正则化是神经网络等机器学习模型中一个很重要的概念,正则化的目的是防止神经网络中出现过拟合。
1.正则化
正则化是神经网络等机器学习模型中一个很重要的概念,你可以把它想象成一种 “约束手段”。 当我们在训练神经网络时,它会根据大量的训练数据来调整内部的参数,从而学会对新数据进行预测或者分类等任务。但是,有时候网络会过于 “努力” 地去学习训练数据中的细节,包括一些噪声或者一些很特殊的、只在训练数据中偶然出现的模式,这就导致了 “过拟合” 的现象。过拟合的模型在训练数据上表现得非常好,但在新的、未见过的数据上却表现得很差。
假设现有两个训练好的线性模型:
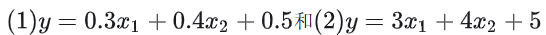
这两个模型哪一个更好?(这两个模型,在训练集上是一致的,只不过是权重放大了十倍(可以化简)不影响训练的准确度)显然权重系数小的更更好,也就是(1)好。因为w越小,模型的容错能力就越好!
我们知道训练神经网络的目的是找到损失函数的最小值,问题是就算每次训练的损失函数最小值的相同的,但是得到的w和b也是一组一组不同的值,有可能得到一组数值非常大的w和b,也有可能得到一组数值非常小的w和b,具体怎么理解呢?看下面的例子:
假设一个在训练数据的样本是(10,10,18)。而现实数据是一个有点偏差的样本(8,8,10)。把(8,8,10)这个数据, 分别带入我们的模型(1)和(2),很容易得: 模型(1) : y1 = 0.3 * 8+0.4 * 8 + 0.5 = 22.9 模型(2) : y2 = 3 * 8+ 4 * 8 + 5 = 229
比较y1 和 y2可以发现,现实样本的一点偏差就导致了预测结果的巨大偏差。因为,权重系数大,就会放大这种小的偏差,并随着特征维度的增加而爆炸增加!!!
正则化的作用 : 让机器保证正确率的同时,训练出小的W系数。
为了避免过拟合,最常用的一种方法是使用使用正则化,有 L1 和 L2 正则化。
2.L1正则化
L1正则化使用了曼哈顿距离:
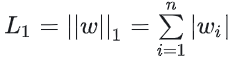
L1 正则化 (Lasso) - L1 正则化会在损失函数中加入所有权重的绝对值之和作为惩罚项。 - 该方法倾向于产生稀疏的模型,即很多权重会变为0,因此它可以用于特征选择。
下面是pytorch实现L1正则化的例子。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 64) # 输入层到隐藏层
self.fc2 = nn.Linear(64, 1) # 隐藏层到输出层
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 创建网络实例
net = SimpleNet()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 假设我们有一些训练数据
# 这里用随机数据代替实际数据
inputs = torch.randn(100, 10) # 100 个样本,每个样本 10 个特征
labels = torch.randn(100, 1) # 对应的标签
# 设置 L1 正则化的超参数
lambda_l1 = 0.001
# 训练网络
for epoch in range(10000):
# 前向传播
outputs = net(inputs)
loss = criterion(outputs, labels)
# 添加 L1 正则化项
l1_reg = torch.tensor(0.)
for param in net.parameters():
l1_reg += torch.sum(torch.abs(param))
loss += lambda_l1 * l1_reg
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每 100 个 epoch 打印一次损失
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/1000], Loss: {loss.item():.4f}')
print('Training finished!')
运行结果,我们训练一万轮次,损失函数不断减少:
Epoch [100/1000], Loss: 1.0029
Epoch [200/1000], Loss: 0.9157
Epoch [300/1000], Loss: 0.8296
Epoch [400/1000], Loss: 0.7458
...
Epoch [9800/1000], Loss: 0.1314
Epoch [9900/1000], Loss: 0.1311
Epoch [10000/1000], Loss: 0.1308
Training finished!
