分词是将一段连续的文本切分成独立的词语的过程。
1.什么是分词
分词是自然语言处理(NLP)中的一个基础概念,通俗来说,它就是把一段连续的文本“切开”,分成一个个有意义的词语。就像我们吃蛋糕时,先把蛋糕切成小块,才能一块块地吃。分词的作用就是把文本“切”成一个个词语,方便计算机理解和处理。
举个例子: 如果有一句话 “我喜欢自然语言处理”,分词的过程就是把它拆分成 “我”“喜欢”“自然”“语言”“处理” 这几个词语。这样,计算机就知道这段文本是由这些词语组成的,而不是一串无意义的字符。 分词的重要性在于,计算机不像人类,它不能直接理解“我喜欢自然语言处理”这句话的含义。只有把这句话拆分成一个个词语,计算机才能进一步分析,比如“我”是主语,“喜欢”是动词,“自然语言处理”是宾语。这样,计算机才能更好地处理语言,比如翻译、问答、情感分析等。
不过,分词也有难点,比如有些词语的边界不清晰。比如 “乒乓球” 是一个词,但如果拆成 “乒乓” 和 “球”,也是可以的。这就需要分词算法来决定哪种切分方式更合理。
总结一下:分词就是把文本“切”成词语,就像切蛋糕一样,是自然语言处理的第一步!
2.spaCy简介
spaCy是一个功能强大的自然语言处理库,支持多种语言的分词、词性标注、命名实体识别等功能。 spaCy特别适用于中文处理,提供了多种模型选择,如zh_core_web_sm、zh_core_web_trf和zh_core_web_md等,这些模型在准确度和体积大小上有所不同,用户可以根据具体需求选择合适的模型。
spacy安装: 添加spacy依赖,并且安装en_core_web_sm和zh_core_web_sm模块。
pip install spacy -i https://pypi.tuna.tsinghua.edu.cn/simple
conda install -c conda-forge spacy-model-en_core_web_sm
conda install -c conda-forge spacy-model-zh_core_web_sm
你也可以自己去spacy的github官网,下载分词模型。下载地址:
https://github.com/explosion/spacy-models/releases
当然你也可以下载性能更好的en_core_web_trf和zh_core_web_trf模型。 zh_core_web_sm和zh_core_web_trf的主要区别在于它们的架构和性能。
架构: - zh_core_web_sm:基于传统的统计方法,没有采用Transformer架构。 - zh_core_web_trf:基于Transformer架构(bert-base-chinese),采用了最新的深度学习技术。
性能: - zh_core_web_sm:性能较低,但在某些简单任务上仍然有效。 - zh_core_web_trf:性能最高,尤其在复杂的自然语言处理任务上表现优秀,如命名实体识别、依存关系解析等。
资源需求: - zh_core_web_sm:需要的计算资源最少,适合资源非常有限的环境。 - zh_core_web_trf:需要较多的计算资源和时间来加载和运行,适用于需要最高准确性的复杂任务。
spaCy实现英文分词:
import spacy
nlp = spacy.load("en_core_web_trf")
doc = nlp("Hello! How are you doing today? Let's learn NLP.")
#print([(w.text, w.pos_) for w in doc])
for token in doc:
print(token.text, token.pos_, token.dep_)
运行结果:
Hello INTJ ROOT
! PUNCT punct
How SCONJ advmod
are AUX aux
you PRON nsubj
doing VERB ROOT
today NOUN npadvmod
? PUNCT punct
Let VERB ROOT
's PRON nsubj
learn VERB ccomp
NLP PROPN dobj
. PUNCT punct
spaCy实现中文分词:
import spacy
nlp = spacy.load("zh_core_web_trf")
doc = nlp("今天的天气真好!咱们一起去爬山好吗?")
