长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。在标准RNN中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。
1.为什么要设计LSTM
LSTM(长短期记忆网络)是RNN(循环神经网络)的一种改进版本,它在处理序列数据时具有显著的优势。以下是LSTM相比传统RNN的主要优势:
1. 解决梯度消失问题
RNN的局限性:==传统RNN在处理长序列数据时容易出现梯度消失或梯度爆炸问题==,导致模型无法有效学习长期依赖关系。 LSTM的优势:LSTM通过引入门控机制(输入门、遗忘门和输出门)和记忆单元(Cell State),能够更好地控制信息的流动,从而有效缓解梯度消失问题。记忆单元可以长期保留重要信息,而门控机制可以决定哪些信息需要保留或丢弃。
2. 更好地捕捉长期依赖关系
RNN的局限性:RNN在处理长序列时,早期的信息容易被遗忘,导致模型对长期依赖关系的建模能力较弱。 LSTM的优势:LSTM的记忆单元和门控机制使得它能够选择性地保留或丢弃信息,从而更好地捕捉序列中的长期依赖关系。例如,在语言模型中,LSTM可以更好地理解句子的上下文,而不仅仅是最近的几个词。
3. 更复杂的模式建模能力
RNN的局限性:RNN的简单结构限制了它对复杂模式的建模能力。 LSTM的优势:LSTM的门控机制和记忆单元使其能够建模更复杂的模式,包括周期性模式和非周期性模式。例如,在时间序列预测中,LSTM可以更好地捕捉季节性和趋势性变化。
4. 输出稳定性
RNN的局限性:RNN的输出可能会因为梯度问题而不稳定,导致模型在某些情况下表现不佳。 LSTM的优势:LSTM的门控机制和记忆单元设计使得其输出更加稳定,从而在长序列任务中表现更好。例如,在情感分析任务中,LSTM可以更稳定地预测文本的情感倾向。
5. 广泛的适用性
RNN的局限性:RNN在处理复杂序列任务时表现不佳,尤其是在需要长期记忆的场景中。 LSTM的优势:LSTM在许多序列任务中表现出色,包括自然语言处理(如机器翻译、文本生成)、时间序列预测(如股票价格预测)、语音识别等。其强大的建模能力使其成为处理复杂序列数据的首选模型。
总结:LSTM通过引入门控机制和记忆单元,解决了RNN在处理长序列数据时的梯度消失问题,能够更好地捕捉长期依赖关系,建模复杂模式,并在多种序列任务中表现出色。这些优势使得LSTM成为现代深度学习中处理序列数据的重要工具。
2.LSTM的网络结构
LSTM的核心改进点在于引入了记忆单元(Cell State)和一系列门控机制:
记忆单元(Cell State):LSTM通过引入一个长时间的记忆单元来存储重要的信息,并通过门控机制来控制信息的存储、遗忘和输出。这一设计使得LSTM能够在序列中“记住”关键信息,而非依赖单一的隐藏状态。
门控机制:LSTM的结构包含三个关键的门:输入门、遗忘门和输出门,这些门用于控制信息的流动和更新。
- 输入门:决定将当前输入的信息写入记忆单元的程度。
- 遗忘门:决定是否“遗忘”记忆单元中已存储的历史信息,从而允许模型有选择性地“清除”无关信息。
- 输出门:决定记忆单元中的信息在当前时间步的输出。
这些门控机制使得LSTM可以“选择性地”记忆和遗忘信息,从而有效避免了梯度消失和梯度爆炸的问题,能够更好地捕捉序列中的长时间依赖关系。因此,LSTM相较于普通RNN在处理长序列任务(如文本生成、语音识别、时间序列预测等)中表现更为出色。
LSTMs也具有这种链式结构,但是它的重复单元不同于标准RNN网络里的单元只有一个网络层,它的内部有四个网络层。由于 LSTM 有很多的变种,这里我们以最常见的 LSTM 为例讲述。LSTMs的结构如下图所示。
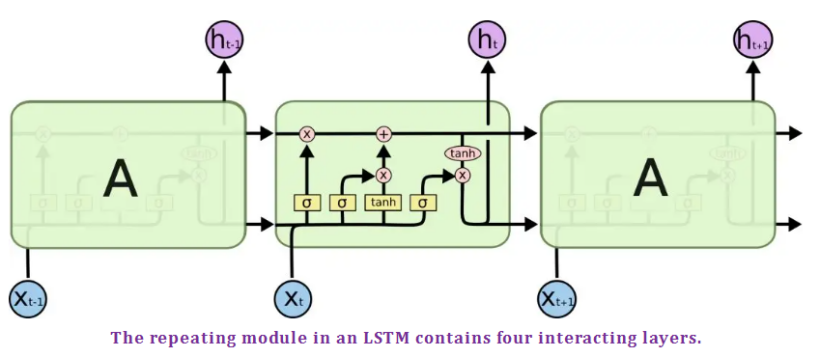
可以看到 LSTM 的结构要比 RNN 的复杂的多,在解释LSTMs的详细结构时先定义一下图中各个符号的含义,符号包括下面几种:
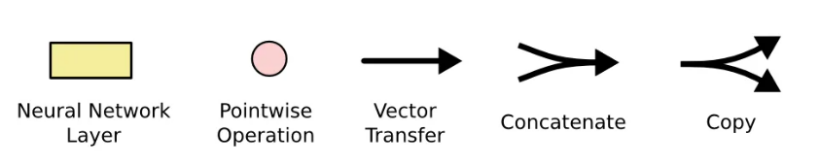
在上图中,黄色的盒子是神经网络层,粉红色的圆圈表示点操作,如向量加法乘法,单箭头表示数据流向,箭头合并表示向量的合并(concat)操作,箭头分叉表示向量的拷贝操作。
