在自然语言处理(NLP)中,Word Embedding(词嵌入) 是一种将单词或短语映射到向量的技术。它的核心思想是:用一组数字(向量)来表示单词的语义信息,这样计算机就可以更容易地处理和理解语言。
1.词嵌入
词嵌入是一种将词汇表中的词或短语,映射为固定长度向量的技术。通过词嵌入,我们可以将高维且稀疏的单词索引,转为低维且连续的向量。转换后的连续向量,可以表示出单词与单词之间的语义关系。
传统的独热编码存在两个致命缺陷: - 维度灾难 - 语义鸿沟
例如,假设词汇表中有10000个单词:此时我们希望表示出man、woman、king、queen四个词语,这四个词语的索引是1~10000中的4个整数。如果用one-hot向量表示这4个词;那么就需要4个10000维度的one-hot向量。这种表示方法,不仅维度高,而且非常的稀疏。在向量中,只有1个维度是1,其他维度都是0。不仅如此,单词向量和单词向量之间,都是正交的,没有任何语义关系。我们使用词嵌入技术,可以把上述的4四个高维稀疏的onehot向量,转换为低维连续向量。
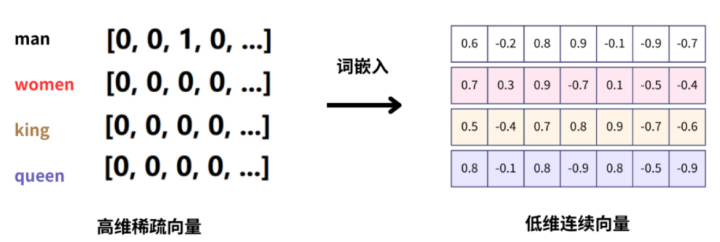
转换后的向量,每个维度都是一个浮点数。上图中就表示了,将单词映射到一个7维的空间中;
为了进一步说明词与词之间的关系:我们还可以使用PCA降维算法,将7维的词嵌入向量降维至2维。从而将单词向量在平面上绘制出来。
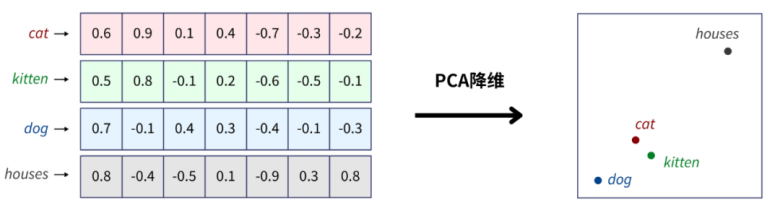
2.词嵌入与分词器的区别
在自然语言处理(NLP)中,Word Embedding(词嵌入) 和 Tokenizer(分词器) 是两个不同的概念,它们在处理文本数据时扮演不同的角色。以下是它们的主要区别:
| 特性 | Tokenizer | Word Embedding |
|---|---|---|
| 任务 | 将文本分割为离散符号 | 将离散符号映射为连续向量 |
| 输出形式 | 符号序列(如单词、子词) | 向量表示(如 ) |
| 实现方式 | 基于规则或统计方法 | 基于神经网络学习 |
| 在NLP中的位置 | 文本处理的第一步 | 文本处理的第二步 |
| 作用 | 提供模型输入的基本单元 | 捕捉词义和语义关系 |
通俗比喻 - Tokenizer:就像把一本书拆分成章节、段落、句子和单词。 - Word Embedding:就像把每个单词转化为一个“坐标”,让模型知道“苹果”和“香蕉”在语义上更接近,而“苹果”和“汽车”则更远。
3.嵌入矩阵(Embedding Matrix)
嵌入矩阵是一个二维矩阵,它的每一行对应一个单词的嵌入向量。假设我们有一个词汇表(比如包含 4 个单词),每个单词被映射到一个固定长度的向量(比如 3 维)。那么嵌入矩阵的形状就是 [词汇表大小, 向量维度],比如 [4, 3]。
举个例子,假设我们的词汇表是: 词汇表 = ["猫", "狗", "苹果", "香蕉"] 每个单词被分配一个唯一的索引:
猫 → 0
狗 → 1
苹果 → 2
香蕉 → 3
我们希望每个单词被映射到一个 3 维的向量。嵌入矩阵可以初始化为随机值(或者通过训练得到):
嵌入矩阵 = [
[0.1, 0.2, 0.3], # 猫的向量
[0.4, 0.5, 0.6], # 狗的向量
[0.7, 0.8, 0.9], # 苹果的向量
[0.2, 0.3, 0.4] # 香蕉的向量
]
如何用嵌入矩阵查找单词的向量?
