MobileNets是由谷歌团队在2017年提出,旨在为移动和嵌入式设备提出的高效模型。传统的深度卷积神经网络将多个计算机视觉任务性能提升到了一个新高度,总体的趋势是为了达到更高的准确性构建了更深更复杂的网络,但是这些网络在尺度和速度上不一定满足移动设备要求。MobileNet描述了一个高效的网络架构,允许通过两个超参数直接构建非常小、低延迟、易满足嵌入式设备要求的模型。
1.MobileNetV1
论文地址:论文原文地址
论文标题为MobileNets:移动视觉应用的高效卷积神经网络,由谷歌团队在2017年提出,引入了深度可分离卷积(depthwise separable convolution),用于构建轻量级神经网络,大大减少了运算量和参数数量。MobileNet v1以较小的计算成本和模型大小在多个视觉任务上实现了较高的性能。
这里需要介绍一下深度可分卷积操作(Depthwise Separable Conv),这种卷积操作是有两种卷积组成的,即DW卷积和PW卷积(Pointwise Conv)组成,先DW卷积,结果作为PW卷积的输入,PW卷积如下图所示:
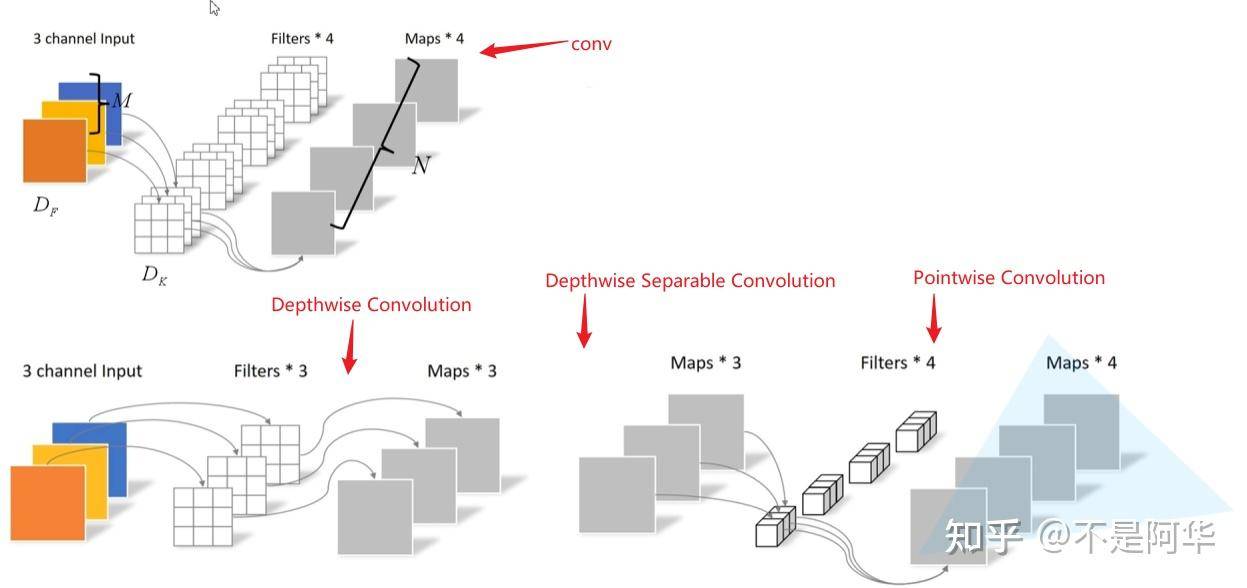
对于传统卷积神经网络:
- 卷积核channel = 输入矩阵channel
- 输出矩阵channel = 卷积核个数
对于Depthwise Convolution(深度卷积):
- 卷积核channel = 1
- 输入矩阵channel = 卷积核个数 = 输出矩阵channel (从而大大减少计算量)
对于Pointwise Convolution(1x1逐点卷积):
- 其实就是传统卷积神经网络中使用1x1大小的卷积核,Mobile Net v1使用这个大部分是为了升维,目的是为了得到和使用传统卷积神经网络一样尺寸的feature map。
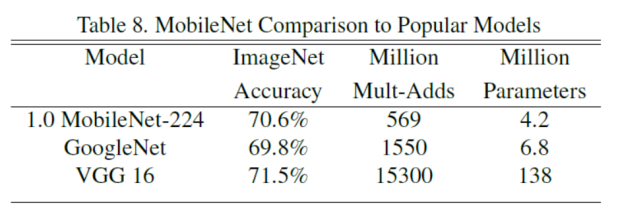
MobileNet与原始的GoogleNet和VGG16对比,MobileNet与VGG16有相似的精度,参数量和计算量减少了2个数量级。
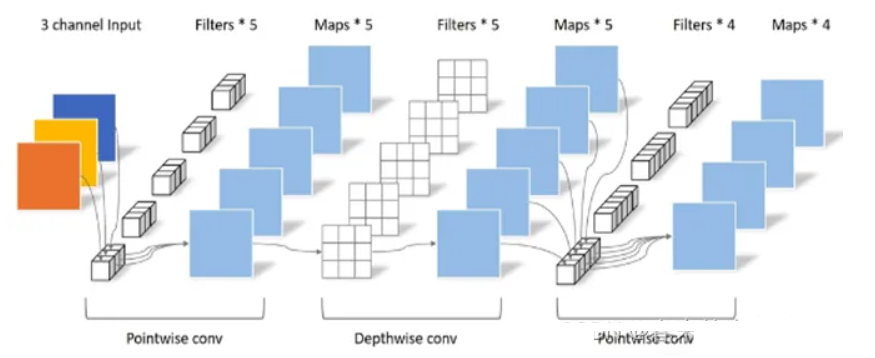
2.MobileNetV2
MobileNet V2 网络结构如下:
MobileNetV2网络设计基于MobileNet V1,它保留了其简单性且不需任何特殊的运算符,同时显着提高了其准确性,从而实现了针对移动应用程序的图像分类和检测任务等。网络中的亮点是 Inverted Residuals (倒残差结构 )和 Linear Bottlenecks(线性瓶颈)。Inverted residuals,按照之前残差结构的通常用法,都是先经过一个1x1的卷积操作将特征图通道数减少,再做3x3卷积,最后再通过1x1卷积操作升维,将特征图通道扩充回到想要的数量,这样将通道先“压缩后扩张”的方式可以减少参数量。但是MobileNetv2的做法是反着来的,即“先扩张后压缩”。
MobileNet V2同样借鉴了ResNet,采用了残差结构,将输出与输入相加,但是ResNet中的残差结构是先降维卷积再升维,而MobileNet V2则是先升维卷积再降维。ResNet的残差结构更像一个沙漏,而MobileNet V2中的残差结构则更像是一个纺锤,两者刚好相反。因此论文作者将MobileNet V2的结构称为“Inverted Residual Block”。
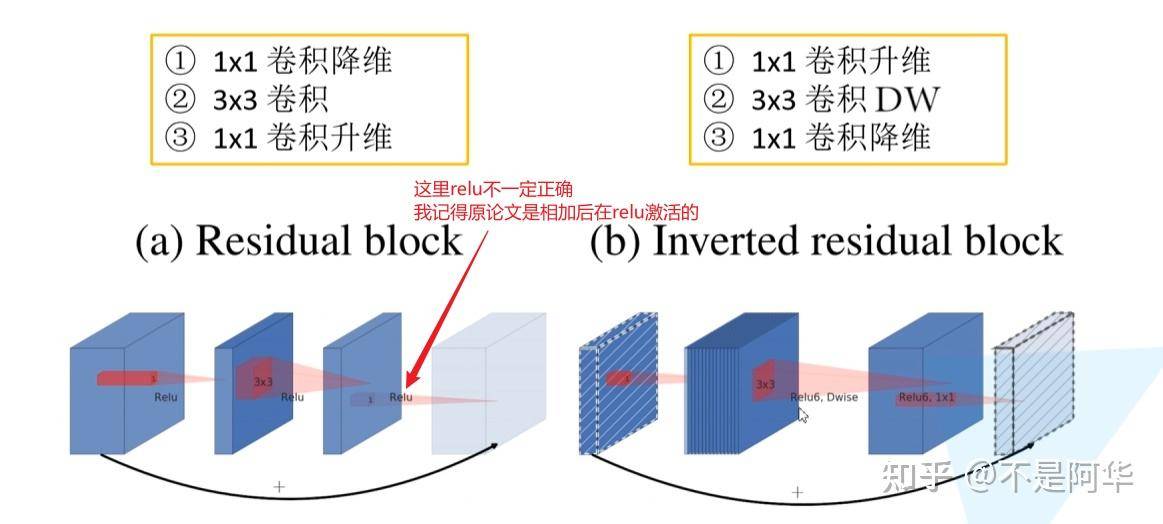
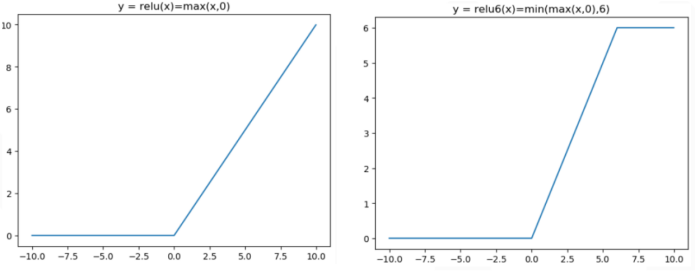
需要注意的是:inverted residual中使用的激活函数不是relu,而是relu6激活函数,即f(x)=min(max(0,x),6),即对原始relu改进了一下,让他最大值不超过6,这样函数被控制在(0,6)之间。
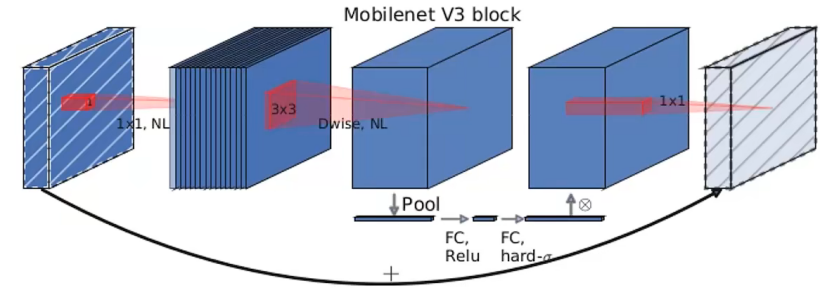
3.MobileNetV3
MobileNetV3的整体架构基本沿用了MobileNetV2的设计,采用了轻量级的深度可分离卷积和残差块等结构,依然是由多个模块组成,但是每个模块得到了优化和升级,包括瓶颈结构、SE模块和NL模块。MobileNetV3在ImageNet 分类任务中正确率上升了 3.2%,计算延时还降低了20%。
