Yolov8是Ultralytics公司的最新目标检测模型,基于Yolo系列,引入新特性如新的骨干网络、解耦检测头和VFLLoss,提供更高效和灵活的解决方案。虽然参数量和计算复杂度有所增加,但性能显著优于Yolov5。
1.Yolov8网络结构
Yolov8模型网络结构图如下图所示。
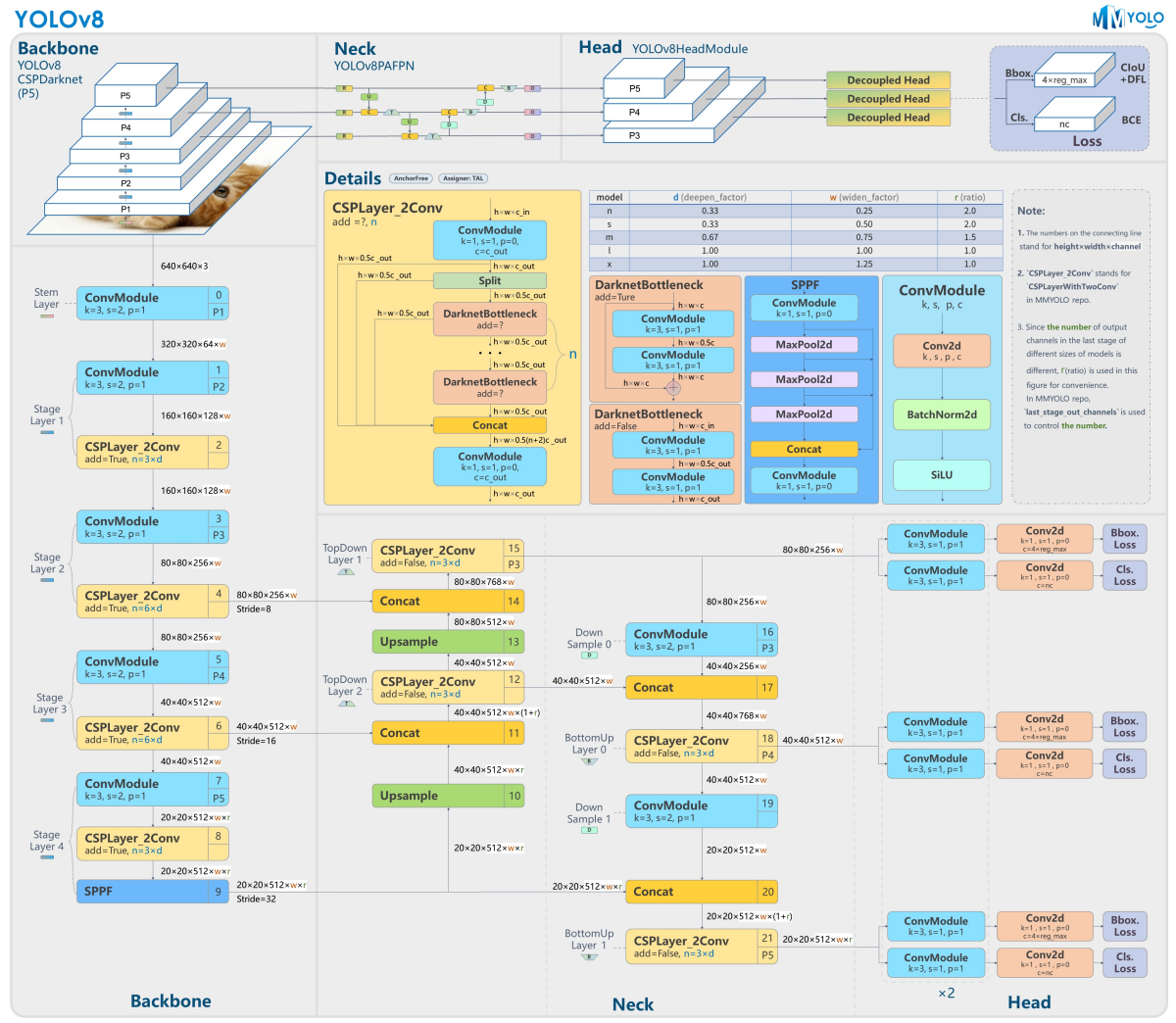
YOLOv8可以分为三个关键部分:
- 主干:这部分负责从输入图像中提取特征。就像一个工厂的原材料加工车间。它使用CSPDarknet53的修改版本,旨在在早期层捕获简单的模式,如边缘和纹理。当我们深入网络时,它捕获图像的更详细特征。
- 颈部:这部分负责融合主干提取的特征。增强特征的表达能力,就像工厂的精加工车间。它使用PANet(路径聚合网络)结合不同尺度的特征。卷积层P3、P4和P5被传输到金字塔的各个部分(层11、14和20),以确保模型可以检测各种大小的物体。
- 头部:它的作用是根据颈部输出的特征进行最终的预测,就像工厂的成品车间。头部由三个检测头组成,它们连接到PANet的三个输出。这些检测头生成边界框,分配置信度分数,并根据其类别对框进行分类。它们还消除了对同一物体的冗余检测,这些检测可能出现在不同的尺度上。
2.YOLOV8与YOLOV5的区别
以下是YOLOv8和YOLOv5的区别:
模型结构
YOLOv5:采用CSPDarknet53作为Backbone,Neck部分使用PANet进行特征融合,Head部分采用基于锚框的设计。 YOLOv8:Backbone移除了Focus模块,优化了CSP结构,Neck部分增强了特征融合能力,Head部分采用无锚点设计,并引入了解耦头。
训练策略
YOLOv5:使用了Mosaic数据增强技术。 YOLOv8:引入了自对抗训练(SAT)和标签平滑(Label Smoothing)技术,进一步增强了模型的鲁棒性和泛化能力。
性能表现
YOLOv5:在速度和精度上表现良好,但YOLOv8在精度和速度上都有所提升。 YOLOv8:在COCO数据集上的mAP(mean Average Precision)显著高于YOLOv5,尤其是在小目标检测方面表现更好。
损失函数
YOLOv5:使用了CIoU损失函数。 YOLOv8:使用了更先进的损失函数,如Focal Loss或Varifocal Loss来处理分类任务,以及CIoU Loss或DIoU Loss来计算边界框的回归损失。