代码解析
定义网络结构: - 我们定义了一个简单的神经网络 SimpleNet,它有一个输入层(10 个特征)、一个隐藏层(64 个神经元)和一个输出层(1 个输出)。 - 使用了 ReLU 激活函数来引入非线性。
定义损失函数和优化器: - 损失函数使用均方误差损失(MSELoss),这是回归问题中常用的损失函数。 - 优化器使用随机梯度下降(SGD),学习率为 0.01。
生成模拟数据:我们生成了 100 个样本,每个样本有 10 个特征,对应的标签也是随机生成的。
设置 L1 正则化超参数:lambda_l1 是 L1 正则化的超参数,控制正则化的强度。这里设置为 0.001。
训练过程: - 在每个 epoch 中,首先进行前向传播,计算输出和损失。 - 然后计算 L1 正则化项,即所有参数的绝对值之和。 - 将 L1 正则化项加到原始损失中,得到总的损失。 - 通过反向传播计算梯度,并使用优化器更新网络参数。
通过这种方式,我们在训练过程中加入了 L1 正则化,使得模型在学习过程中不仅考虑拟合数据,还会尽量让参数的绝对值之和较小,从而达到防止过拟合的目的。
3.L2正则化
L2正则化使用了欧氏距离:
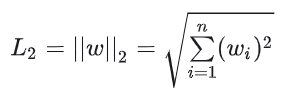
L2 正则化 (Ridge) - L2 正则化会在损失函数中加入所有权重的平方和作为惩罚项。 - 与L1不同,L2不会让权重变成零,而是将它们缩小,使得模型更加平滑。
下面是pytorch实现L2正则化的例子。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 64) # 输入层到隐藏层
self.fc2 = nn.Linear(64, 1) # 隐藏层到输出层
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 创建网络实例
net = SimpleNet()
# 定义损失函数和优化器
criterion = nn.MSELoss()
# 在定义优化器时,设置 weight_decay 参数即为 L2 正则化的超参数
optimizer = optim.SGD(net.parameters(), lr=0.01, weight_decay=0.001)
# 假设我们有一些训练数据
# 这里用随机数据代替实际数据
inputs = torch.randn(100, 10) # 100 个样本,每个样本 10 个特征
labels = torch.randn(100, 1) # 对应的标签
# 训练网络
for epoch in range(10000):
# 前向传播
outputs = net(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每 100 个 epoch 打印一次损失
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/1000], Loss: {loss.item():.4f}')
print('Training finished!')
运行结果,我们训练一万轮次,损失函数不断减少:
Epoch [100/1000], Loss: 0.7764
Epoch [200/1000], Loss: 0.7165
Epoch [300/1000], Loss: 0.6671
...
Epoch [9900/1000], Loss: 0.0009
Epoch [10000/1000], Loss: 0.0008
Training finished!
代码解析
定义网络结构:
和之前的 L1 正则化例子一样,我们定义了一个简单的神经网络 SimpleNet,它有一个输入层(10 个特征)、一个隐藏层(64 个神经元)和一个输出层(1 个输出),使用了 ReLU 激活函数。
定义损失函数和优化器: - 损失函数仍然使用均方误差损失(MSELoss)。 - 在定义优化器时,我们设置了 weight_decay 参数,这个参数就是 L2 正则化的超参数 λ。weight_decay=0.001 表示我们使用了强度为 0.001 的 L2 正则化。
生成模拟数据:我们生成了 100 个样本,每个样本有 10 个特征,对应的标签也是随机生成的。
训练过程: - 在每个 epoch 中,进行前向传播,计算输出和损失。 - 然后进行反向传播,计算梯度,并使用优化器更新网络参数。 - 由于我们在优化器中设置了 weight_decay,所以在参数更新时,L2 正则化会自动生效,相当于在损失函数中加入了 L2 正则化项。
通过这种方式,我们在训练过程中加入了 L2 正则化,使得模型在学习过程中不仅考虑拟合数据,还会尽量让参数的平方和较小,从而达到防止过拟合的目的。
4.Dropout
Dropout也是一种正则化技术。它在深度学习中被广泛应用,特别是在深度神经网络中,用于防止过拟合。Dropout的核心思想是在训练过程中随机地“丢弃”(即暂时移除)网络中的一些神经元(及其连接),从而减少模型对训练数据的过度拟合,增强模型的泛化能力。
在训练阶段,每个神经元以一定的概率被随机丢弃,不参与前向传播和反向传播,这迫使网络中的其他神经元不能过度依赖于某些特定的神经元,从而学习到更加鲁棒的特征表示。在测试阶段,所有神经元都被保留,但为了补偿训练时丢弃的神经元,每个神经元的输出需要乘以保留概率。
Dropout通过这种方式有效地减少了神经元之间的共适应性,使得模型在面对新的、未见过的数据时也能表现良好。它在实际应用中被证明是非常有效的,特别是在大型神经网络的训练中,可以显著降低过拟合的风险。
下面是pytorch实现Dropout正则化的例子。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络,加入Dropout正则化
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 64) # 输入层到隐藏层
self.dropout = nn.Dropout(p=0.5) # Dropout层,p为丢弃概率
self.fc2 = nn.Linear(64, 1) # 隐藏层到输出层
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.dropout(x) # 在隐藏层后加入Dropout
x = self.fc2(x)
return x
# 创建网络实例
net = SimpleNet()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 假设我们有一些训练数据
# 这里用随机数据代替实际数据
inputs = torch.randn(100, 10) # 100 个样本,每个样本 10 个特征
labels = torch.randn(100, 1) # 对应的标签
# 训练网络
for epoch in range(10000):
# 前向传播
outputs = net(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每 100 个 epoch 打印一次损失
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}], Loss: {loss.item():.4f}')
print('Training finished!')