基于ResNet的汽车分类
基于ResNet的汽车分类
1.数据集简介
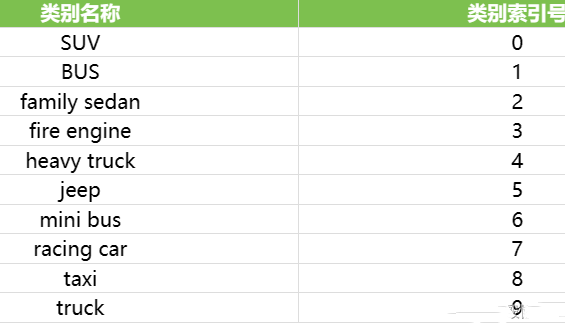
本文以车辆分类算法为例,数据集的百度网盘下载链接为: https://pan.baidu.com/s/1pkYm9AA3s3WDM7GecShlbQ 提取码:6666

2.定义ResNet
ResNet.py
# _*_ coding: utf-8 _*_
# 导入PyTorch 相关库
from torch import nn
import torch.nn.functional as F
# 定义ResNet的基本块
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
# 定义ResNet主体结构
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.max_pool2d(out, 3, 2, 1)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
3.模型训练与评估
main.py
import numpy as np
import random
import torch
import os
import torch.nn as nn
import torchvision.models
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from ResNet import ResNet, BasicBlock
from sklearn.metrics import confusion_matrix
import seaborn as sns
def setup_seed(seed):
np.random.seed(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
setup_seed(0)
if torch.cuda.is_available():
device = torch.device('cuda')
print('CUDA is available. Using GPU.')
else:
device = torch.device('cpu')
print('CUDA is not available. Using CPU')
# 定义数据集的加载与处理
# 定义训练数据的处理步骤
train_tranforms = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(0.5),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 定义验证数据的处理步骤
valid_transforms = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 读取数据
train_dataset = datasets.ImageFolder('./dataset/train', transform=train_tranforms)
valid_dataset = datasets.ImageFolder('./dataset/val', transform=valid_transforms)
# 做成dataLoader,方便后续模型的训练
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True)
valid_dataloader = DataLoader(valid_dataset, batch_size=16, shuffle=True)
# 从训练集中抽几张图片进行显示
examples = enumerate(train_dataloader)
batch_idx, (imgs, lbs) = next(examples)
fig = plt.figure()
for i in range(4):
plt.subplot(2, 2, i + 1)
plt.imshow(imgs[i][0], cmap='gray')
plt.title(f'Ground Truth: {lbs[i]}')
plt.xticks([])
plt.yticks([])
plt.show()
# 实例化模型
model = ResNet(BasicBlock, [2, 2, 2, 2], num_classes=10).to(device)
# # 演示:使用预训练模型训练自己的任务
# model = torchvision.models.resnet18(weights=None).to(device)
#
# model.load_state_dict(torch.load('../model/resnet18-5c106cde.pth', weights_only=True))
#
# for param in model.parameters():
# param.requires_grad = False
#
# fc_inputs = model.fc.in_features
# model.fc = nn.Sequential(
# nn.Linear(fc_inputs, 256),
# nn.ReLU(),
# nn.Dropout(0.4),
# nn.Linear(256, 10),
# nn.LogSoftmax(dim=1),
# ).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 优化器
# 模型保存路径
save_path = './model/last.pth'
# 训练模型
num_epoch = 50
for epoch in range(num_epoch):
model.train()
total_loss = 0
for i, (images, labels) in enumerate(train_dataloader):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch [{epoch + 1}/{num_epoch}] Batch [{i + 1}/{len(train_dataloader)}] Loss {loss.item():.4f}')
avg_loss = total_loss / len(train_dataloader)
if (epoch + 1) % 1 == 0:
print(f'Epoch [{epoch + 1}/{num_epoch}] Loss {avg_loss:.4f}')
torch.save(model.state_dict(), save_path)
# 模型评估
model.eval()
correct = 0
total = 0
predicted_labels = []
true_labels = []
with torch.no_grad():
for images, labels in valid_dataloader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
predicted_labels.extend(predicted.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
print(f'Accuracy of the model on test images: {100 * correct / total:.2f}%')
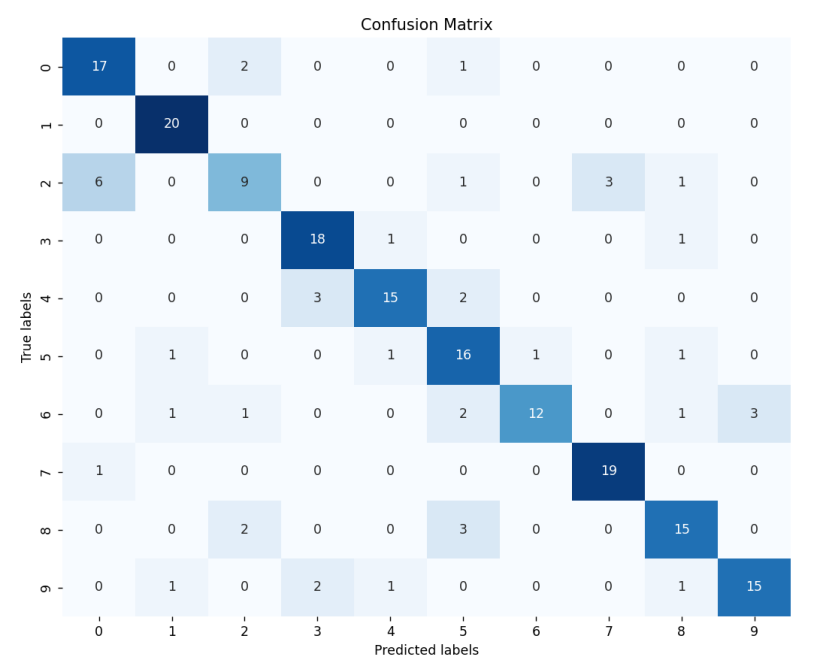
# 可视化,绘制混淆矩阵
conf_matrix = confusion_matrix(true_labels, predicted_labels)
plt.figure(figsize=(10, 8))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', cbar=False)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.title('Confusion Matrix')
plt.show()
运行效果:
CUDA is available. Using GPU.
Epoch [1/50] Batch [1/88] Loss 2.3884
...
Epoch [50/50] Loss 0.8307
Accuracy of the model on test images: 78.00%
混淆矩阵: