在自然语言处理(NLP)领域,句法依存分析是理解句子结构的重要步骤。它帮助我们了解句子中单词之间的关系,这对于后续的信息提取、情感分析等任务都至关重要。
1.依存分析
句法是指句子的各个组成部分的相互关系,句法分析分为句法结构分析(syntactic structure parsing)和依存关系分析(dependency parsing)。句法结构分析用于获取整个句子的句法结构,依存分析用于获取词汇之间的依存关系,目前的句法分析已经从句法结构分析转向依存句法分析。
依存语法通过分析语言单位内成分之间的依存关系揭示其句法结构,主张句子中核心动词是支配其它成分的中心成分,而它本身却不受其它任何成分的支配,所有受支配成分都以某种依存关系从属于支配者。
在20世纪70年代,Robinson提出依存语法中关于依存关系的四条公理: - 一个句子中只有一个成分是独立的; - 其它成分直接依存于某一成分; - 任何一个成分都不能依存与两个或两个以上的成分; - 如果A成分直接依存于B成分,而C成分在句中位于A和B之间,那么C或者直接依存于B,或者直接依存于A和B之间的某一成分;
依存关系是一个中心词与其从属之间的二元非对称关系,一个句子的中心词通常是动词(Verb),所有其他词要么依赖于中心词,要么通过依赖路径与它关联。

标签表示从属的语法功能,名词性的标签是:
- root:中心词,通常是动词
- nsubj:名词性主语(nominal subject)
- dobj:直接宾语(direct object)
- prep:介词
- pobj:介词宾语
- cc:连词
其他常用的标签:
- compound:复合词
- advmod:状语
- det:限定词
- amod:形容词修饰语
2.Spacy实现依存分析
SpaCy能够快速准确地解析句子的依存关系,并且具有丰富的API用于导航依存关系树,SpaCy使用head和child来描述依存关系中的连接,识别每个Token的依存关系:
- token.text:token的文本
- token.head:当前Token的Parent Token,从语法关系上来看,每一个Token都只有一个Head。
- token.dep_:依存关系
- token.children:语法上的直接子节点
- token.ancestors:语法上的父节点
- _pos:词性
- _tag:词性
对英文进行依存分析:
import spacy
nlp = spacy.load('en_core_web_trf')
#《华尔街日报》刚刚发表了一篇关于加密货币的有趣文章。
doc = nlp("Wall Street Journal just published an interesting piece on crypto currencies.")
for token in doc:
print('{0}({1}) <-- {2} -- {3}({4})'.format(token.text, token.tag_, token.dep_, token.head.text, token.head.tag_))
打印每个Token的依存关系和head节点,箭头表示从属关系,得到的结果是:
Wall(NNP) <-- compound -- Street(NNP)
Street(NNP) <-- compound -- Joumal(NNP)
Joumal(NNP) <-- nsubj -- published(VBD)
just(RB) <-- advmod -- published(VBD)
published(VBD) <-- ROOT -- published(VBD)
an(DT) <-- det -- piece(NN)
interesting(JJ) <-- amod -- piece(NN)
piece(NN) <-- dobj -- published(VBD)
on(IN) <-- prep -- piece(NN)
crypto(NN) <-- compound -- currencies(NNS)
currencies(NNS) <-- pobj -- on(IN)
.(.) <-- punct -- published(VBD)
也可以使用display来显示依存关系,在浏览器中输入 http://localhost:5000 显示依存结构:
import spacy
from spacy import displacy
nlp = spacy.load('en_core_web_trf')
#《华尔街日报》刚刚发表了一篇关于加密货币的有趣文章。
doc = nlp("Wall Street Journal just published an interesting piece on crypto currencies.")
