VGGNet是由牛津大学视觉几何组提出的深度学习模型,在ILSVRC2014比赛中取得佳绩。VGG16是其典型代表,由多个3x3卷积层和池化层组成,最后接全连接层。
1.VGGnNet概述
VGGNet是牛津大学视觉几何组(Visual Geometry Group)提出的模型,故简称VGGNet, 该模型在2014年的ILSVRC中取得了分类任务第二、定位任务第一的优异成绩。该模型证明了增加网络的深度能够在一定程度上影响网络最终的性能。
论文地址:论文链接地址
VGGNet,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。VGGNet有多个版本,常用的是VGG16表示有16层的卷积,除此之外,还有VGG11、VGG13和VGG19等模型。如下图所示:
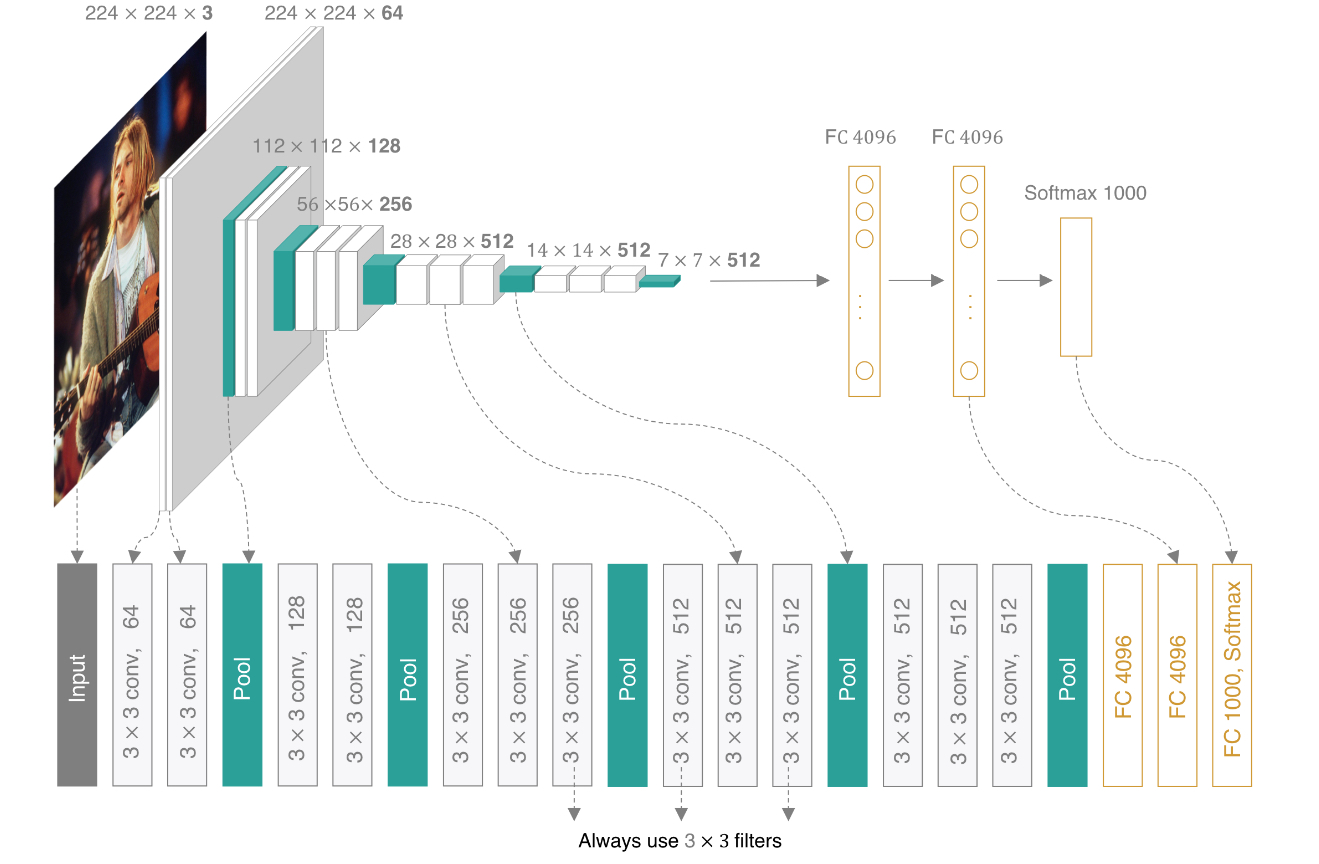
2.网络的创新
VGGnNet的核心思想是通过堆叠3x3卷积核代替大尺度卷积核,VGGNet的亮点在于它通过堆叠多个卷积层,以小的卷积核和池化层的方式来增加网络深度,从而实现高精度的图像识别。这种方法可以有效地捕获图像中的高级特征,并通过不断拟合训练数据来提高识别准确率。
感受野的概念
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域,如下图所示。
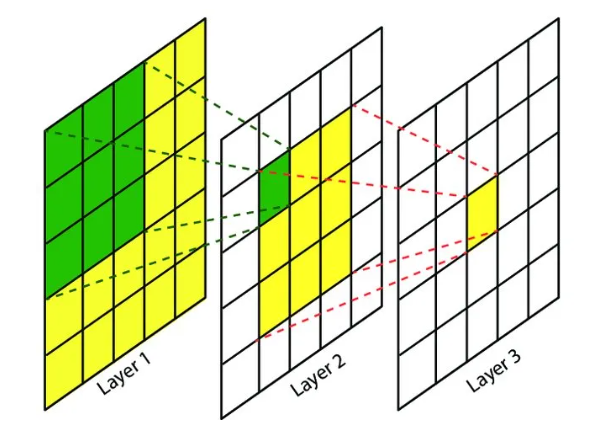
卷积神经网络中,越深层的神经元看到的输入区域越大,如上图所示,kernel size 均为3×3,stride均为1,绿色标记的是Layer2每个神经元看到的区域,黄色标记的是Layer3 看到的区域,具体地,Layer2每个神经元可看到Layer1上3×3 大小的区域,Layer3 每个神经元看到Layer2 上3×3 大小的区域,该区域可以又看到Layer1上5×5 大小的区域。
感受野是个相对概念,某层feature map上的元素看到前面不同层上的区域范围是不同的,通常在不特殊指定的情况下,感受野指的是看到输入图像上的区域。感受野是可以被计算出来的,其公式为:
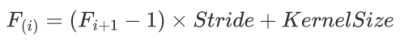
其中,F(i)是第i层的感受野, Stride为第i层的步距, KernelSize是卷积核或者池化核的尺寸。
根据感受野的计算公式公式,Layer3的一个1x1的区域,可以计算出: 对应着Layer2的(1-1)x1+3=3,即3x3的感受野; 对应着Layer1的(3-1)x1+3=5,即5x5的感受野; 假如在Layer1前面还有一个Layer0,那么对应着Layer0的(5-1)x1+3=7,即7x7的感受野。根据这个规律,可以得知,三层3x3的卷积核,就可以和一层7x7的卷积核的感受野是一致的。
3.VggNet的缺点
尽管VggNet在许多方面都表现优秀,但它也有一些缺陷:
- 该网络架构非常大,并且需要大量的计算资源来训练。这意味着,如果你想在较小的设备上使用VggNet,比如移动设备或个人电脑,会发现它非常慢,并且可能无法获得足够的性能。
- 由于VggNet网络架构非常深,它可能会导致梯度消失或爆炸的问题。这是由于在非常深的神经网络中,梯度在传播过程中可能会变得非常小或非常大,从而导致模型无法正常训练。
因此,VggNet网络架构虽然在许多方面都非常优秀,但是要注意这些缺点可能导致的问题。
4.VGGNet使用PyTorch框架实现
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from tqdm import tqdm
# VggNet 模型定义(复用之前的代码)
class VggNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=True, batch_norm=False):
super(VggNet, self).__init__()
self.features = self._make_layers(batch_norm)
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _make_layers(self, batch_norm):
cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# 训练函数
def train_model(model, dataloader, criterion, optimizer, device, num_epochs=25):
model.train() # 设置模型为训练模式
for epoch in range(num_epochs):
