词向量(Word Embedding)是一种将单词表示为实数向量的技术,它在自然语言处理(NLP)和机器学习中得到广泛应用。词向量的目标是捕捉单词之间的语义关系,使得语义相似的单词在向量空间中距离较近。
1.词向量
词向量(Word embedding),又叫Word嵌入式自然语言处理(NLP)中的一组语言建模和特征学习技术的统称。 简单说,词向量就是将一个词所表达的稀疏向量转化为稠密向量,并且对于相似的词,其对应的词向量也很相近。
为什么需要词向量?
由于计算机无法识别文本,故需要将其数值化(也即词向量只是在做特征工程,将其数值化,转化成计算机识别的语言)。
2.常见的词向量生成方式
2.1 独热编码(One-Hot Encoding)
最早的词向量生成方法是“独热编码”(One-Hot Encoding)。它的思路是:给每个词分配一个唯一的数字,比如“猫”是1,“狗”是2,“苹果”是3,“香蕉”是4。然后,把这些数字转化成向量,比如“猫”就是1,0,0,0,“狗”就是0,1,0,0。
这种方法虽然简单,但有个大问题:每个词的向量都是独立的,没有体现词之间的关系。比如,“猫”和“狗”在向量上毫无关联,而我们知道它们其实是相似的。所以,独热编码并不实用。
后来,科学家们发明了更高级的方法,比如Word2Vec和GloVe。这些方法的核心思想是:一个词的含义,取决于它周围的词。比如,“猫”经常和“狗”一起出现,而“面包”经常和“牛奶”一起出现。通过分析这些上下文关系,机器可以自动学习出每个词的向量。
举个例子,假设我们有一句话:“猫喜欢吃鱼,狗喜欢吃骨头。”机器会发现“猫”和“狗”都和“喜欢”“吃”“食物”这些词有关,于是它们的向量会很接近。而“鱼”和“骨头”虽然不同,但它们都是“食物”,所以它们的向量也会有一定的相似性。通过这种方式,词向量不仅能让机器“看见”词,还能理解词之间的关系。
2.2.Word2Vec
Word2Vec由Google在2013年提出,是一种基于神经网络的词向量生成方法。它包括两种模型:Skip-gram和CBOW(Continuous Bag of Words)。Skip-gram模型预测给定词汇的上下文,而CBOW模型则是根据上下文预测当前词汇。Word2Vec能够有效地捕捉到词语之间的语义和语法关系。适用于各种自然语言处理任务,如文本分类、情感分析、机器翻译等。
2.3 GloVe(Global Vectors for Word Representation)
由斯坦福大学在2014年提出,通过对整个语料库的共现统计信息进行矩阵分解,旨在直接捕捉词汇间的全局统计信息。这种方法在一定程度上弥补了Word2Vec只能反映局部上下文信息的不足。适用于需要捕捉全局语义信息的场景,如语义相似性计算、文本分类等。
2.4 BERT(Bidirectional Encoder Representations from Transformers)
由Google在2018年提出,是一个基于Transformer架构的预训练深度学习模型。BERT能够生成上下文相关的词嵌入,即同一个词在不同的句子中会有不同的向量表示。这种上下文敏感型词嵌入技术能够更好地处理一词多义等复杂语言现象。适用于各种复杂的自然语言处理任务,如问答系统、文本生成、命名实体识别等。
3.spaCy实现词向量的案例
下面我们使用 spaCy 的预训练词向量模型来计算词的相似性,并展示如何可视化词向量。
import spacy
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 加载预训练的 spaCy 模型
nlp = spacy.load("en_core_web_md")
# 示例词
words = ["cat", "dog", "apple", "banana", "king", "queen", "man", "woman"]
# 获取词向量
word_vectors = []
for word in words:
token = nlp(word)
if token.has_vector: # 检查词是否有向量
word_vectors.append(token.vector)
else:
print(f"Word '{word}' has no vector.")
# 将词向量转换为 NumPy 数组
word_vectors = np.array(word_vectors)
# 计算词的相似性
word1 = nlp("cat")
word2 = nlp("dog")
similarity = word1.similarity(word2)
print(f"Similarity between 'cat' and 'dog': {similarity:.2f}%")
# 使用 PCA 将词向量降维到 2D
pca = PCA(n_components=2)
word_vectors_2d = pca.fit_transform(word_vectors)
# 绘制词向量的散点图
plt.figure(figsize=(10, 6))
for i, word in enumerate(words):
plt.scatter(word_vectors_2d[i, 0], word_vectors_2d[i, 1])
plt.annotate(word, (word_vectors_2d[i, 0], word_vectors_2d[i, 1]))
plt.title("Word Vectors Visualization")
plt.xlabel("PCA Component 1")
plt.ylabel("PCA Component 2")
plt.show()
运行效果:
Similarity between 'cat' and 'dog': 1.00%
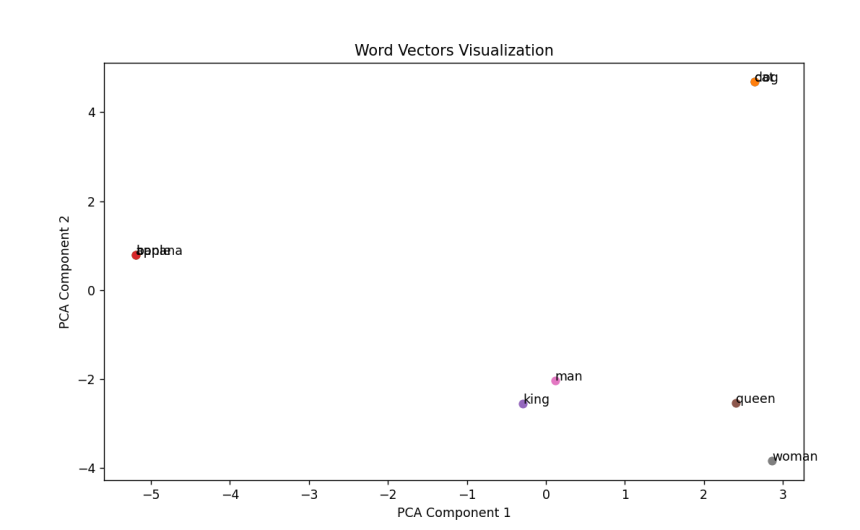
输出结果分析:
词的相似性: Similarity between 'cat' and 'dog': 1.00%
词向量的可视化: - 散点图中,语义相似的词(如“cat”和“dog”)会靠得更近,同理(如“apple”和“banana”)也会靠得更近,而语义不同的词(如“cat”和“apple”)会离得较远。 - 你还可以看到一些有趣的逻辑关系,比如“king”和“queen”之间的关系。
4.NLTK实现词向量
from nltk.corpus import wordnet as wn
# 获取单词的词向量
word1 = wn.synset('king.n.01')
word2 = wn.synset('man.n.01')
word3 = wn.synset('apple.n.01')
# 计算相似度
similarity1 = word1.wup_similarity(word2)
similarity2 = word1.wup_similarity(word3)
print("king 和 man 的相似度:", similarity1)
print("king 和 apple 的相似度:", similarity2)
运行结果:
king 和 man 的相似度: 0.631578947368421
king 和 apple 的相似度: 0.38095238095238093
wn 是 NLTK 中的 WordNet 接口。WordNet 是一个语义词典,它将单词组织成同义词集(synsets),每个同义词集表示一个概念。
标识符 'dog.n.01' 的结构如下: - dog:单词本身。 - n:词性(noun,名词)。 - 01:同义词集的索引(从 1 开始计数)。
WordNet 中的每个单词可能有多个同义词集,每个同义词集对应一个特定的含义。例如: - 'dog.n.01':表示 "dog" 的第一个名词同义词集,通常是最常见的含义(如 "家犬")。 - 'dog.n.02':表示 "dog" 的第二个名词同义词集,可能表示其他含义(如 "工作表现不佳的人")。