整体来说MobileNetV3有两大创新点: - 互补搜索技术组合:由资源受限的NAS执行模块级搜索,NetAdapt执行局部搜索。 - 网络结构改进:将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数。
MobileNetV3 有两个版本,MobileNetV3-Small 与 MobileNetV3-Large 分别对应对计算和存储要求低和高的版本。
MobileNetV3特有的bneck结构:
4.MobileNetV3在花卉分类数据集上的实现
model.py
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partial
from typing import Optional, List, Callable
def _make_divisible(ch, divisor=8, min_ch=None):
"""
:param ch: 输入特征矩阵的channel
:param divisor: 基数
:param min_ch: 最小通道数
"""
if min_ch is None:
min_ch = divisor
# 将ch调整到距离8最近的整数倍
# int(ch + divisor / 2) // divisor 向上取整
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# 确保向下取整时不会减少超过10%
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
# 定义 卷积-BN-激活函数 联合操作
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
# BN层
norm_layer: Optional[Callable[..., nn.Module]] = None,
# 激活函数
activation_layer: Optional[Callable[..., nn.Module]] = None):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.ReLU6
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer(inplace=True))
# SE模块
class SqueezeExcitaion(nn.Module):
def __init__(self, input_c: int, squeeze_factor: int = 4):
super(SqueezeExcitaion, self).__init__()
squeeze_c = _make_divisible(input_c // squeeze_factor, 8)
self.fc1 = nn.Conv2d(input_c, squeeze_c, 1)
self.fc2 = nn.Conv2d(squeeze_c, input_c, 1)
def forward(self, x: Tensor)-> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = F.relu(scale, inplace=True)
scale = self.fc2(scale)
scale = F.hardsigmoid(scale, inplace=True)
return scale * x
# 定义V3的Config文件
class InvertedResidualConfig:
def __init__(self,
input_c: int,
kernel: int,
expanded_c: int,
out_c: int,
use_se: bool,
activation: str,
stride: int,
# 阿尔法参数
width_multi: float):
self.input_c = self.adjust_channels(input_c, width_multi)
self.kernel = kernel
self.expanded_c = self.adjust_channels(expanded_c, width_multi)