LSTMs的核心是单元状态(Cell State),用贯穿单元的水平线表示。单元状态有点像传送带。它沿着整个链一直走,只有一些微小的线性相互作用。信息很容易在不改变的情况下流动。单元状态如下图所示。
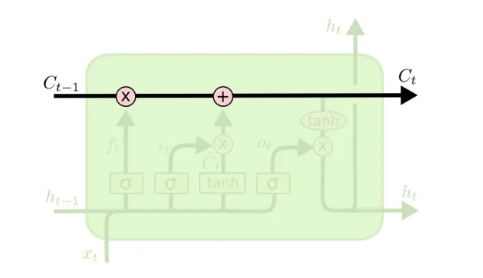
LSTM确实有能力将信息移除或添加到单元状态,并由称为gates的结构小心地进行调节。门(Gate)是一种选择性地让信息通过的方式。它们由一个Sigmod网络层和一个点乘运算组成。
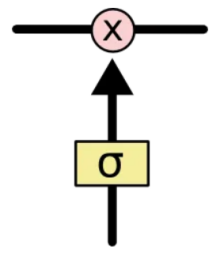
因为sigmoid层的输出是0-1的值,这代表有多少信息能够流过sigmoid层。0表示都不能通过,1表示都能通过。一个LSTM里面包含三个门来控制单元状态。这三个门分别称为忘记门、输入门和输出门。
2.1遗忘门(forget gate)
LSTM 的第一步就是决定细胞状态需要丢弃哪些信息。这部分操作是通过一个称为遗忘门的 sigmoid 单元来处理的。它通过 和 信息来输出一个 0-1 之间的向量,该向量里面的 0-1 值表示单元状态 中的哪些信息保留或丢弃多少。0表示不保留,1表示都保留。遗忘门如下图所示。
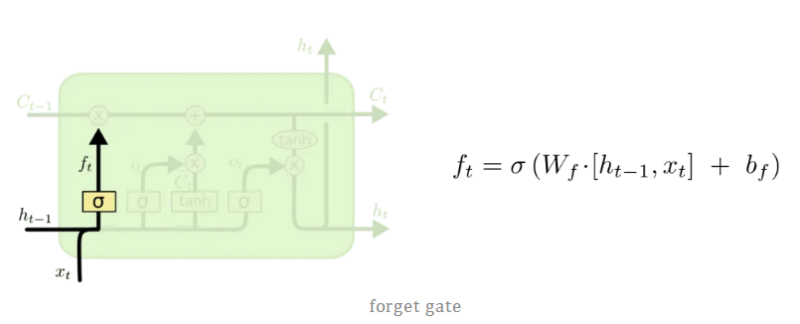
2.2 输入门(input gate)
要更新单元状态,我们需要输入门。首先,我们将先前的隐藏状态和当前输入传递给sigmod函数。这决定了通过将值转换为0到1来更新哪些值。0表示不重要,1表示重要。你还将隐藏状态和当前输入传递给tanh函数,将它们压缩到-1和1之间以帮助调节网络。然后将tanh输出与sigmod输出相乘。
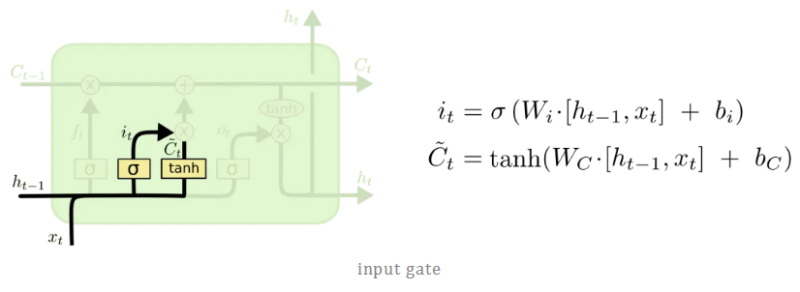
2.3 单元状态(cell state)
现在我们有足够的信息来计算单元状态。首先,单元状态逐点乘以遗忘向量。如果它乘以接近0的值,则有可能在单元状态中丢弃值。然后我们从输入门获取输出并进行逐点加法,将单元状态更新为神经网络发现相关的新值。这就得到了新的单元状态。
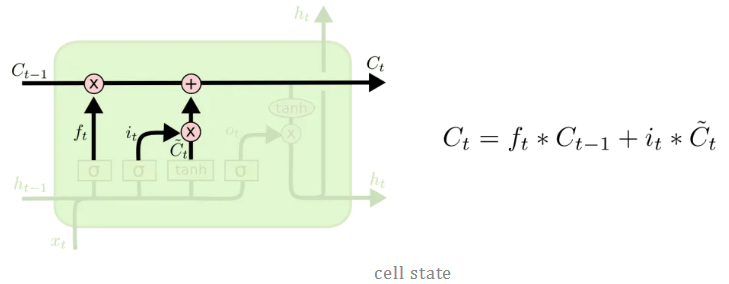
2.4 输出门(output gate)
最后我们有输出门。输出门决定下一个隐藏状态是什么。请记住,隐藏状态包含有关先前输入的信息。隐藏状态也用于预测。首先,我们将先前的隐藏状态和当前输入传递给sigmod函数。然后我们将新的单元状态传递给tanh函数。将tanh输出与sigmod输出相乘,以决定隐藏状态应携带的信息。它的输出是隐藏状态。然后将新的单元状态和新的隐藏状态传递到下一个时间步。
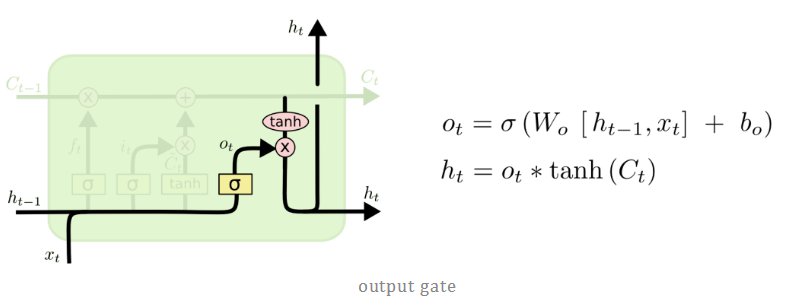
总结:
- 遗忘门决定了哪些内容与前面的时间步相关。
- 输入门决定了从当前时间步添加哪些信息。
- 输出门决定下一个隐藏状态应该是什么。
3.LSTM的实际应用
3.1 时间序列预测(如股票价格预测、气象预测)
LSTM在时间序列预测任务中表现优异,尤其适合那些依赖于历史数据的预测任务,如股票价格预测、气象预测等。在时间序列预测中,模型需要捕捉数据中的时间依赖关系,从而对未来的趋势进行准确预测。
- 股票价格预测:股票价格具有明显的时序依赖特性,LSTM可以利用历史价格数据学习到股价的变化规律,从而进行短期或长期的价格预测。
- 气象预测:气象数据具有季节性和周期性,通过LSTM网络可以提取这些规律,实现对未来气象的预测,如温度、湿度等指标。
在时间序列预测任务中,LSTM可以捕捉长时间依赖的特性,使其在数据噪声大、数据波动频繁的场景下也具有较好的预测效果。
3.2 自然语言处理(如文本生成、机器翻译)
LSTM在自然语言处理(NLP)任务中广泛应用,尤其在文本生成、机器翻译等任务中表现出色。语言是典型的序列化数据,句子中的每个词都依赖于上下文,这使得LSTM在这些任务中具有天然的优势。
- 文本生成:LSTM可以用于生成符合上下文语境的自然语言文本。通过输入一段文本,LSTM可以生成连续的文本,使得生成的句子具有连贯的语义。这种技术在自动写作、聊天机器人、对话系统等方面有广泛应用。
- 机器翻译:在机器翻译任务中,LSTM可以学习句子中的语义和语法结构,从而将句子从源语言翻译到目标语言。例如,将英文句子翻译为中文句子。结合注意力机制的LSTM还能够聚焦于源语言句子中与当前目标词相关的部分,从而提高翻译质量。