print([(w.text, w.pos_) for w in doc])
运行结果:
[('今天', 'NOUN'), ('的', 'PART'), ('天气', 'NOUN'), ('真', 'ADV'), ('好', 'VERB'), ('!', 'PUNCT'), ('咱们', 'PRON'), ('一起', 'ADV'), ('去', 'VERB'), ('爬山', 'VERB'), ('好', 'VERB'), ('吗', 'PART'), ('?', 'PUNCT')]
3.NLTK简介
NLTK(Natural Language Toolkit)是一个开源的Python库,专门用于自然语言处理(NLP)任务的研究和开发。它由Steven Bird和Edward Loper在宾夕法尼亚大学开发,提供了丰富的模块、数据集和教程,适用于NLP入门学习和实验性项目开发。
NLTK安装: 首先安装nltk依赖。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ nltk
代码下载方式:
import nltk
nltk.download()
出现以上界面说明 nltk_data包全部下载完毕,默认安装在 %USER_HOME%\AppData\Roaming\nltk_data 目录下。
NLTK实现英文分词:
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
# 下载分词所需数据
nltk.download('punkt')
# 示例文本
text = "Hello! How are you doing today? Let's learn NLP."
# 句子分割
sentences = sent_tokenize(text)
print("句子分割:", sentences)
# 单词分割
words = word_tokenize(text)
print("单词分割:", words)
运行结果:
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\Administrator\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
句子分割: ['Hello!', 'How are you doing today?', "Let's learn NLP."]
单词分割: ['Hello', '!', 'How', 'are', 'you', 'doing', 'today', '?', 'Let', "'s", 'learn', 'NLP', '.']
NLTK实现中文分词:
import jieba
text = "今天的天气真好!咱们一起去爬山好吗?"
tokens = jieba.lcut(text)
print(tokens)
运行结果:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.620 seconds.
Prefix dict has been built successfully.
['今天', '的', '天气', '真', '好', '!', '咱们', '一起', '去', '爬山', '好', '吗', '?']
3.spaCy与NLKT的对比
主要差异对比:
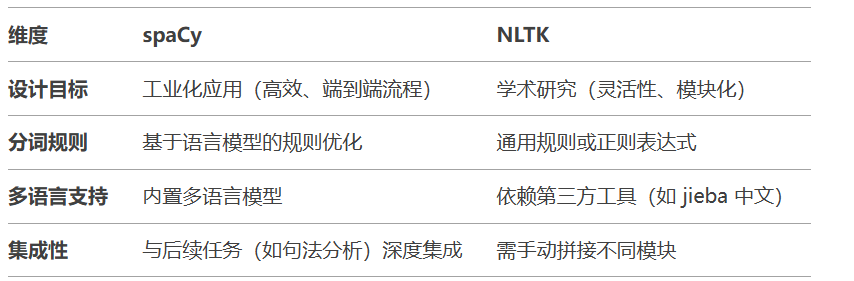
性能对比:
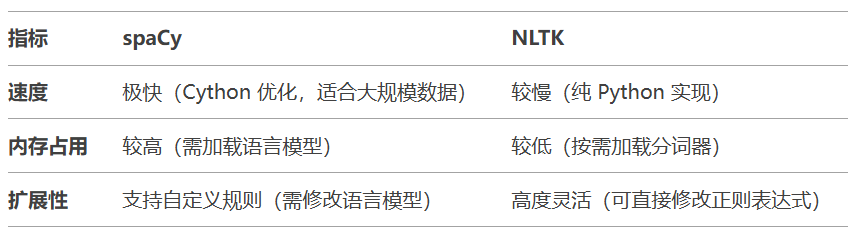
如何选择?
- 选 spaCy:需要快速处理大规模文本、多语言支持,或与下游任务(如实体识别、依存分析)无缝衔接。
- 选 NLTK:需要高度自定义分词规则、学术实验,或与其他算法(如 VADER 情感分析)配合。
如果需要处理特定领域(如医学文本或社交媒体),两者均可通过自定义规则扩展,但 spaCy 的规则集成更复杂,而 NLTK 的 RegexpTokenizer 更易快速实现。