PyTorch 的自动梯度原理可以通俗地理解为:它是一个能自动帮我们计算梯度的工具,就像一个智能的小助手。
1.Variable
在 PyTorch 中,对于 Variable 的定义就是 可以用于求导的 Tensor。将 requires_grad 设置为 True 就可以定义一个变量了。
import torch
# 构建 变量
x = torch.tensor([2.0],requires_grad=True)
# 变量的微分计算式子,该属性有值才能参与微分计算
print(x.grad_fn)
2.动态计算图
PyTorch 中的每个张量(Tensor)都可以设置一个 requires_grad 属性。当我们把 requires_grad 设置为 True 时,PyTorch 就会自动记录对这个张量进行的所有操作,构建一个计算图。在这个计算图中,张量就像是一个个节点,而操作就像是连接这些节点的边。
当我们完成前向传播(forward propagation),也就是计算出损失函数(loss)之后,我们可以通过调用 loss.backward() 来启动反向传播(backward propagation)。在这个过程中,PyTorch 会根据之前记录的操作,按照链式法则自动计算出每个张量的梯度。这些梯度会被存储在张量的 .grad 属性中。
节点表示张量,边表示张量之间运算逻辑。
- 计算图的正向传播是立即执行。
- 计算图在反向传播后立即销毁。
以一个简单的神经元为例:
import torch
import torch.nn.functional as F
def g(x):
return x**2
x = torch.tensor([[2.0],[3.0]],dtype=torch.float,requires_grad=True)
# 变量
w = torch.tensor([[1.0,2.0]],requires_grad=True,dtype=torch.float)
b = torch.tensor([1.0],requires_grad=True,dtype=torch.float)
# 权值计算
z = torch.mm(w,x) + b
# 激活函数
a = g(z)
print(a)
# 是否为叶子结点
print(a.is_leaf,a.grad_fn)
print(x.is_leaf,x.grad_fn)
根据上述计算流程,PyTorch 就能自动搭建一个动态计算图。
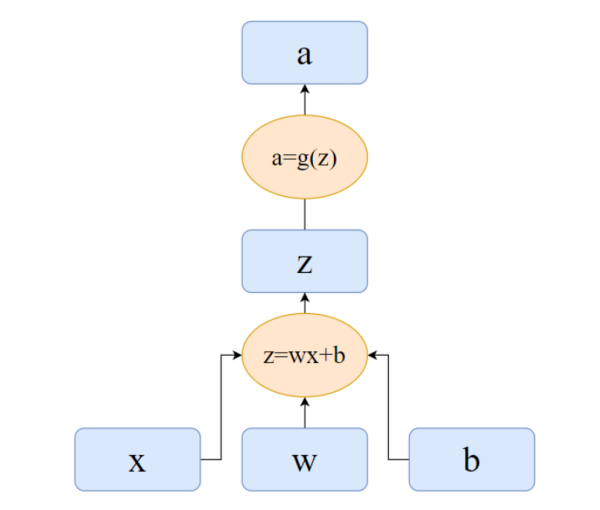
- 叶子结点:计算图的输入,由用户直接定义,不是靠函数关系计算得到。
- 中间结点:通过函数关系,计算得到的中间变量。
- 输出结点:最后的输出结果。
3.反向传播
3.1 梯度求解
同样以神经元为例,为了方便计算,假设激活函数为:g(x)=x^2
则「前向传播」计算流程就为: z=wx+b a=z^2
import torch
import torch.nn.functional as F
def g(x):
return x**2
x = torch.tensor([[2.0],[3.0]],dtype=torch.float,requires_grad=True)
# 变量
w = torch.tensor([[1.0,2.0]],requires_grad=True,dtype=torch.float)
b = torch.tensor([1.0],requires_grad=True,dtype=torch.float)
# 权值计算
z = torch.mm(w,x) + b
# 激活函数
a = g(z)
print(a)
# 从 a 开始反向传播
a.backward()
print(w.grad)
print(b.grad)
print(z.grad)
print(x.grad)
从 a 开始执行「反向传播」
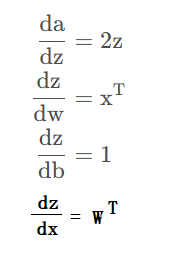
根据链式求导可知:
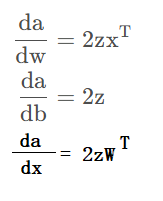
可以获取系数w,b的梯度。 默认情况下,PyTorch 不会保留「中间结点」的梯度,即z的梯度值为 None。
由于我们是从 a 开始进行反向传播的,因此 w.grad 对应的值就是:
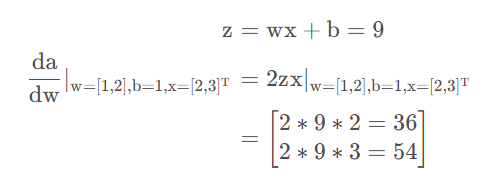
其他同理。
注意: - 计算图中,当某一张量Λ进行「反向传播」,那么「叶子节点Ω」的 grand 属性就是dΛ/dΩ的值。 - 某一张量进行「反向传播」后,计算图将销毁。
运行结果:
tensor([[81.]], grad_fn=<PowBackward0>)
tensor([[36., 54.]])
tensor([18.])
None
tensor([[18.],
[36.]])
3.2 梯度计算控制
阻止计算图追踪(阻止计算梯度)
方式一:
import torch
import torch.nn.functional as F
def g(x):
return x**2
x = torch.tensor([[2.0],[3.0]],dtype=torch.float,requires_grad=True)
# 变量
w = torch.tensor([[1.0,2.0]],requires_grad=True,dtype=torch.float)
b = torch.tensor([1.0],requires_grad=True,dtype=torch.float)
# 权值计算
z = torch.mm(w,x) + b
# 后续计算被计算图屏蔽
with torch.no_grad():
# 激活函数
a = g(z)
print(a)
# 从 a 开始反向传播
a.backward()
print(w.grad)
print(b.grad)
print(z.grad)
print(x.grad)
方式二:
import torch
import torch.nn.functional as F
def g(x):
return x**2
x = torch.tensor([[2.0],[3.0]],dtype=torch.float,requires_grad=True)
# 变量
w = torch.tensor([[1.0,2.0]],requires_grad=True,dtype=torch.float)
b = torch.tensor([1.0],requires_grad=True,dtype=torch.float)
# 权值计算
z = torch.mm(w,x) + b
# 后续计算被计算图屏蔽
z2 =z.detach()
a = g(z2)
print(a)
# 从 a 开始反向传播
a.backward()
print(w.grad)
print(b.grad)
print(z.grad)
print(x.grad)
中间结点梯度保存:
import torch
import torch.nn.functional as F
def g(x):
return x**2
x = torch.tensor([[2.0],[3.0]],dtype=torch.float,requires_grad=True)
# 变量
w = torch.tensor([[1.0,2.0]],requires_grad=True,dtype=torch.float)
b = torch.tensor([1.0],requires_grad=True,dtype=torch.float)
# 权值计算
z = torch.mm(w,x) + b
#中间结点梯度保存
z.retain_grad()
# 激活函数
a = g(z)
print(a)
# 从 a 开始反向传播
a.backward()
print(w.grad)
print(b.grad)
print(z.grad)
print(x.grad)
3.3 自定义梯度计算
实现: 继承torch.autograd.Function类,并重写前向传播forward与反向传播backward方法。
import torch
class line(torch.autograd.Function):
@staticmethod
def forward(ctx, w, b, x):
# 保存输入值,供反向传播的梯度计算
ctx.save_for_backward(w, b, x)
return torch.mm(w, x) + b
@staticmethod
def backward(ctx, grad_output):
print('execute backward....')
""" grad_output:为链式求导法则上一级的导数结果 """
w, b, x = ctx.saved_tensors
dw = torch.mm(grad_output, x.t())
db = grad_output
dx = torch.mm(w.t(),grad_output)
#注意:返回值其实是None,因为 backward() 会将梯度计算结果存储在对应的张量的 .grad 属性中。
return dw, db, dx
x = torch.tensor([[2], [3]], dtype=torch.float,requires_grad=True)
# 变量
w = torch.tensor([[1, 2]], requires_grad=True, dtype=torch.float)
b = torch.tensor([1], requires_grad=True, dtype=torch.float)
# 调用自定义封装
z = line.apply(w, b, x)
# 激活函数
a = z ** 2
# 反向传播
a.backward()
print(w.grad)
print(b.grad)
print(z.grad)
print(x.grad)
运行结果:
execute backward....
tensor([[36., 54.]])
tensor([18.])
None
tensor([[18.],
[36.]])
如果你想执行多次反向传播,只需要添加retain_graph=True参数。
import torch
class line(torch.autograd.Function):
@staticmethod
def forward(ctx, w, b, x):
# 保存输入值,供反向传播的梯度计算
ctx.save_for_backward(w, b, x)
return torch.mm(w, x) + b
@staticmethod
def backward(ctx, grad_output):
print('execute backward....')
""" grad_output:为链式求导法则上一级的导数结果 """
w, b, x = ctx.saved_tensors
dw = torch.mm(grad_output, x.t())
db = grad_output
dx = torch.mm(w.t(), grad_output)
return dw, db, dx
x = torch.tensor([[2], [3]], dtype=torch.float, requires_grad=True)
# 变量
w = torch.tensor([[1, 2]], requires_grad=True, dtype=torch.float)
b = torch.tensor([1], requires_grad=True, dtype=torch.float)
# 调用自定义封装
z = line.apply(w, b, x)
# z.retain_grad()
# 激活函数
a = z ** 2
# 反向传播
#第一次反向传播
a.backward(None, retain_graph=True)
print(w.grad)
print(b.grad)
print(z.grad)
print(x.grad)
#第二次反向传播
a.backward(None, retain_graph=True)
print(w.grad)
print(b.grad)
print(z.grad)
print(x.grad)
运行结果:
execute backward....
tensor([[36., 54.]])
tensor([18.])
None
tensor([[18.],
[36.]])
execute backward....
tensor([[ 72., 108.]])
tensor([36.])
None
tensor([[36.],
[72.]])
4.梯度下降算法
问题:求下面函数的最小值。
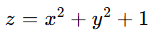
我们可以使用 Python 的 Matplotlib 库。来绘制这个函数的三维曲面图,如下:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 创建网格点
x = np.linspace(-5, 5, 100) # x 的范围从 -5 到 5,共 100 个点
y = np.linspace(-5, 5, 100) # y 的范围从 -5 到 5,共 100 个点
X, Y = np.meshgrid(x, y) # 生成网格点
# 计算 z 值
Z = X**2 + Y**2 + 1
# 创建三维图形
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 绘制曲面
surf = ax.plot_surface(X, Y, Z, cmap='viridis')
# 添加标题和坐标轴标签
ax.set_title('3D Surface of z = x² + y² + 1')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
# 添加颜色条
fig.colorbar(surf, shrink=0.5, aspect=5)
# 显示图形
plt.show()
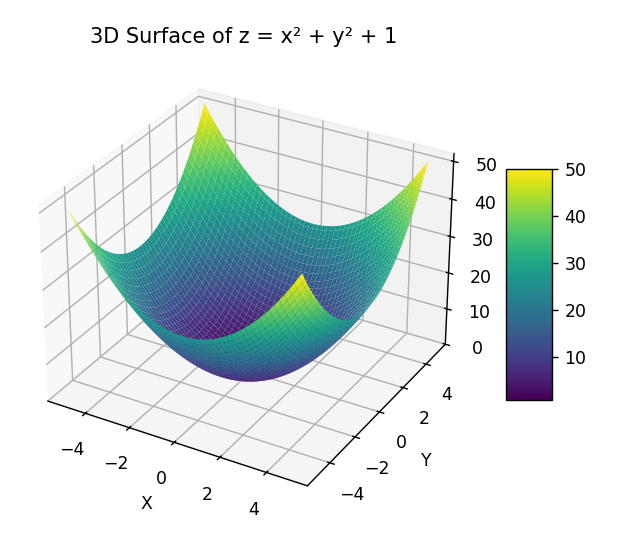
所以求函数: 最小值,就是求这个曲面的最低点问题。
要理解梯度下降算法为什么可以求解这个曲面的最低点,需要先理解梯度的数学原理和性质。
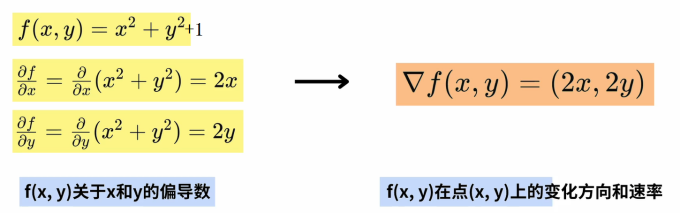
我们知道:梯度(gradient),是多元函数全部偏导数所构成的向量。f(x,y) = x^2 + y^2 +1 的梯度计算过程如下:
为了快速找到这个曲面的最高点(最低点),我们就必须研究从P点出发沿着哪个方向运行能使得f(x,y)增大或者减少最快呢?
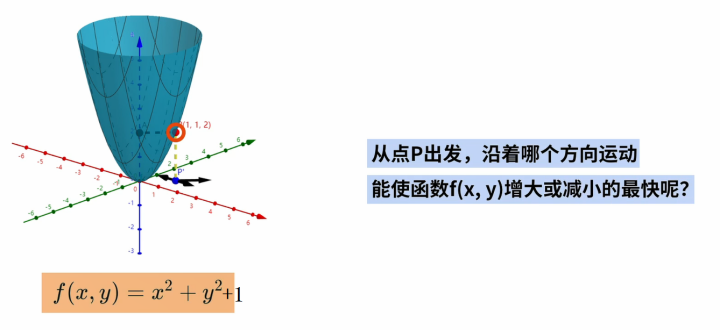
梯度的数学性质是:在函数上的某一点。 - 如果沿着函数梯度的方向运动,函数增加的最快。 - 如果沿着函数梯度的反方向运动,函数减小的最快。
为了证明沿着函数梯度的反方向运动,函数减小的最快,举例如下:

明白了这个道理,我们可以用 PyTorch 实现梯度下降算法来求解函数 的最小值。这个函数是一个简单的凸函数,其最小值在 x=0 和 y=0 处,最小值为 1。我们可以通过梯度下降算法来验证这一点。
代码实现如下:
import torch
# 定义初始参数
x = torch.tensor([2.0], requires_grad=True) # 初始 x 值
y = torch.tensor([3.0], requires_grad=True) # 初始 y 值
# 定义学习率和迭代次数
learning_rate = 0.1
epochs = 100
# 梯度下降循环
for epoch in range(epochs):
# 计算函数值
z = x ** 2 + y ** 2 + 1
# 反向传播计算梯度
z.backward()
# 更新参数
with torch.no_grad():
x -= learning_rate * x.grad
y -= learning_rate * y.grad
# 清空梯度
x.grad.zero_()
y.grad.zero_()
# 打印每步的结果
if (epoch + 1) % 10 == 0:
print(f'Epoch {epoch + 1}/{epochs}, x: {x.item():.4f}, y: {y.item():.4f}, z: {z.item():.4f}')
# 输出最终结果
print(f'\nMinimum value found at x: {x.item():.4f}, y: {y.item():.4f}, z: {z.item():.4f}')
运行结果:
Epoch 10/100, x: 0.2147, y: 0.3221, z: 1.2342
Epoch 20/100, x: 0.0231, y: 0.0346, z: 1.0027
Epoch 30/100, x: 0.0025, y: 0.0037, z: 1.0000
Epoch 40/100, x: 0.0003, y: 0.0004, z: 1.0000
Epoch 50/100, x: 0.0000, y: 0.0000, z: 1.0000
Epoch 60/100, x: 0.0000, y: 0.0000, z: 1.0000
Epoch 70/100, x: 0.0000, y: 0.0000, z: 1.0000
Epoch 80/100, x: 0.0000, y: 0.0000, z: 1.0000
Epoch 90/100, x: 0.0000, y: 0.0000, z: 1.0000
Epoch 100/100, x: 0.0000, y: 0.0000, z: 1.0000
Minimum value found at x: 0.0000, y: 0.0000, z: 1.0000
代码解释
初始化参数: - 我们初始化 x 和 y 为张量,并设置 requires_grad=True,以便 PyTorch 能够自动计算梯度。 - 初始值设为 2.0 和 3.0,这只是任意选择的起点。
学习率和迭代次数: - 学习率(learning_rate)决定了每次更新的步长大小。 - 迭代次数(epochs)决定了我们进行梯度下降的次数。
梯度下降循环:
- 在每次迭代中,我们计算函数z=x^2 + y^2 +1 的值。
- 调用 z.backward() 计算梯度。
- 使用梯度更新 x 和 y 的值,公式为: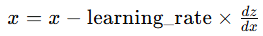 ,同理更新 y。
- 清空梯度,避免在下一次迭代中累积。
,同理更新 y。
- 清空梯度,避免在下一次迭代中累积。
打印结果: - 每 10 次迭代打印一次当前的 x、y 和 z 值,观察收敛过程。 最终结果: - 输出最终找到的最小值点和对应的 z 值。
注意事项 - 学习率的选择很重要,如果学习率太大,可能导致不收敛;如果学习率太小,收敛速度会很慢。 - 初始值的选择也会影响收敛速度,但在这个问题中,由于函数是凸的,无论初始值如何,最终都会收敛到全局最小值。
5.为什么梯度下降最终倾向找到平坦的最低点
需要注意的是:梯度下降算法最终倾向找到平坦的最低点。为什么会倾向于找到平坦的最低点呢?梯度下降的基本原理是沿着损失函数的负梯度方向更新参数,逐步逼近最小值点。那平坦的最低点通常对应着损失函数的一个最小值,可能是一个全局最小值或者局部最小值,但为什么梯度下降更倾向于平坦的呢?主要可以归结为以下几个原因:
- 梯度幅值与收敛稳定性:在平坦区域,损失函数的梯度较小,参数更新步长随之减小。这使得优化过程在接近最小值时更加稳定,容易收敛。相反,陡峭区域的梯度较大,可能导致参数在最小值附近震荡,难以稳定收敛。
- 噪声鲁棒性:在随机梯度下降(SGD)中,噪声的引入使得算法可能逃离尖锐的极小值。平坦区域的损失函数对参数扰动不敏感,噪声对梯度的影响较小,因此算法更可能停留在平坦区域。而陡峭区域的损失值对参数变化敏感,噪声容易导致参数跳出该区域。
- Hessian矩阵与优化路径:平坦区域的Hessian矩阵特征值较小(曲率低),参数更新的误差对损失函数影响有限,形成更宽的“吸引盆地”。优化过程一旦进入平坦区域,容易收敛且不易逃离。陡峭区域的Hessian特征值较大(曲率高),优化路径狭窄,需精确调整参数才能收敛。
- 泛化性能的隐性偏好:虽然梯度下降本身是优化训练损失的数学过程,但经验表明,平坦最小值对应的模型泛化能力更强。这种关联可能通过训练噪声或隐式正则化影响优化方向,使算法间接偏好平坦区域。
总之:梯度下降在平坦区域因梯度小、更新稳定、噪声鲁棒性强及吸引域宽广而更易收敛。这一特性在非凸优化(如深度学习)中尤为显著,使得平坦最小值成为更可能的收敛目标。