GRU
Gated Recurrent Unit门控循环单元
GRU(Gated Recurrent Unit,门控循环单元)是一种循环神经网络(RNN)的变体,旨在处理序列数据。GRU在LSTM(Long Short-Term Memory,长短期记忆网络)的基础上进行了简化,引入了更少的参数量和结构复杂度,通过使用门控机制有效解决了传统RNN存在的梯度消失和梯度爆炸问题,尤其适合处理长时间依赖的数据。
1.GRU(Gated Recurrent Unit,门控循环单元)
GRU(Gated Recurrent Unit): GRU可以被看作是LSTM的简化版。GRU与LSTM不同,GRU的结构相对简单,仅包含两个门(更新门和重置门)而不是三个门(输入门、遗忘门和输出门)。GRU的核心组件是更新门和重置门用于控制信息的流动,但省略了LSTM中的单独记忆单元。相比LSTM,GRU拥有更少的参数,因此计算效率更高,通常在一些任务上可以获得相近甚至更好的效果。
2.GRU网络结构
LSTM与GRU网络结构对比如下图所示:
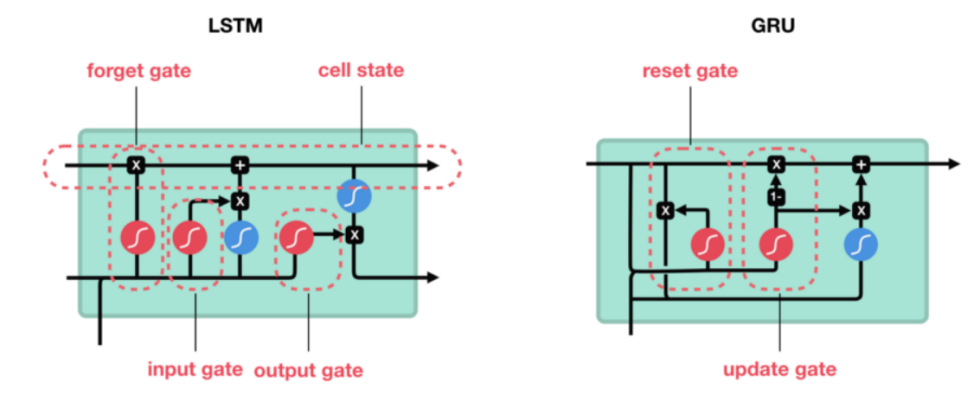
GRU的核心组件:更新门和重置门
更新门(Update Gate):
- 更新门的作用是决定当前时间步的隐藏状态需要保留多少前一个时间步的信息。
- 更新门的输出值介于0和1之间,值越大表示保留的过去信息越多,值越小则意味着更多地依赖于当前输入的信息。
重置门(Reset Gate)
- 重置门决定了前一时间步的隐藏状态在多大程度上被忽略。
- 当重置门的输出接近0时,网络倾向于“忘记”前一时间步的信息,仅依赖于当前输入;而当输出接近1时,前一时间步的信息将被更多地保留。
3.GRU与LSTM对比
| 特性 | GRU | LSTM |
|---|---|---|
| 结构 | 两个门(更新门和重置门) | 三个门(输入门、遗忘门、输出门) |
| 参数数量 | 较少,计算效率更高 | 较多,计算成本较高 |
| 记忆机制 | 没有独立的记忆单元 | 有独立的记忆单元 |
| 适用场景 | 中短期依赖任务,计算量较小 | 长时间依赖任务,较强的记忆能力 |
| 优点 | 结构简单、计算效率高、训练速度快 | 能够处理复杂的长时间依赖关系 |
| 缺点 | 长时间记忆能力略逊于LSTM | 计算复杂度较高,训练速度较慢 |
4.Pytorch实现GRU
以下是使用PyTorch实现GRU模型的一个简单例子,以"我 喜欢 学习 人工智能"这句话为例,以“学习”为中心词,推理"学习"后最可能出现的上下文词汇。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
# 示例句子
sentence = "我 喜欢 学习 人工智能"
words = sentence.split()
# 构建词汇表
vocab = list(set(words))
word_to_idx = {word: idx for idx, word in enumerate(vocab)}
idx_to_word = {idx: word for idx, word in enumerate(vocab)}
vocab_size = len(vocab)
# 生成训练数据
train_data = []
context_window = 1
for i in range(context_window, len(words) - context_window):
center_word = word_to_idx[words[i]]
context_words = []
for j in range(i - context_window, i + context_window + 1):
if j != i:
context_words.append(word_to_idx[words[j]])
for context_word in context_words:
train_data.append((center_word, context_word))
# 定义GRU模型
class GRUModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim):
super(GRUModel, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embed_dim)
self.gru = nn.GRU(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
embeds = self.embeddings(x)
gru_out, _ = self.gru(embeds)
output = self.fc(gru_out)
return output
# 超参数
embed_dim = 10
hidden_dim = 10
num_epochs = 1000
learning_rate = 0.001
# 创建数据集和数据加载器
class WordDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
center_word, context_word = self.data[idx]
return torch.LongTensor([center_word]), torch.LongTensor([context_word])
dataset = WordDataset(train_data)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
# 初始化模型、损失函数和优化器
model = GRUModel(vocab_size, embed_dim, hidden_dim)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
for epoch in range(num_epochs):
total_loss = 0
for inputs, targets in dataloader:
outputs = model(inputs)
loss = criterion(outputs.squeeze(1), targets.squeeze(1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {total_loss / len(dataloader):.4f}')
# 预测函数
def predict(center_word, k=2):
model.eval()
with torch.no_grad():
input_word = torch.LongTensor([word_to_idx[center_word]])
output = model(input_word)
probabilities = torch.softmax(output, dim=1)
topk_probs, topk_indices = torch.topk(probabilities, k, dim=1)
predicted_words = [idx_to_word[idx.item()] for idx in topk_indices[0]]
return predicted_words, topk_probs[0].tolist()
# 验证结果(以“学习”为中心词进行预测)
print("\n模型预测结果:")
center_word = "学习"
predicted_words, probabilities = predict(center_word, k=2)
print(f"中心词: '{center_word}', 预测上下文词: {predicted_words} (概率: {probabilities})")
运行效果:
Epoch [10/1000], Loss: 1.3963
...
Epoch [1000/1000], Loss: 0.6948
模型预测结果:
中心词: '学习', 预测上下文词: ['喜欢', '人工智能'] (概率: [0.49934545159339905, 0.4990909695625305])