BiLSTM
BiLSTM
双向LSTM(Bidirectional LSTM) 是LSTM的一种改进型结构,能够同时利用序列数据的前向和后向信息。
1.BiLSTM(Bidirectional LSTM)
双向性:BiLSTM 通过在输入序列的两个方向上进行处理,即前向和后向,使得模型能够同时捕捉到当前位置前后的上下文信息。这样,模型就能够更全面地理解整个句子的语境,从而更准确地预测下一个单词。
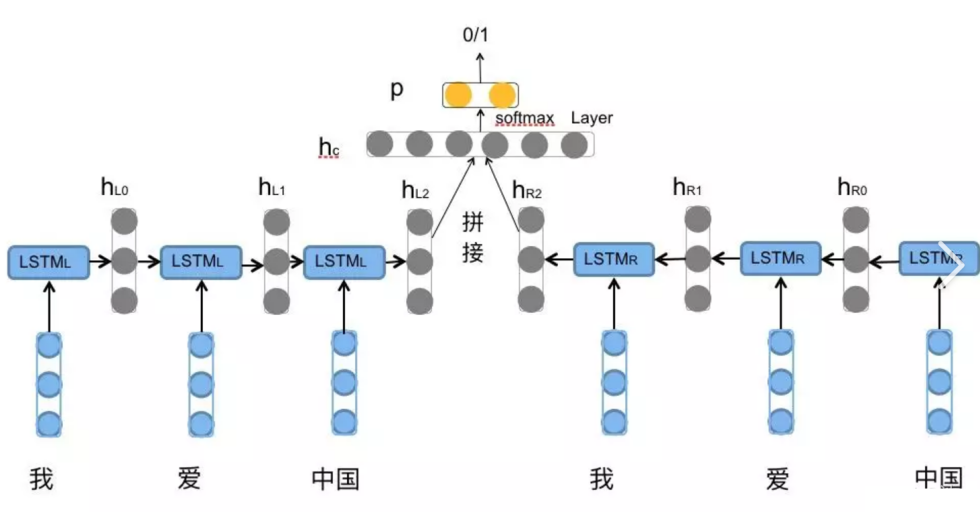
让我们用一个语句的例子来说明LSTM和BiLSTM的区别: 假设我们有以下句子: “我正在学习人工智能,因为它很有趣。”
2.BiLSTM 与 LSTM 的对比
使用LSTM:
LSTM会从左到右逐个处理单词,每次只考虑之前的上下文。例如:
- 处理“我”时,没有之前的上下文。
- 处理“正在”时,只考虑“我”。
- 处理“学习”时,考虑“我”和“正在”。
- 处理“人工智能”时,考虑“我”、“正在”和“学习”。
- 处理“因为”时,考虑前面的单词。
- 处理“它”时,考虑前面的单词。
- 处理“很”时,考虑前面的单词。
- 处理“有趣”时,考虑前面的单词。
LSTM只能利用单词左侧的上下文信息,无法利用右侧的上下文信息。因此,它可能无法完全理解句子的整体语义,尤其是当右侧的上下文对理解当前单词很重要时。
使用BiLSTM:
BiLSTM同时从左到右和从右到左处理单词,因此可以同时利用左侧和右侧的上下文信息。例如:
- 处理“我”时,BiLSTM会同时考虑右侧的“正在”。
- 处理“正在”时,同时考虑左侧的“我”和右侧的“学习”。
- 处理“学习”时,同时考虑左侧的“正在”和右侧的“人工智能”。
- 处理“人工智能”时,同时考虑左侧的“学习”和右侧的“因为”。
- 处理“因为”时,同时考虑左侧的“人工智能”和右侧的“它”。
- 处理“它”时,同时考虑左侧的“因为”和右侧的“很”。
- 处理“很”时,同时考虑左侧的“它”和右侧的“有趣”。
- 处理“有趣”时,同时考虑左侧的“很”。
BiLSTM能够同时利用左侧和右侧的上下文信息,因此可以更全面地理解句子的整体语义。这种双向信息利用使得BiLSTM在处理需要上下文信息的任务时表现得更好,例如情感分析、命名实体识别等。
总结:
- LSTM:只能利用左侧的上下文信息,适合处理单向依赖的任务。
- BiLSTM:同时利用左侧和右侧的上下文信息,适合处理需要全面上下文理解的任务。
- BiLSTM 由于同时运行两个 LSTM,其模型参数数量大约是 LSTM 的两倍(假设其他条件相同),这在一定程度上增加了计算量和训练时间。然而,在很多情况下,BiLSTM 凭借其更强大的信息捕捉能力,能够在较少的训练轮次内达到较好的效果,从整体的性能提升和资源消耗的综合考量来看,在许多任务中仍然具有很高的性价比。
- LSTM 适用于一些对单向信息依赖较强,或者数据规模较小、计算资源有限的场景。BiLSTM 则在自然语言处理中的文本分类、情感分析、命名实体识别、机器翻译,以及语音识别、时间序列预测等需要充分利用前后文信息的任务中表现更为出色。
3.Pytorch实现BiLSTM
以下是使用PyTorch实现BiLSTM模型的一个简单例子,以"我 喜欢 学习 人工智能"这句话为例,以“学习”为中心词,推理"学习"后最可能出现的上下文词汇。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
# 示例句子
sentence = "我 喜欢 学习 人工智能"
words = sentence.split()
# 构建词汇表
vocab = list(set(words))
word_to_idx = {word: idx for idx, word in enumerate(vocab)}
idx_to_word = {idx: word for idx, word in enumerate(vocab)}
vocab_size = len(vocab)
# 生成训练数据
train_data = []
context_window = 1
for i in range(context_window, len(words) - context_window):
center_word = word_to_idx[words[i]]
context_words = []
for j in range(i - context_window, i + context_window + 1):
if j != i:
context_words.append(word_to_idx[words[j]])
for context_word in context_words:
train_data.append((center_word, context_word))
# 定义BiLSTM模型
class BiLSTMModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim):
super(BiLSTMModel, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True, bidirectional=True)
self.fc = nn.Linear(hidden_dim * 2, vocab_size)
def forward(self, x):
embeds = self.embeddings(x)
lstm_out, _ = self.lstm(embeds)
output = self.fc(lstm_out)
return output
# 超参数
embed_dim = 10
hidden_dim = 10
num_epochs = 1000
learning_rate = 0.001
# 创建数据集和数据加载器
class WordDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
center_word, context_word = self.data[idx]
return torch.LongTensor([center_word]), torch.LongTensor([context_word])
dataset = WordDataset(train_data)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
# 初始化模型、损失函数和优化器
model = BiLSTMModel(vocab_size, embed_dim, hidden_dim)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
for epoch in range(num_epochs):
total_loss = 0
for inputs, targets in dataloader:
outputs = model(inputs)
loss = criterion(outputs.squeeze(1), targets.squeeze(1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {total_loss / len(dataloader):.4f}')
# 预测函数
def predict(center_word, k=2):
model.eval()
with torch.no_grad():
input_word = torch.LongTensor([word_to_idx[center_word]])
output = model(input_word)
probabilities = torch.softmax(output, dim=1)
topk_probs, topk_indices = torch.topk(probabilities, k, dim=1)
predicted_words = [idx_to_word[idx.item()] for idx in topk_indices[0]]
return predicted_words, topk_probs[0].tolist()
# 验证结果(以“学习”为中心词进行预测)
print("\n模型预测结果:")
center_word = "学习"
predicted_words, probabilities = predict(center_word, k=2)
print(f"中心词: '{center_word}', 预测上下文词: {predicted_words} (概率: {probabilities})")
运行效果:
Epoch [10/1000], Loss: 1.3580
...
Epoch [1000/1000], Loss: 0.6942
模型预测结果:
中心词: '学习', 预测上下文词: ['喜欢', '人工智能'] (概率: [0.4995916187763214, 0.4993744194507599])