LSTM在NLP中的成功应用源于其对长序列依赖的捕捉能力,使其在处理语言的句法和语义关系时有更好的表现。
3.3 语音识别与生成
LSTM在语音识别和生成任务中同样具有重要应用。语音数据是典型的时间序列数据,通过LSTM可以有效地捕捉语音信号的时间依赖关系,从而实现准确的语音识别和生成。
- 语音识别:在语音识别任务中,LSTM可以将语音信号转换为文本内容。通过输入语音序列,LSTM可以逐步识别出语音中的词汇,最终生成对应的文本。语音识别技术被广泛应用于语音助手、电话客服、自动字幕生成等领域。
- 语音生成:LSTM也可以用于语音合成(如TTS,Text-to-Speech),将文本转换为语音信号。通过学习人类语音数据的特征,LSTM能够生成自然、流畅的语音,使得生成的语音更加接近真人发声。这一技术被广泛应用于语音导航、电子阅读、虚拟助手等应用中。
LSTM的时间依赖处理能力使其在语音识别和生成中表现出色。与传统的基于隐藏马尔科夫模型(HMM)的方法相比,LSTM能够更好地捕捉语音中的细节特征,提高了识别和生成的精度。
总结来说,LSTM在时间序列预测、自然语言处理和语音识别生成等领域有着广泛的应用。其对长序列依赖关系的处理能力,使得LSTM能够在处理动态、复杂的序列数据时,表现出更强的特征学习能力,满足多种序列数据处理的需求。
4.Pytorch实现LSTM
使用Pytorch实现手写的简单LSTM模型:
4.1 基本模型
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# 使用 nn.Parameter 来初始化权重和偏置
self.w_f = np.random.rand(hidden_size, input_size + hidden_size)
self.b_f = np.random.rand(hidden_size)
self.w_i = np.random.rand(hidden_size, input_size + hidden_size)
self.b_i = np.random.rand(hidden_size)
self.w_c = np.random.rand(hidden_size, input_size + hidden_size)
self.b_c = np.random.rand(hidden_size)
self.w_o = np.random.rand(hidden_size, input_size + hidden_size)
self.b_o = np.random.rand(hidden_size)
# 输出层
self.w_y = np.random.rand(output_size, hidden_size)
self.b_y = np.random.rand(output_size)
def tanh(self, x):
return np.tanh(x)
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def forward(self, x):
# 初始化隐藏状态和细胞状态
h_t = np.zeros((self.hidden_size,))
c_t = np.zeros((self.hidden_size,))
h_states = []
c_states = []
for t in range(x.size(0)):
x_t = x[t]
x_t = np.concatenate([x_t, h_t])
# 遗忘门
f_t = self.sigmoid(np.dot(self.w_f, x_t) + self.b_f)
# 输入门
i_t = self.sigmoid(np.dot(self.w_i, x_t) + self.b_i)
# 候选细胞状态
c_hat_t = self.tanh(np.dot(self.w_c, x_t) + self.b_c)
# 更新细胞状态
c_t = f_t * c_t + i_t * c_hat_t
# 输出门
o_t = self.sigmoid(np.dot(self.w_o, x_t) + self.b_o)
# 更新隐藏状态
h_t = o_t * self.tanh(c_t)
# 保存每个时间步的隐藏状态和细胞状态
h_states.append(h_t)
c_states.append(c_t)
y_t = np.dot(self.w_y, h_t) + self.b_y
output = torch.softmax(torch.tensor(y_t), dim=0)
return np.array(h_states), np.array(c_states), output
# 将 NumPy 数组转换为 PyTorch 张量
x = torch.tensor(np.random.randn(3, 2), dtype=torch.float32)
hidden_size = 5
lstm = LSTM(input_size=2, hidden_size=hidden_size, output_size=6)
hidden_states, cell_states, output = lstm.forward(x)
print("---------hidden_states---------")
print(hidden_states)
print("---------cell_states---------")
print(cell_states)
print("---------output---------")
print(output)
运行结果:
---------hidden_states---------
[[ 0.08901469 -0.13038134 0.0948994 0.02757128 -0.13162478]
[ 0.24176974 0.27227618 0.25684118 0.32446494 0.17275397]
[ 0.68680893 0.59945989 0.59626645 0.75465866 0.53877046]]
---------cell_states---------
[[ 0.17249113 -0.25505136 0.15703942 0.04406982 -0.34457368]
[ 0.41391949 0.38625761 0.41752397 0.55032217 0.25034001]
[ 1.01965885 1.0249172 1.19134723 1.20559438 0.92671947]]
---------output---------
tensor([0.1311, 0.2404, 0.2223, 0.0748, 0.1047, 0.2267], dtype=torch.float64)
4.2 多对一(简单案例):
import torch
import torch.nn as nn
class ManyToOneLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(ManyToOneLSTM, self).__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐藏状态和细胞状态
h0 = torch.zeros(1, x.size(0), self.hidden_size)
c0 = torch.zeros(1, x.size(0), self.hidden_size)
# 前向传播LSTM
out, _ = self.lstm(x, (h0, c0))
# 只取最后一个时间步的输出
out = out[:, -1, :]
# 通过全连接层得到最终输出
output = self.fc(out)
return output
# 示例使用
input_size = 10
hidden_size = 20
output_size = 2
model = ManyToOneLSTM(input_size, hidden_size, output_size)
x = torch.randn(4, 7, input_size)
output = model(x)
print(output.shape) # 输出形状:(4, output_size)
4.3 多对多(简单案例):
import torch
import torch.nn as nn
