faster-whisper是基于OpenAIWhisper的优化版本,利用CTranslate2提高速度和内存效率。它在保持准确性的同时,提升了处理速度,特别适合大规模语音数据处理。
1.faster-whisper介绍
faster-whisper是基于OpenAI的Whisper模型的高效实现,它利用CTranslate2,一个专为Transformer模型设计的快速推理引擎。这种实现不仅提高了语音识别的速度,还优化了内存使用效率。faster-whisper的核心优势在于其能够在保持原有模型准确度的同时,大幅提升处理速度,这使得它在处理大规模语音数据时更加高效。
项目地址:https://github.com/SYSTRAN/faster-whisper
1.1 whisper
OpenAI 的开源模型 whisper,可以执行 99 种语言的语音识别和文字转写。但是 whisper 模型占用计算资源多,命令行使用门槛高。whisper 模型本身还存在一些问题,例如 模型幻听问题(大部分的类似于不断重复同一句话、无语音部分复读莫名内容等都是由于这个原因造成的)。要更好使用 whsiper 模型就需要能够准确调试模型参数。但 whisper 模型参数众多,且命令行使用对使用者有一定要求,而且只有 torch 版可以做到调整参数。使用 VAD 类工具也需要一定的动手能力。
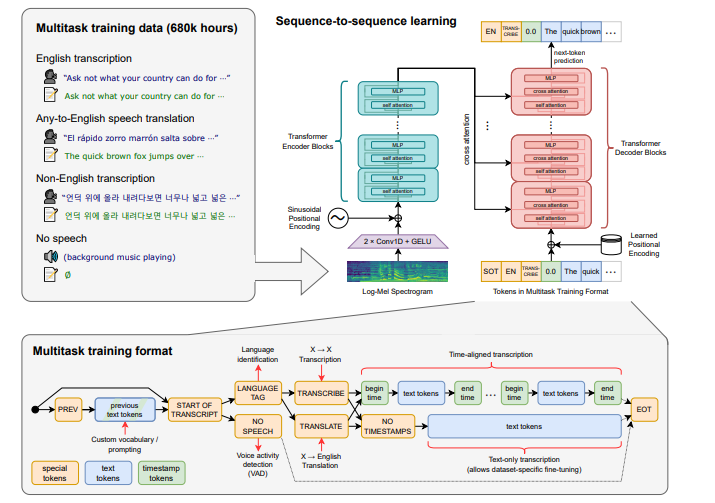
1.2 faster-whisper
faster-whisper是具有完全的 whsiper 模型参数,且自带 VAD加持的 whisper 版本,该版本使用了 CTranslate2 来重新实现 whsiper 模型,CT2 对 transformer 类网络进行了优化,使模型推理效率更高。 相比于 openai/whisper,该实现在相同准确性下速度提高了 4 倍以上,同时使用的内存更少。
所谓 VAD 即 Voice Activity Detection —— 声音活动检测,在语音信号处理中,例如语音增强,语音识别等领域有着非常重要的作用。它的作用是从一段语音(纯净或带噪)信号中标识出语音片段与非语音片段。在语音转写任务中,可以提前将语音和非语音部分分离出来,从而提升 whisper 网络识别速度,并减少模型幻听。
VAD地址:https://github.com/snakers4/silero-vad
1.3 性能对比
在性能方面,faster-whisper展现了显著的优势。例如,在使用Large-v2模型和GPU进行13分钟音频的转录测试中,faster-whisper仅需54秒,而原始Whisper模型需要4分30秒。这一显著的性能提升,意味着在实际应用中,faster-whisper能够更快地处理大量数据,特别是在需要实时或近实时语音识别的场景中。
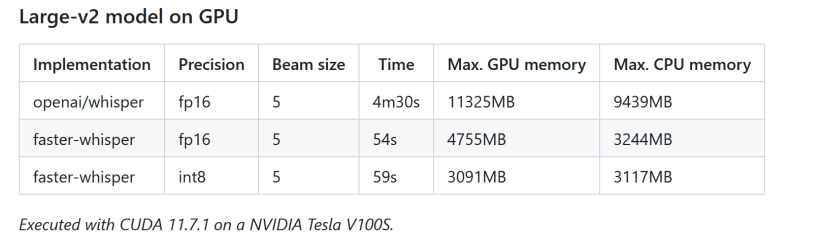
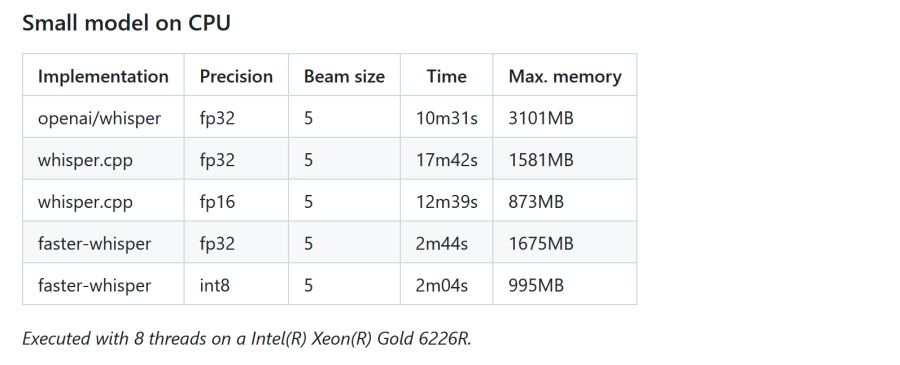
1.4 技术优势
faster-whisper的技术优势不仅体现在速度上。它还支持8位量化,这一技术可以在不牺牲太多准确度的情况下,进一步减少模型在CPU和GPU上的内存占用。这使得faster-whisper在资源受限的环境中也能高效运行,如在移动设备或嵌入式系统上。
faster-whisper适用于多种场景,特别是那些需要快速、准确的语音识别的应用。例如,在客户服务中,它可以用于实时语音转文字,提高响应速度和服务质量。在医疗领域,faster-whisper可以辅助医生快速转录病历,提高工作效率。此外,它还适用于实时会议记录、多语言翻译、教育辅助等多个领域。
2. faster-whisper安装及使用
conda环境下安装
pip install faster-whisper
模型下载:
large-v3模型:https://huggingface.co/Systran/faster-whisper-large-v3/tree/main
large-v2模型:https://huggingface.co/guillaumekln/faster-whisper-large-v2/tree/main
large-v1模型:https://huggingface.co/guillaumekln/faster-whisper-large-v1/tree/main
medium模型:https://huggingface.co/guillaumekln/faster-whisper-medium/tree/main
small模型:https://huggingface.co/guillaumekln/faster-whisper-small/tree/main