self.out_c = self.adjust_channels(out_c, width_multi)
self.use_se = use_se
self.use_hs = activation == "HS"
self.stride = stride
@staticmethod
def adjust_channels(channels: int, width_multi: float):
return _make_divisible(channels * width_multi, 8)
# V3 倒残差结构
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
norm_layer: Optional[Callable[..., nn.Module]]):
super(InvertedResidual, self).__init__()
# 判断步幅是否正确
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
# 初始化 block 为 Identity 模块,确保即使在没有需要额外操作的情况下,
# self.block 仍是一个有效的 PyTorch 模块,可以被调用。
# 这样做可以防止在前向传播中出现 AttributeError。
self.block = nn.Identity() # 或者 self.block = nn.Sequential()
# 判断是否使用残差连接
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers = []
activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU
# expand
# 判断是否需要升维操作
if cnf.expanded_c != cnf.input_c:
layers.append(ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer))
# depthwise
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer))
# 判断是否使用SE结构
if cnf.use_se:
layers.append(SqueezeExcitaion(cnf.expanded_c))
# project
layers.append(ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer))
self.block = nn.Sequential(*layers)
self.out_channel = cnf.out_c
def forward(self, x):
result = self.block(x)
if self.use_res_connect:
result += x
return result
class MobileNetV3(nn.Module):
def __init__(self,
inverted_residual_setting: List[InvertedResidualConfig],
last_channel: int,
num_classes: int = 1000,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None):
super(MobileNetV3, self).__init__()
if not inverted_residual_setting:
raise ValueError("The inverted_residual_setting should not be empty.")
elif not (isinstance(inverted_residual_setting, List) and
all([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):
raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)
layers: List[nn.Module] = []