假设我们有一个句子:“猫喜欢吃苹果”。我们需要将每个单词转换为向量。 将单词转换为索引: 猫 → 0 喜欢 → (这里假设“喜欢”不在词汇表中,所以忽略) 吃 → (同样不在词汇表中,忽略) 苹果 → 2
通过索引查找嵌入矩阵: - 猫的索引是 0,对应的向量是 [0.1, 0.2, 0.3] - 苹果的索引是 2,对应的向量是 [0.7, 0.8, 0.9]
结果: 句子“猫喜欢吃苹果”被表示为向量序列:[[0.1, 0.2, 0.3], [0.7, 0.8, 0.9]]
需要注意的是:嵌入矩阵的值通常不是随机的,而是通过训练学习得到的。训练的目标是让语义相似的单词在向量空间中更接近。
4.Pytorch实现WordEmbedding
下面我们用 PyTorch 实现一个简单的 Embedding 层,并展示如何将单词索引映射到嵌入向量。
import torch
import torch.nn as nn
# 1. 定义词汇表和单词索引
vocab = ["猫", "狗", "苹果", "香蕉"]
word_to_idx = {word: idx for idx, word in enumerate(vocab)} # 单词到索引的映射
print("词汇表:", vocab)
print("单词到索引的映射:", word_to_idx)
# 2. 初始化 Embedding 层
# - num_embeddings: 词汇表的大小 (4)
# - embedding_dim: 嵌入向量的维度 (3)
embedding_layer = nn.Embedding(num_embeddings=len(vocab), embedding_dim=3)
# 3. 查看嵌入矩阵的初始值
print("\n嵌入矩阵的初始值 (随机初始化):")
print(embedding_layer.weight)
# 4. 输入单词的索引
# 假设我们输入 "猫" 和 "苹果" 的索引
input_indices = torch.tensor([0, 2]) # 猫的索引是 0,苹果的索引是 2
# 5. 使用 Embedding 层将索引映射到向量
embedded_vectors = embedding_layer(input_indices)
print("\n输入的单词索引:", input_indices)
print("对应的嵌入向量:")
print(embedded_vectors)
# 6. 训练过程中更新嵌入矩阵(简单演示)
# 假设我们希望嵌入向量更接近某个目标值
target_vectors = torch.tensor([[0.5, 0.5, 0.5], [0.8, 0.8, 0.8]], dtype=torch.float32)
criterion = nn.MSELoss() # 使用均方误差损失
optimizer = torch.optim.SGD(embedding_layer.parameters(), lr=0.1) # 使用随机梯度下降优化器
# 训练循环
for epoch in range(150):
optimizer.zero_grad() # 清空梯度
embedded_vectors = embedding_layer(input_indices) # 获取当前嵌入向量
loss = criterion(embedded_vectors, target_vectors) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新嵌入矩阵
if epoch % 2 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
# 7. 查看更新后的嵌入矩阵
print("\n更新后的嵌入矩阵:")
print(embedding_layer.weight)
# 8. 查看更新后的嵌入向量
updated_vectors = embedding_layer(input_indices)
print("\n更新后的嵌入向量:")
print(updated_vectors)
运行结果:
词汇表: ['猫', '狗', '苹果', '香蕉']
单词到索引的映射: {'猫': 0, '狗': 1, '苹果': 2, '香蕉': 3}
嵌入矩阵的初始值 (随机初始化):
Parameter containing:
tensor([[-0.2511, 0.1632, -0.2546],
[-0.2750, 1.1159, 1.9124],
[-1.4393, 1.6661, 1.1515],
[-0.9940, -0.0154, -0.5352]], requires_grad=True)
输入的单词索引: tensor([0, 2])
对应的嵌入向量:
tensor([[-0.2511, 0.1632, -0.2546],
[-1.4393, 1.6661, 1.1515]], grad_fn=<EmbeddingBackward0>)
Epoch 0, Loss: 1.1892
...
Epoch 148, Loss: 0.0001
更新后的嵌入矩阵:
Parameter containing:
tensor([[ 0.4954, 0.4979, 0.4953],
[-0.2750, 1.1159, 1.9124],
[ 0.7861, 0.8054, 0.8022],
[-0.9940, -0.0154, -0.5352]], requires_grad=True)
更新后的嵌入向量:
tensor([[0.4954, 0.4979, 0.4953],
[0.7861, 0.8054, 0.8022]], grad_fn=<EmbeddingBackward0>)
Process finished with exit code 0
我们发现,经过150轮训练完成后,嵌入矩阵的值会更新,嵌入向量会更接近目标值。