import torch.nn.functional as F
class ManyToManyLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(ManyToManyLSTM, self).__init__()
self.hidden_size = hidden_size
self.input_size = input_size
self.output_size = output_size
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐藏状态和细胞状态
h0 = torch.zeros(1, x.size(0), self.hidden_size)
c0 = torch.zeros(1, x.size(0), self.hidden_size)
# 前向传播LSTM
out, _ = self.lstm(x, (h0, c0))
# 应用全连接层到每个时间步的输出
out = self.fc(out)
return out
# 超参数设置
input_size = 10 # 输入特征的维度
hidden_size = 20 # LSTM隐藏层的维度
output_size = 5 # 输出的维度
# 创建模型实例
model = ManyToManyLSTM(input_size, hidden_size, output_size)
# 示例输入数据 (batch_size, sequence_length, input_size)
x = torch.randn(4, 7, input_size) # 假设有4个样本,每个样本是7个时间步的序列
# 前向传播
output = model(x)
print(output.shape) # 输出形状将是 (batch_size, sequence_length, output_size)
4.4 一对多(简单案例):
import torch
import torch.nn as nn
class OneToManyLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(OneToManyLSTM, self).__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐藏状态和细胞状态
h0 = torch.zeros(1, x.size(0), self.hidden_size)
c0 = torch.zeros(1, x.size(0), self.hidden_size)
# 前向传播LSTM
out, _ = self.lstm(x, (h0, c0))
# 应用全连接层到每个时间步的输出
out = self.fc(out)
return out
# 示例使用
input_size = 10
hidden_size = 20
output_size = 2
model = OneToManyLSTM(input_size, hidden_size, output_size)
x = torch.randn(4, 1, input_size) # 假设每个样本是一个时间步
output = model(x)
print(output.shape) # 输出形状:(4, 1, output_size)
4.5 LSTM文本生成案例
以下是使用PyTorch实现LSTM模型的一个简单例子,以"我 喜欢 学习 人工智能"这句话为例,以“学习”为中心词,推理"学习"后最可能出现的词汇。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
# 示例句子
sentence = "我 喜欢 学习 人工智能"
words = sentence.split()
# 构建词汇表
vocab = list(set(words))
word_to_idx = {word: idx for idx, word in enumerate(vocab)}
idx_to_word = {idx: word for idx, word in enumerate(vocab)}
vocab_size = len(vocab)
