本节我们使用 PyTorch 来复现AlexNet网络,解决一个经典的Kaggle图像识别比赛问题。猫狗识别分类问题。
1.数据集处理
这里我们改用kaggle比赛经典的“猫狗大战”数据集了。
该数据集包含的训练集总共25000张图片,猫狗各12500张,带标签;测试集总共12500张,不带标签。我们仅使用带标签的25000张图片,分别拿出2500张猫和狗的图片作为模型的验证集。我们按照以下目录层级结构,将数据集图片放好。
pretreat.py
# 导入所需的库
import os
import random
# 导入数据处理和可视化库
import matplotlib.pyplot as plt
import numpy as np
# 导入深度学习框架 PyTorch 相关库
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 设置随机种子以保证结果的可重复性
def setup_seed(seed):
np.random.seed(seed) # 设置 Numpy 随机种子
random.seed(seed) # 设置 Python 内置随机种子
os.environ['PYTHONHASHSEED'] = str(seed) # 设置 Python 哈希种子
torch.manual_seed(seed) # 设置 PyTorch 随机种子
if torch.cuda.is_available():
torch.cuda.manual_seed(seed) # 设置 CUDA 随机种子
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False # 关闭 cudnn 加速
torch.backends.cudnn.deterministic = True # 设置 cudnn 为确定性算法
# 设置随机种子
setup_seed(0)
# 检查是否有可用的 GPU,如果有则使用 GPU,否则使用 CPU
if torch.cuda.is_available():
device = torch.device("cuda") # 使用 GPU
print("CUDA is available. Using GPU.")
else:
device = torch.device("cpu") # 使用 CPU
print("CUDA is not available. Using CPU.")
transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"test": transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
}
train_dataset = datasets.ImageFolder("./dataset/train", transform=transform["train"])
test_dataset = datasets.ImageFolder("./dataset/test", transform=transform["test"])
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 打印一下图片
examples = enumerate(test_dataloader)
batch_idx, (imgs, labels) = next(examples)
for i in range(4):
mean = np.array([0.5, 0.5, 0.5])
std = np.array([0.5, 0.5, 0.5])
image = imgs[i].numpy() * std[:, None, None] + mean[:, None, None]
# 将图片转成numpy数组,主要是转换通道和宽高位置
image = np.transpose(image, (1, 2, 0))
plt.subplot(2, 2, i+1)
plt.imshow(image)
plt.title(f"Truth: {labels[i]}")
plt.show()
transforms.Resize((224, 224)) 将图像缩放为 224x224 像素,以适应 AlexNet 模型的输入要求。transforms.ToTensor() 将图像转换为张量,transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) 对图像进行归一化,使数据在相似的尺度上,有助于模型训练的稳定性和效率。
datasets.ImageFolder 从指定路径 data_dir 加载图像数据集,并应用前面定义的数据预处理。torch.utils.data.DataLoader 创建数据加载器,batch_size=32 表示每次加载 32 张图像,shuffle=True 表示在每个 epoch 中打乱数据顺序,避免模型学习到固定顺序的模式。class_names 获取数据集中的类别名称。

2.模型构建
AlexNet.py
import torch
from torch import nn
from torchsummary import summary
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, 11, 4, 2),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2),
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2),
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
if __name__ == '__main__':
model = AlexNet().to("cuda")
print(summary(model, (3, 224, 224)))
3.模型训练阶段
train.py
# 导入所需的库
import os
import random
# 导入数据处理和可视化库
import matplotlib.pyplot as plt
import numpy as np
# 导入深度学习框架 PyTorch 相关库
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from AlexNet import AlexNet
# 设置随机种子以保证结果的可重复性
def setup_seed(seed):
np.random.seed(seed) # 设置 Numpy 随机种子
random.seed(seed) # 设置 Python 内置随机种子
os.environ['PYTHONHASHSEED'] = str(seed) # 设置 Python 哈希种子
torch.manual_seed(seed) # 设置 PyTorch 随机种子
if torch.cuda.is_available():
torch.cuda.manual_seed(seed) # 设置 CUDA 随机种子
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False # 关闭 cudnn 加速
torch.backends.cudnn.deterministic = True # 设置 cudnn 为确定性算法
# 设置随机种子
setup_seed(0)
# 检查是否有可用的 GPU,如果有则使用 GPU,否则使用 CPU
if torch.cuda.is_available():
device = torch.device("cuda") # 使用 GPU
print("CUDA is available. Using GPU.")
else:
device = torch.device("cpu") # 使用 CPU
print("CUDA is not available. Using CPU.")
transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"test": transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
}
train_dataset = datasets.ImageFolder("./dataset/train", transform=transform["train"])
test_dataset = datasets.ImageFolder("./dataset/test", transform=transform["test"])
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False)
model = AlexNet(num_classes=2).to(device)
cri = torch.nn.CrossEntropyLoss()
optomizer = torch.optim.Adam(model.parameters(), lr=0.0001)
epoches = 100
for epoch in range(epoches):
model.train()
total_loss = 0
for i, (images, labels) in enumerate(train_dataloader):
# 数据放在设备上
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = cri(outputs, labels)
# 反向传播
optomizer.zero_grad()
loss.backward()
optomizer.step()
total_loss += loss
print(f"Epoch [{epoch + 1}/{epoches}], Iter [{i}/{len(train_dataloader)}], Loss {loss:.4f}")
avg_loss = total_loss / len(train_dataloader)
print(f"Epoch [{epoch + 1}/{epoches}], Loss {avg_loss:.4f}")
if (epoch+1) % 10 == 0:
torch.save(model.state_dict(), f"./model/model_{epoch}.pth")
模型定义: - 使用了 AlexNet 架构,并指定了分类类别数为 2。 - 模型被移动到了设备(CPU 或 GPU)上,这在 PyTorch 中是必要的步骤。
损失函数和优化器: - 使用了 CrossEntropyLoss,适用于多分类任务。 - 使用了 Adam 优化器,学习率为 0.0001,这是一个常见的选择。
训练循环: - 设置了 100 个训练轮次(epochs)。 - 每个 epoch 中,模型被设置为训练模式(model.train())。 - 数据被逐批加载到设备上。 - 前向传播计算输出和损失。 - 反向传播更新模型权重。 - 每个 epoch 结束时,计算并打印平均损失。 - 每 10 个 epoch 保存一次模型权重。
4.模型评估与混淆矩阵
validate.py
# 导入所需的库
import os
import random
# 导入数据处理和可视化库
import matplotlib.pyplot as plt
import numpy as np
# 导入深度学习框架 PyTorch 相关库
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from AlexNet import AlexNet
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 设置随机种子以保证结果的可重复性
def setup_seed(seed):
np.random.seed(seed) # 设置 Numpy 随机种子
random.seed(seed) # 设置 Python 内置随机种子
os.environ['PYTHONHASHSEED'] = str(seed) # 设置 Python 哈希种子
torch.manual_seed(seed) # 设置 PyTorch 随机种子
if torch.cuda.is_available():
torch.cuda.manual_seed(seed) # 设置 CUDA 随机种子
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False # 关闭 cudnn 加速
torch.backends.cudnn.deterministic = True # 设置 cudnn 为确定性算法
# 设置随机种子
setup_seed(0)
# 检查是否有可用的 GPU,如果有则使用 GPU,否则使用 CPU
if torch.cuda.is_available():
device = torch.device("cuda") # 使用 GPU
print("CUDA is available. Using GPU.")
else:
device = torch.device("cpu") # 使用 CPU
print("CUDA is not available. Using CPU.")
transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"test": transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
}
train_dataset = datasets.ImageFolder("./dataset/train", transform=transform["train"])
test_dataset = datasets.ImageFolder("./dataset/test", transform=transform["test"])
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False)
model = AlexNet(num_classes=2).to(device)
cri = torch.nn.CrossEntropyLoss()
optomizer = torch.optim.Adam(model.parameters(), lr=0.0001)
epoches = 100
print("开始验证/评估模型:")
model.load_state_dict(torch.load("./model/model_99.pth"))
#CPU加载
#model.load_state_dict(torch.load("./model/model_99.pth",map_location=torch.device('cpu')))
model.eval()
total = 0
correct = 0
predicted_labels = []
true_labels = []
with torch.no_grad():
for images, labels in test_dataloader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
predicted_labels.extend(predicted.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
print(f"ACC {correct / total * 100}%")
# 生成混淆矩阵
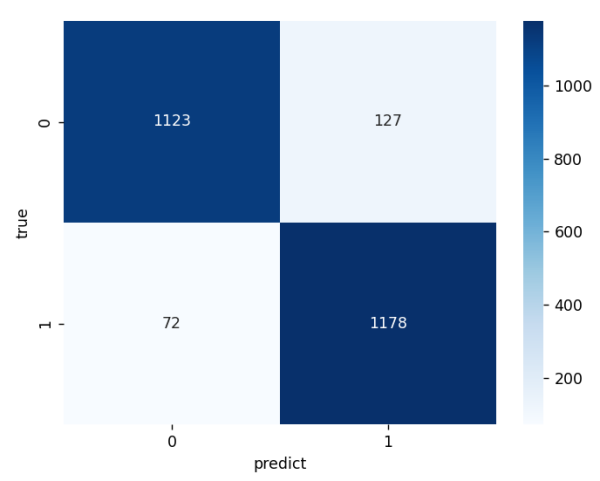
conf = confusion_matrix(true_labels, predicted_labels)
# 可视化
sns.heatmap(conf, annot=True, fmt="d", cmap="Blues")
plt.xlabel("predict")
plt.ylabel("true")
plt.show()
运行效果:
开始验证/评估模型:
ACC 92.04%
5.训练中显示验证指标与保存最好的模型
best_train.py
# 导入所需的库
import os
import random
# 导入数据处理和可视化库
import matplotlib.pyplot as plt
import numpy as np
# 导入深度学习框架 PyTorch 相关库
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from AlexNet import AlexNet
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 设置随机种子以保证结果的可重复性
def setup_seed(seed):
np.random.seed(seed) # 设置 Numpy 随机种子
random.seed(seed) # 设置 Python 内置随机种子
os.environ['PYTHONHASHSEED'] = str(seed) # 设置 Python 哈希种子
torch.manual_seed(seed) # 设置 PyTorch 随机种子
if torch.cuda.is_available():
torch.cuda.manual_seed(seed) # 设置 CUDA 随机种子
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False # 关闭 cudnn 加速
torch.backends.cudnn.deterministic = True # 设置 cudnn 为确定性算法
# 设置随机种子
setup_seed(0)
# 检查是否有可用的 GPU,如果有则使用 GPU,否则使用 CPU
if torch.cuda.is_available():
device = torch.device("cuda") # 使用 GPU
print("CUDA is available. Using GPU.")
else:
device = torch.device("cpu") # 使用 CPU
print("CUDA is not available. Using CPU.")
transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"test": transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
}
train_dataset = datasets.ImageFolder("./dataset/train", transform=transform["train"])
test_dataset = datasets.ImageFolder("./dataset/test", transform=transform["test"])
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False)
model = AlexNet(num_classes=2).to(device)
cri = torch.nn.CrossEntropyLoss()
optomizer = torch.optim.Adam(model.parameters(), lr=0.0001)
epoches = 100
for epoch in range(epoches):
most_acc = 0
model.train()
total_loss = 0
for i, (images, labels) in enumerate(train_dataloader):
# 数据放在设备上
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = cri(outputs, labels)
# 反向传播
optomizer.zero_grad()
loss.backward()
optomizer.step()
total_loss += loss
print(f"Epoch [{epoch + 1}/{epoches}], Iter [{i}/{len(train_dataloader)}], Loss {loss:.4f}")
avg_loss = total_loss / len(train_dataloader)
print(f"Train Data: Epoch [{epoch + 1}/{epoches}], Loss {avg_loss:.4f}")
model.eval()
total, correct, test_loss, total_loss= 0, 0, 0, 0
with torch.no_grad():
for images, labels in test_dataloader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
test_loss = cri(outputs, labels)
total_loss += test_loss
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_test_loss = total_loss / len(test_dataloader)
acc = correct / total
print(f"Test Data: Epoch [{epoch+1}/{epoches}], Loss {avg_test_loss:.4f}, Accuracy {acc * 100}%")
if acc > most_acc:
torch.save(model.state_dict(), f"./model/model_best.pth")
most_acc = acc
if (epoch+1) % 10 == 0:
torch.save(model.state_dict(), f"./model/model_{epoch+1}.pth")