# building first layer
firstconv_output_c = inverted_residual_setting[0].input_c
layers.append(ConvBNActivation(3,
firstconv_output_c,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.append(block(cnf, norm_layer))
# building last several layers
lastconv_input_c = inverted_residual_setting[-1].out_c
lastconv_output_c = 6 * lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Hardswish))
self.features = nn.Sequential(*layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(p=0.2, inplace=True),
nn.Linear(last_channel, num_classes))
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def mobilenet_v3_large(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.
weights_link:
https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
"""
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, False, "RE", 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2), # C1
bneck_conf(24, 3, 72, 24, False, "RE", 1),
bneck_conf(24, 5, 72, 40, True, "RE", 2), # C2
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 3, 240, 80, False, "HS", 2), # C3
bneck_conf(80, 3, 200, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 480, 112, True, "HS", 1),
bneck_conf(112, 3, 672, 112, True, "HS", 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2), # C4
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
]
last_channel = adjust_channels(1280 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
def mobilenet_v3_small(num_classes: int = 1000,
reduced_tail: bool = False) -> MobileNetV3:
"""
Constructs a large MobileNetV3 architecture from
"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.
weights_link:
https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pth
Args:
num_classes (int): number of classes
reduced_tail (bool): If True, reduces the channel counts of all feature layers
between C4 and C5 by 2. It is used to reduce the channel redundancy in the
backbone for Detection and Segmentation.