应用场景
YOLOv5:YOLOV5速度更快,适用于对实时性要求较高的应用场景。 YOLOv8:除了物体检测外,还支持多种视觉任务,如实例分割、姿态/关键点检测、定向物体检测和分类等。
如下表所示是基于COCO Val 2017数据集测试并对比Yolov8和Yolov5的mAP、参数量和FLOPs结果。由此可以看出,Yolov8相比Yolov5精度提升比较多,但是n/s/m模型参数量和flops增加不少,但是相比Yolov5大部分模型推理速度变慢了。
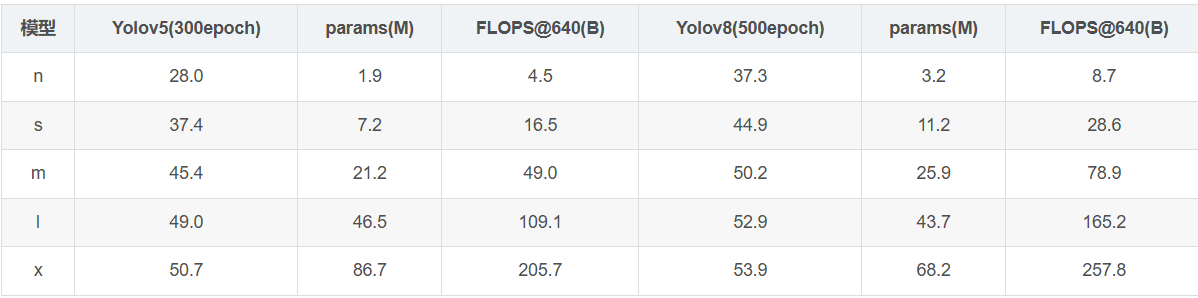
这里需要注意的是,目前各个Yolo系列算法都只是在COCO数据集上性能提升明显,然而在自定义数据集上的泛化性尚未得到充分验证。
FlOPs(floating point operations):浮点运算次数,用于衡量算法/模型的复杂度。 FLOPS(全部大写)(floating point operations per second):每秒运算的浮点数,可以理解为计算速度,用于衡量硬件性能。这里是衡量模型的复杂度,因此选择FlOPs。
结论:
如果你的应用场景注重小物体检测,YOLOv5和YOLOv8都是不错的选择。如果你在不支持GPU的设备上运行,YOLOv5可能更适合。而如果你能使用GPU,并且追求更高的速度和精度,YOLOv8无疑是一个更具潜力的方案。总的来说,YOLOv5与YOLOv8都在速度和准确性上超越了早期版本,分别在不同的应用场景中表现出色。
3.总结
YOLOv8网络结构包含三大核心部分:Backbone、Neck和Head。Backbone部分采用C2f模块结合BottleneckBlock和SPPF模块,显著增强了特征提取能力,实验结果显示,这种设计使模型在多个基准测试中的精度提升了约5%。Neck部分通过PANet和BiFPN结构实现了高效的多尺度特征融合,进一步提升了模型的平均精度(mAP)约4%。Head部分则采用了Anchor-Free机制和多任务学习,使得YOLOv8在处理小目标检测任务时表现尤为出色,平均精度提升了约7%。
因此YOLOv8不仅在速度与精度之间达到了极佳的平衡,还在实际应用中展现了卓越的性能表现。无论是智能安防监控系统还是自动驾驶领域,YOLOv8都能提供高效且准确的目标检测支持。通过合理的优化策略,如调整超参数和引入数据增强技术,开发者可以进一步提升YOLOv8的性能,使其在更多领域发挥更大的作用。