running_loss = 0.0
running_corrects = 0
# 进度条显示
progress_bar = tqdm(dataloader, desc=f'Epoch {epoch + 1}/{num_epochs}')
for inputs, labels in progress_bar:
inputs = inputs.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计
_, preds = torch.max(outputs, 1)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
# 更新进度条
progress_bar.set_postfix({
'Loss': loss.item(),
'Acc': torch.sum(preds == labels.data).item() / inputs.size(0)
})
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = running_corrects.double() / len(dataloader.dataset)
print(f'Epoch {epoch + 1}/{num_epochs} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# 评估函数
def evaluate_model(model, dataloader, device):
model.eval() # 设置模型为评估模式
running_loss = 0.0
running_corrects = 0
criterion = nn.CrossEntropyLoss()
with torch.no_grad():
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = running_corrects.double() / len(dataloader.dataset)
print(f'Test Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# 主函数
if __name__ == "__main__":
# 设置设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 数据预处理
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 下载 CIFAR-10 数据集
train_dataset = datasets.CIFAR10(root='./dataset', train=True, download=True, transform=transform_train)
test_dataset = datasets.CIFAR10(root='./dataset', train=False, download=True, transform=transform_test)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False, num_workers=4)
# 创建模型
model = VggNet(num_classes=10, batch_norm=True)
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=5e-4)
# 训练模型
train_model(model, train_loader, criterion, optimizer, device, num_epochs=10)
# 评估模型
evaluate_model(model, test_loader, device)
Using device: cuda:0
Files already downloaded and verified
Files already downloaded and verified
Epoch 1/10: 100%|██████████| 391/391 [07:00<00:00, 1.07s/it, Loss=1.52, Acc=0.412]
Epoch 1/10 Loss: 1.8251 Acc: 0.3147
...
Epoch 10/10: 100%|██████████| 391/391 [06:58<00:00, 1.07s/it, Loss=0.718, Acc=0.725]
Epoch 10/10 Loss: 0.7503 Acc: 0.7351
Test Loss: 0.7162 Acc: 0.7474