# 生成训练数据
# 将每个词作为输入,下一个词作为目标
train_data = []
for i in range(len(words) - 1):
input_word = word_to_idx[words[i]]
target_word = word_to_idx[words[i + 1]]
train_data.append((input_word, target_word))
# 定义LSTM模型
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim):
super(LSTMModel, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
embeds = self.embeddings(x)
lstm_out, _ = self.lstm(embeds)
output = self.fc(lstm_out)
return output
# 超参数
embed_dim = 10 # 词向量维度
hidden_dim = 10 # LSTM隐藏层维度
num_epochs = 1000
learning_rate = 0.001
# 创建数据集和数据加载器
class WordDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
input_word, target_word = self.data[idx]
return torch.LongTensor([input_word]), torch.LongTensor([target_word])
dataset = WordDataset(train_data)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
# 初始化模型、损失函数和优化器
model = LSTMModel(vocab_size, embed_dim, hidden_dim)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
for epoch in range(num_epochs):
total_loss = 0
for inputs, targets in dataloader:
# 前向传播
outputs = model(inputs)
loss = criterion(outputs.squeeze(1), targets.squeeze(1))
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {total_loss / len(dataloader):.4f}')
# 预测函数
def predict(center_word):
model.eval()
with torch.no_grad():
input_word = torch.LongTensor([word_to_idx[center_word]])
output = model(input_word)
print(f"Output shape: {output.shape}") # 调试信息
probabilities = torch.softmax(output, dim=1) # 修改为dim=1
predicted_idx = torch.argmax(probabilities, dim=1).item()
predicted_word = idx_to_word[predicted_idx]
return predicted_word
# 验证结果(以“学习”为中心词进行预测)
print("\n模型预测结果:")
center_word = "学习"
predicted_word = predict(center_word)
print(f"中心词: '{center_word}', 预测下一个词: '{predicted_word}'")
运行效果:
Epoch [10/1000], Loss: 1.3876
...
Epoch [1000/1000], Loss: 0.0157
模型预测结果:
Output shape: torch.Size([1, 4])
中心词: '学习', 预测下一个词: '人工智能'