for token in doc:
print('{0}({1}) <-- {2} -- {3}({4})'.format(token.text, token.tag_, token.dep_, token.head.text, token.head.tag_))
#http://localhost:5000
displacy.serve(doc, style='dep')
对中文进行依存分析:
import spacy
from spacy import displacy
nlp = spacy.load('zh_core_web_trf')
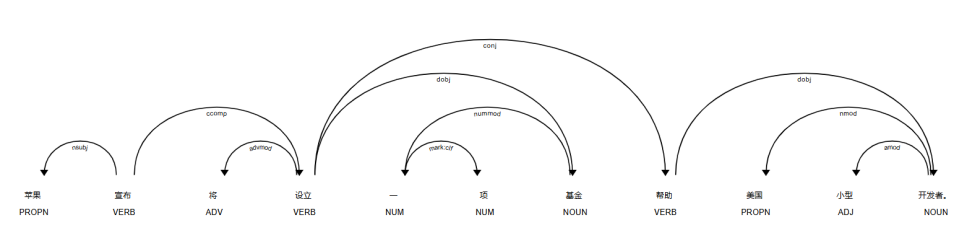
doc = nlp("苹果宣布将设立一项基金帮助美国小型开发者。")
for token in doc:
print('{0}({1}) <-- {2} -- {3}({4})'.format(token.text, token.tag_, token.dep_, token.head.text, token.head.tag_))
#http://localhost:5000
displacy.serve(doc, style='dep')
3.NLTK实现依存分析
下载Stanford Parser: https://nlp.stanford.edu/software/lex-parser.shtml 访问Stanford NLP官网下载最新版Stanford Parser。 解压后获取stanford-parser.jar和模型文件(如stanford-parser-x.x.x-models.jar)。
import nltk
nltk.download('punkt') # 确保下载了Punkt tokenizer
from nltk.parse.stanford import StanfordDependencyParser
path_to_jar = './jar/stanford-parser.jar'
path_to_models_jar = './jar/stanford-parser-4.2.0-models.jar'
# 初始化依存分析器
dependency_parser = StanfordDependencyParser(
path_to_jar=path_to_jar,
path_to_models_jar=path_to_models_jar
)
# 待分析的句子
sentence = "Wall Street Journal just published an interesting piece on crypto currencies."
# 执行依存分析
result = dependency_parser.raw_parse(sentence)
dep_tree = list(result)[0] # 获取第一个(唯一)解析结果
# 打印依存关系三元组(头词,关系,依赖词)
print("依存关系三元组:")
for triple in dep_tree.triples():
print(triple)
# 可视化依存结构(需安装graphviz)
dep_tree.plot() # 可能需额外配置图形库支持
运行效果:
依存关系三元组:
(('published', 'VBD'), 'nsubj', ('Journal', 'NNP'))
(('Journal', 'NNP'), 'compound', ('Street', 'NNP'))
(('Street', 'NNP'), 'compound', ('Wall', 'NNP'))
(('published', 'VBD'), 'advmod', ('just', 'RB'))
(('published', 'VBD'), 'obj', ('piece', 'NN'))
(('piece', 'NN'), 'det', ('an', 'DT'))
(('piece', 'NN'), 'amod', ('interesting', 'JJ'))
(('published', 'VBD'), 'obl', ('currencies', 'NNS'))
(('currencies', 'NNS'), 'case', ('on', 'IN'))
(('currencies', 'NNS'), 'compound', ('crypto', 'NN'))
使用HanNLP对中文进行依存分析:
首先安装依赖:
pip install pyhanlp
from pyhanlp import HanLP
para_sen = "苹果宣布将设立一项基金帮助美国小型开发者。"
sentence = HanLP.parseDependency(para_sen)
print(sentence)
# 输出依存文法的结果 txt文件,在windows系统下的 Dependency Viewer.exe 打开文件
path = "./text_return.txt"
with open(path, "w", encoding='utf-8') as f:
f.write(str(sentence))
print("path:%s" % (path))
运行结果:
1 苹果 苹果 n n _ 2 主谓关系 _ _
2 宣布 宣布 v v _ 0 核心关系 _ _
3 将 将 d d _ 4 状中结构 _ _
4 设立 设立 v v _ 2 动宾关系 _ _
5 一 一 m m _ 6 定中关系 _ _
6 项 项 q q _ 7 定中关系 _ _
7 基金 基金 n n _ 4 动宾关系 _ _
8 帮助 帮助 v v _ 4 并列关系 _ _
9 美国 美国 ns ns _ 11 定中关系 _ _
10 小型 小型 b b _ 11 定中关系 _ _
11 开发者 开发者 n n _ 8 动宾关系 _ _
12 。 。 wp w _ 2 标点符号 _ _