地关注重要的部分,让模型在处理语言时更像人类:快速抓住关键信息,而不是机械地逐词处理。这种能力让Transformer模型在翻译、问答、写文章等任务中表现得非常出色!
2.注意力机制算法的计算过程
自注意力的计算:从每个编码器的输入向量(每个单词的词向量,即Embedding,可以是任意形式的词向量,比如说word2vec,GloVe,one-hot编码)
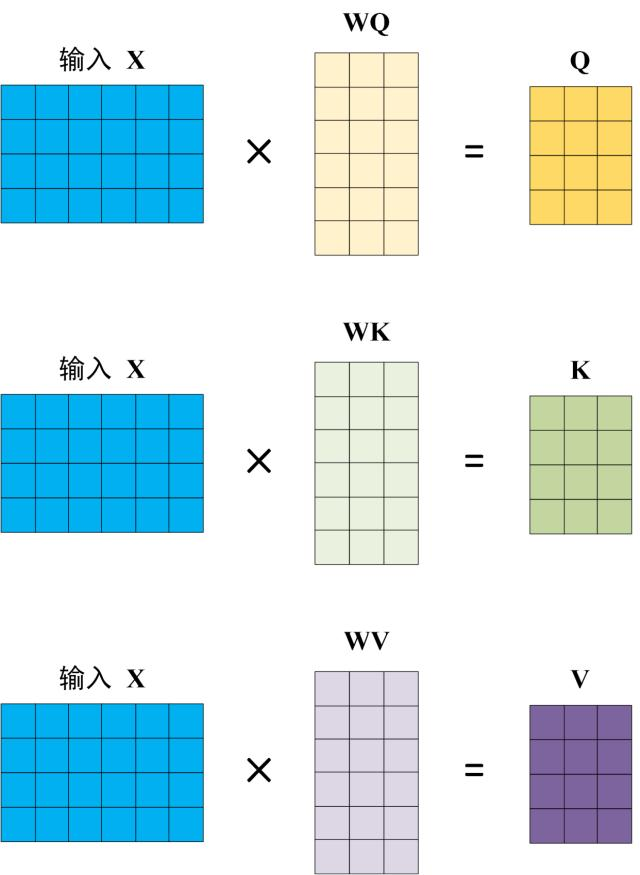
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。注意:新向量Q,K,V在维度上通常比词向量更低(512->64)
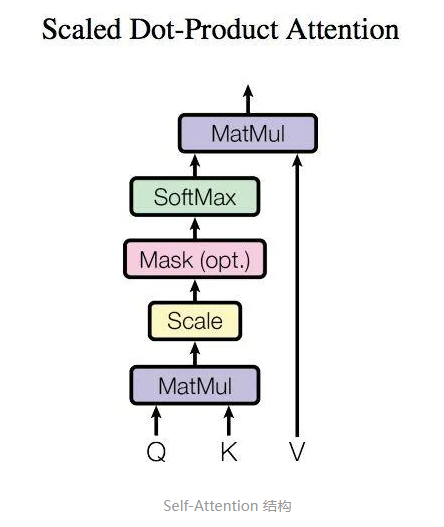
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:

论文中使用的键向量的维数是64,即dk=64,所以是除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值,这样做是为了防止内积过大。),然后通过softmax传递结果。随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。
上面的计算过程看似繁琐,我们用“我昨天去超市买了苹果。”这句话来通俗易懂地解释注意力机制的算法步骤。假设我们想通过注意力机制来理解这句话中“买”这个词的上下文关系。
注意力机制的算法步骤:
- 输入句子的表示 把句子中的每个词转换成一个向量(数字表示)。比如: “我” → 向量A “昨天” → 向量B “去” → 向量C “超市” → 向量D “买” → 向量E “了” → 向量F “苹果” → 向量G
- 计算“买”和其他词的相关性 注意力机制会问:“买”和其他词之间的关系有多重要? 模型会用“买”的向量(E)分别和句子中其他词的向量(A、B、C、D、F、G)进行比较,计算出一个“相关性分数”。 比如: “买”和“我”的相关性 → 分数1 “买”和“昨天”的相关性 → 分数2 “买”和“超市”的相关性 → 分数3 “买”和“苹果”的相关性 → 分数4 以此类推。
- 分配权重 根据相关性分数,给每个词分配一个权重(分数越高,权重越大)。 比如: “买”和“苹果”的相关性很高,权重可能是0.6 “买”和“超市”的相关性较高,权重可能是0.3 “买”和“昨天”的相关性较低,权重可能是0.1 其他词的权重可能更低。
- 归一化权重 把所有权重加起来,让它们的总和为1(用Softmax函数实现)。 比如: “苹果”的权重 → 0.6 / (0.6 + 0.3 + 0.1 + ...) = 最终权重1 “超市”的权重 → 0.3 / 总和 = 最终权重2 以此类推。
- 加权求和 根据归一化后的权重,对每个词的向量进行加权求和。 比如: 最终“买”的表示 = (权重1 × 苹果的向量) + (权重2 × 超市的向量) + ... 这个加权和就是“买”在句子中的上下文表示。
总结: 注意力机制通过计算“买”和其他词的相关性,动态地给每个词分配权重,最后生成一个综合的表示。这个表示会更关注“苹果”和“超市”等和“买”关系密切的词,而忽略“了”等次要词。这样,模型就能更好地理解“买”在句子中的具体含义。
通俗比喻: 就像你在读这句话时,大脑会自动关注“买”和“苹果”、“超市”这些词,而不会过多在意“了”这样的词。注意力机制就是模仿了这种“聚焦关键信息”的能力!
3.注意力机制的三个核心部分
注意力机制的三个核心部分是 Q(Query,查询)、K(Key,键) 和 V(Value,值)。以下用通俗易懂的方式解释它们的作用和关系。
1. Q(Query,查询)
Q 可以理解为“你当前在关注什么”。它是你想要找到答案的“问题”或者“目标”。 比如,你在图书馆找书时,你的“查询”可能是“我想找一本关于人工智能的书”。 在注意力机制中,Q 是一个向量,表示当前需要关注的重点信息。
2. K(Key,键)
K 是“所有可能的答案的标签”或者“线索”。它是用来匹配 Q 的。 继续用图书馆的例子,K 就是书架上所有书的标题或关键词。 在注意力机制中,K 是一个向量,表示输入数据中每个部分的“特征”或“标识”。
3. V(Value,值)
V 是“实际的内容”或者“答案”。它是最终你想要提取的信息。 在图书馆的例子中,V 就是书的具体内容。 在注意力机制中,V 是一个向量,表示输入数据中每个部分的具体信息。
Q、K、V 的关系
注意力机制的核心是通过 Q 和 K 的匹配,找到最相关的 V。
具体来说: - Q 和 K 的匹配:Q 和 K 通过某种计算(通常是点积)来判断它们的相似性。相似度越高,说明 Q 和 K 的关系越密切。 - 权重分配:根据 Q 和 K 的相似度,给每个 K 对应的 V 分配一个权重(权重越高,说明这个 V 越重要)。 - 加权求和:最后,根据权重对所有的 V 进行加权求和,得到最终的输出。
举个例子:聊天机器人 假设你正在和一个聊天机器人对话,你说:“今天天气怎么样?”
- Q:是“今天天气怎么样?”这个查询。
- K:是机器人记忆中所有与“天气”相关的关键词(比如“晴天”、“下雨”、“温度”等)。
- V:是这些关键词对应的具体信息(比如“今天北京是晴天,温度25℃”)。
机器人会通过 Q 和 K 的匹配,找到最相关的关键词(比如“天气”),然后根据 V 提供具体的答案。
为什么需要 Q、K、V?
Q、K、V 的设计让模型能够动态地关注输入中最重要的部分,而不是平等地处理所有输入。这种机制特别适合处理序列数据(比如句子、时间序列等),因为它可以让模型在处理每个位置时,自动选择与当前任务最相关的信息。
总结:
Q:是你当前关注的重点(查询)。 K:是所有可能的线索(键)。 V:是线索对应的实际内容(值)。 注意力机制通过 Q 和 K 的匹配,找到最相关的 V,并根据权重输出结果。
4.Multi-Head Attention(多头注意力机制)
上一步,我们已经知道怎么通过 Self-Attention 计算得到输出矩阵 Z,而 Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是论文中 Multi-Head Attention 的结构图。
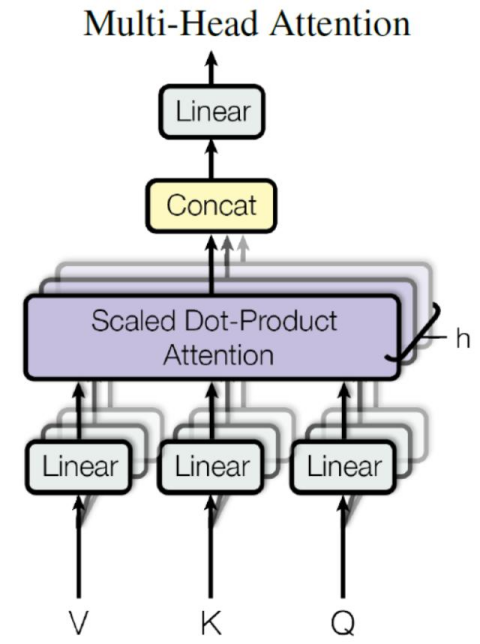
从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。下图是 h=8 时候的情况,此时会得到 8 个输出矩阵Z。
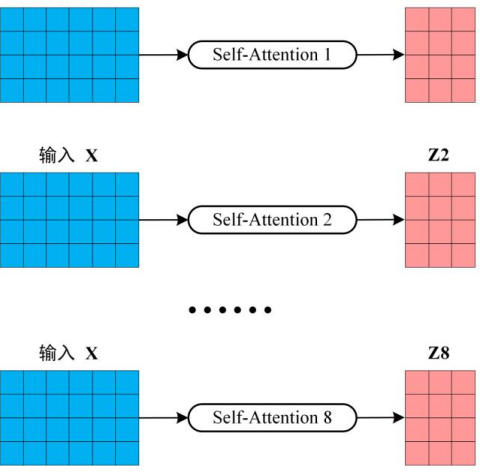
得到8个输出矩阵z1到z8之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。
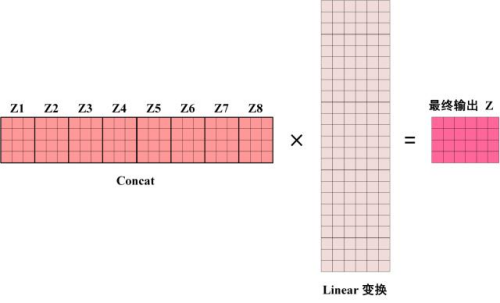
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。