base模型:https://huggingface.co/guillaumekln/faster-whisper-base/tree/main
tiny模型:https://huggingface.co/guillaumekln/faster-whisper-tiny/tree/main
国内模型地址:
https://aifasthub.com/models/guillaumekln
2.1 使用fater-whisper进行中文语音识别
# local_files_only=True 表示加载本地模型
# model_size_or_path=path 指定加载模型路径
# device="cuda" 指定使用cuda
# compute_type="int8_float16" 量化为8位
# language="zh" 指定音频语言
# vad_filter=True 开启vad
# vad_parameters=dict(min_silence_duration_ms=1000) 设置vad参数
from faster_whisper import WhisperModel
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
#model_size = "large-v3"
#path = r"D:\Project\Python_Project\FasterWhisper\large-v3"
model_path="./faster-whisper-large-v3"
# Run on GPU with FP16
model = WhisperModel(model_size_or_path=model_path, device="cuda", local_files_only=True)
# or run on GPU with INT8
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16")
# or run on CPU with INT8
# model = WhisperModel(model_size, device="cpu", compute_type="int8")
segments, info = model.transcribe("./assets/zh_example2.wav", beam_size=5, language="zh", vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=1000))
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
运行效果:
Detected language 'zh' with probability 1.000000
[0.00s -> 3.76s] 相对来说,我认为自己是个比较有毅力的人。
[4.56s -> 10.20s] 老师交给我的任务,我一定会去完成,也能友好的与人相处。
[11.16s -> 14.16s] 自己做错的事,会用于承认。
[14.72s -> 18.28s] 相反,我也是个内向,不敢与人交流的人。
[18.72s -> 20.44s] 简单来说,就是个社苦。
[21.28s -> 22.96s] 我说话也是个接吧。
[23.56s -> 27.80s] 这些恰恰是对我以后,出入社会,找工作室是大大的不利。
[28.64s -> 32.96s] 现在,我已是就读于重庆工商职业学院的一名专科生。
[33.60s -> 35.84s] 但,我不想止步于此。
[36.44s -> 40.56s] 我想转生本,这也是为我以后好找工作而准备。
[42.04s -> 45.01s] 最后没成功,怎么办?
[45.73s -> 47.73s] 那就把专业学好。
[48.37s -> 51.89s] 有了过硬的技术,还有哪家公司不敢要你们?
[52.94s -> 57.54s] 在我看来生本是其次的,找我一个好的本领才是王道。
[57.54s -> 61.95s] 这句话也是对我对那些基础不是很好的人数。
参数说明:
- local_files_only=True 表示加载本地模型
- model_size_or_path=path 指定加载模型路径
- device="cuda" 指定使用cuda
- compute_type="int8_float16" 量化为8位
- language="zh" 指定音频语言
- vad_filter=True 开启vad
- vad_parameters=dict(min_silence_duration_ms=1000) 设置vad参数