"""
width_multi = 1.0
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, True, "RE", 2), # C1
bneck_conf(16, 3, 72, 24, False, "RE", 2), # C2
bneck_conf(24, 3, 88, 24, False, "RE", 1),
bneck_conf(24, 5, 96, 40, True, "HS", 2), # C3
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 120, 48, True, "HS", 1),
bneck_conf(48, 5, 144, 48, True, "HS", 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
train.py
import torch
import torch.nn as nn
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torch.optim as optim
from model import mobilenet_v3_large
import os
import json
import torchvision.models.mobilenet
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# print(device)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机翻转
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256), # 长宽比不变,最小边长缩放到256
transforms.CenterCrop(224), # 中心裁剪到 224x224
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 获取数据集所在的根目录
# 通过os.getcwd()获取当前的目录,并将当前目录与".."链接获取上一层目录
data_root = os.path.abspath(os.path.join(os.getcwd()))
# 获取花类数据集路径
image_path = data_root + "./data_set/flower_data/"
# 加载数据集
train_dataset = datasets.ImageFolder(root=image_path + "/train",
transform=data_transform["train"])
# 获取训练集图像数量
train_num = len(train_dataset)
# 获取分类的名称
# {'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflowers': 3, 'tulips': 4}
flower_list = train_dataset.class_to_idx
# 采用遍历方法,将分类名称的key与value反过来
cla_dict = dict((val, key) for key, val in flower_list.items())
# 将字典cla_dict编码为json格式
json_str = json.dumps(cla_dict, indent=4)
with open("class_indices.json", "w") as json_file:
json_file.write(json_str)
batch_size = 16
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = DataLoader(validate_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0)
# 定义模型
net = mobilenet_v3_large(num_classes=5) # 实例化模型
net.to(device)
model_weight_path = "./mobilenet_v3_large_pre.pth"
# 载入模型权重
pre_weights = torch.load(model_weight_path)
# 删除分类权重
pre_dict = {k: v for k, v in pre_weights.items() if "classifier" not in k}
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)
# 冻结除最后全连接层以外的所有权重
for param in net.features.parameters():
param.requires_grad = False
loss_function = nn.CrossEntropyLoss() # 定义损失函数
# pata = list(net.parameters()) # 查看模型参数
optimizer = optim.Adam(net.parameters(), lr=0.0001) # 定义优化器
# 设置存储权重路径
save_path = './mobilenetV3.pth'
best_acc = 0.0
for epoch in range(100):
# train
net.train() # 用来管理Dropout方法:训练时使用Dropout方法,验证时不使用Dropout方法
running_loss = 0.0 # 用来累加训练中的损失
for step, data in enumerate(train_loader, start=0):
# 获取数据的图像和标签
images, labels = data
# 将历史损失梯度清零
optimizer.zero_grad()
# 参数更新
outputs = net(images.to(device)) # 获得网络输出
loss = loss_function(outputs, labels.to(device)) # 计算loss
loss.backward() # 误差反向传播
optimizer.step() # 更新节点参数
# 打印统计信息
running_loss += loss.item()
# 打印训练进度
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
# validate
net.eval() # 关闭Dropout方法
acc = 0.0
# 验证过程中不计算损失梯度
with torch.no_grad():
for data_test in validate_loader:
test_images, test_labels = data_test
outputs = net(test_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
# acc用来累计验证集中预测正确的数量
# 对比预测值与真实标签,sum()求出预测正确的累加值,item()获取累加值
acc += (predict_y == test_labels.to(device)).sum().item()
accurate_test = acc / val_num
# 如果当前准确率大于历史最优准确率
if accurate_test > best_acc:
# 更新历史最优准确率
best_acc = accurate_test
# 保存当前权重
torch.save(net.state_dict(), save_path)
# 打印相应信息
print("[epoch %d] train_loss: %.3f test_accuracy: %.3f" %
(epoch + 1, running_loss / step, acc / val_num))
print("Finished Training")
训练效果如下:
train loss: 100%[**************************************************->]1.504
[epoch 1] train_loss: 1.253 test_accuracy: 0.425
...
train loss: 100%[**************************************************->]0.263
[epoch 100] train_loss: 0.572 test_accuracy: 0.869
Finished Training
predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import mobilenet_v3_large
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "./images/sunflower01.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = mobilenet_v3_large(num_classes=5).to(device)
# load model weights
weights_path = "./mobilenetV3.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
# prediction
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
预测效果:
class: daisy prob: 0.0257
class: dandelion prob: 0.0063
class: roses prob: 0.0036
class: sunflowers prob: 0.955
class: tulips prob: 0.00897
