分类任务
分类任务
分类任务是机器学习中的一种类型,它的目标很明确:让计算机程序或者模型能够像人一样,根据事物的特征或者属性,把不同的事物归类到不同的组别或者类别中去。
1.分类任务
分类任务的核心概念,就是根据特征把数据分到不同类别里。比如:邮件分类是另一个常见的分类任务场景。比如,邮件系统会根据邮件的内容、发件人、关键词等特征,自动将邮件分为“垃圾邮件”和“非垃圾邮件”。模型通过学习大量已标记的邮件数据,识别出垃圾邮件通常包含的特征,比如特定的广告词汇、发件人地址等,从而在新邮件到达时准确分类。
分类与回归的主要区别: - 输出类型:分类任务输出离散的类别标签,回归任务输出连续的数值。 - 评估方式:分类任务通常使用准确率、召回率、F1分数等指标来评估模型性能;回归任务则常用均方误差(MSE)、平均绝对误差(MAE)等指标。 - 激活函数:分类任务根据任务类型选择sigmoid函数(二分类)或softmax函数(多分类)作为输出层的激活函数,将输出值转换为概率。回归任务的目标是预测一个连续的数值。通常使用线性激活函数(即没有激活函数)作为输出层的激活函数。
2.Pytorch实现圆环分类实例
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为SimHei显示中文
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 生成圆环数据
def generate_ring_data(inner_radius=1.0, outer_radius=5.0, num_samples=1000):
# 内环数据
inner_data = []
r = np.random.uniform(inner_radius - 0.5, inner_radius + 0.5, num_samples // 2)
theta = np.random.uniform(0, 2 * np.pi, num_samples // 2)
inner_x = r * np.cos(theta)
inner_y = r * np.sin(theta)
inner_data = np.stack((inner_x, inner_y), axis=1)
# 外环数据
outer_data = []
r = np.random.uniform(outer_radius - 0.5, outer_radius + 0.5, num_samples // 2)
theta = np.random.uniform(0, 2 * np.pi, num_samples // 2)
outer_x = r * np.cos(theta)
outer_y = r * np.sin(theta)
outer_data = np.stack((outer_x, outer_y), axis=1)
# 合并数据和标签
X = np.concatenate((inner_data, outer_data), axis=0)
y = np.concatenate((np.zeros(num_samples // 2), np.ones(num_samples // 2)))
# 打乱数据
indices = np.random.permutation(num_samples)
X = X[indices]
y = y[indices]
return X, y
# 定义模型
class RingClassifier(nn.Module):
def __init__(self):
super(RingClassifier, self).__init__()
self.fc1 = nn.Linear(2, 16) # 输入层到隐藏层
self.fc2 = nn.Linear(16, 32) # 隐藏层到隐藏层
self.fc3 = nn.Linear(32, 1) # 隐藏层到输出层
self.sigmoid = nn.Sigmoid() # 二分类激活函数
self.relu = nn.ReLU() # 隐藏层激活函数
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.sigmoid(self.fc3(x))
return x
# 主函数
def main():
# 生成数据
X, y = generate_ring_data()
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.float32).reshape(-1, 1)
# 划分训练集和测试集
train_size = int(0.8 * len(X))
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# 定义模型、损失函数和优化器
model = RingClassifier()
criterion = nn.BCELoss() # 二分类交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 训练模型
epochs = 1000
losses = []
accuracies = []
for epoch in range(epochs):
# 前向传播
outputs = model(X_train)
loss = criterion(outputs, y_train)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录损失和精确率
with torch.no_grad():
# 训练集精确率
predicted = (outputs > 0.5).float()
accuracy = (predicted == y_train).sum().item() / len(y_train)
accuracies.append(accuracy)
losses.append(loss.item())
# 测试集精确率
test_outputs = model(X_test)
test_predicted = (test_outputs > 0.5).float()
test_accuracy = (test_predicted == y_test).sum().item() / len(y_test)
if (epoch + 1) % 100 == 0:
print(
f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}, Train Accuracy: {accuracy:.4f}, Test Accuracy: {test_accuracy:.4f}')
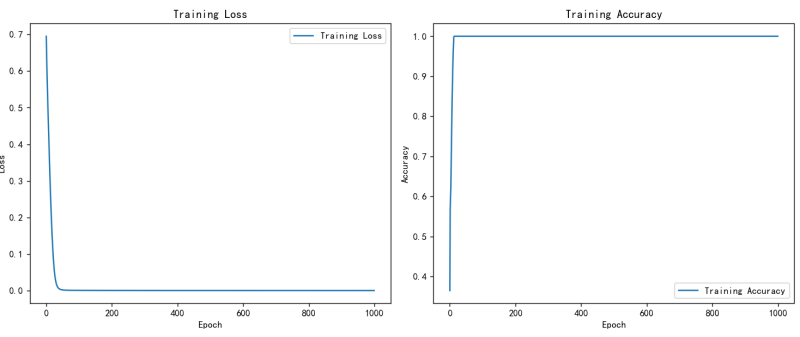
# 可视化损失和精确率
plt.figure(figsize=(12, 5))
# 损失曲线
plt.subplot(1, 2, 1)
plt.plot(losses, label='Training Loss')
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# 精确率曲线
plt.subplot(1, 2, 2)
plt.plot(accuracies, label='Training Accuracy')
plt.title('Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.show()
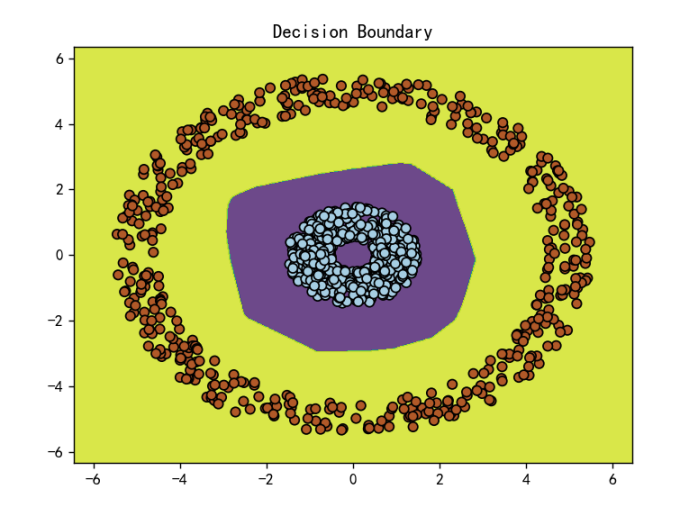
# 可视化分类结果
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 预测网格点的类别
grid_tensor = torch.tensor(np.c_[xx.ravel(), yy.ravel()], dtype=torch.float32)
with torch.no_grad():
Z = model(grid_tensor)
Z = (Z > 0.5).float().numpy()
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.Paired)
plt.title('Decision Boundary')
plt.show()
if __name__ == "__main__":
main()
运行效果: