过拟合和欠拟合是机器学习中模型性能问题的两种典型表现,核心差异在于模型复杂度与数据规律的匹配程度。
1.什么是欠拟合和过拟合
欠拟合:指模型无法很好地拟合训练数据,无法捕捉到数据中的关键特征和模式。通常出现在模型过于简单或特征提取不足的情况下。解决欠拟合的方法包括增加模型复杂度、增加特征数量、减少正则化等。
过拟合:指模型在训练数据上表现良好,但在新数据上表现较差,过度拟合了训练数据中的噪声和随机性。通常出现在模型过于复杂、训练数据过少或特征过多的情况下。解决过拟合的方法包括增加训练数据、特征选择、正则化、交叉验证等。
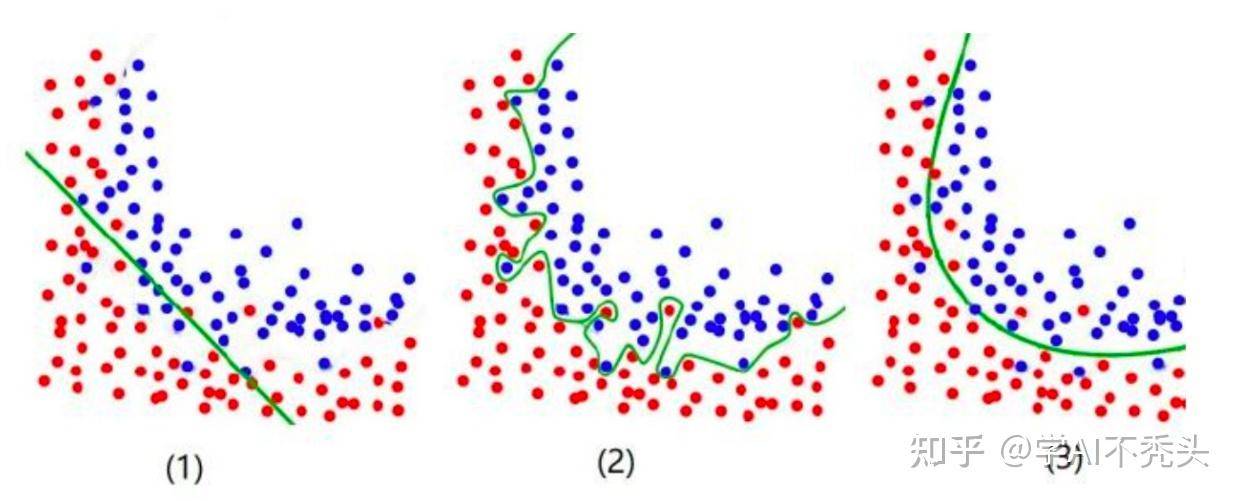
- 欠拟合,划分的决策边界很多 红点 在 蓝点的范围内(效果差,错误率高)
- 过拟合,在训练数据中,拟合出来的效果很好。但是,数据集也会有噪声,例如图2中,决策边界凸出来,把在蓝色群体中的红点分了出来。但是根据普遍情况,在现实中,一般该点与周围的点是属于同一类的。(混同一个全圈子的人,会聚类)。这些混入蓝点领域的红点很有可能是噪声点,而模型却把他定位为数据的一个特征分了出来。这种情况下,到现实世界中往往预测的效果会比训练效果大打折扣。
- 刚刚好,允许犯错,更具有普适性。更符合常理。
2.欠拟合
欠拟合是指机器学习模型未能充分学习到数据中的规律和模式,导致模型在训练数据和新数据上预测性能都较差的现象。换句话说,模型过于简单,无法准确地捕捉数据中的复杂关系。
欠拟合产生原因有以下几个:
- 模型复杂度不足 :例如,使用线性模型去拟合非线性数据。假设真实数据分布是一个二次函数关系,但模型只是一个一次线性模型,那么无论怎样调整模型参数,都无法很好地拟合数据,从而导致欠拟合。
- 训练时间不足 :模型还没有学习到足够的数据特征和模式就被停止训练,导致性能不佳。比如一个深度神经网络,如果训练 epoch 数(训练轮数)设置得过少,网络还未充分更新权重参数,就容易出现欠拟合。
- 正则化过度 :正则化是用来防止模型过拟合的手段,但如果正则化系数设置得过大,会对模型的复杂度进行过度限制。例如,在 L2 正则化中,过大的正则化系数会使模型的权重参数趋向于 0,从而使模型变得过于简单而欠拟合。
下面是一个欠拟合的简单示例:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用 SimHei 字体(黑体)
plt.rcParams['axes.unicode_minus'] = False # 用于显示负号
# 生成模拟数据
np.random.seed(42)
X = np.linspace(-1, 1, 100).reshape(-1, 1) # 输入特征
y = 2 * X**2 + 3 * X + 5 + np.random.normal(0, 0.1, X.shape) # 目标值(带噪声)
# 转换为 PyTorch 张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.linear = nn.Linear(1, 1) # 只有一层简单的线性层
def forward(self, x):
return self.linear(x)
# 创建模型实例
model = SimpleModel()
# 均方误差损
criterion = nn.MSELoss()
# 随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_tensor)
loss = criterion(outputs, y_tensor)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每 10 个 epoch 打印一次损失
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 可视化结果
with torch.no_grad():
y_pred = model(X_tensor).numpy()
plt.figure(figsize=(10, 6))
plt.scatter(X, y, label='真实数据', color='blue', alpha=0.6)
plt.plot(X, y_pred, label='模型预测', color='red', linewidth=2)
plt.xlabel('X')
plt.ylabel('y')
plt.title('欠拟合示例')
plt.legend()
plt.show()
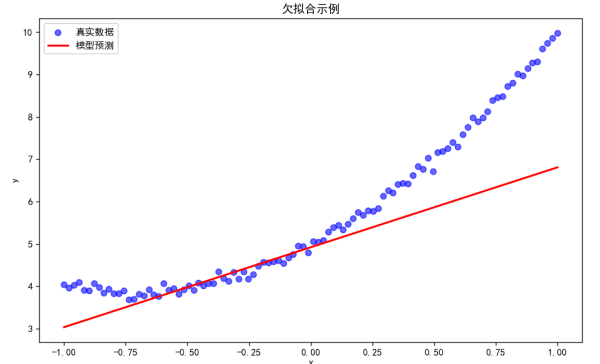
欠拟合原因分析:
在上述代码中,我们使用了一个简单的线性模型去拟合一个二次函数关系的数据。由于模型的复杂度不足,它无法很好地学习到数据中的非线性关系,导致欠拟合。从可视化结果中可以看到,模型的预测线(红色)与真实数据点(蓝色)之间的差距较大,说明模型未能很好地拟合数据。
运行上述代码后,你将看到一个图像,其中: - 蓝色散点表示真实数据。 - 红色线条表示模型的预测结果。
由于模型过于简单(只有线性层),红色线条会显得过于平直,无法很好地捕捉数据的非线性趋势,这就是欠拟合的典型表现。你可以通过增加模型的复杂度(例如添加隐藏层或使用非线性激活函数)来改善模型的拟合能力。
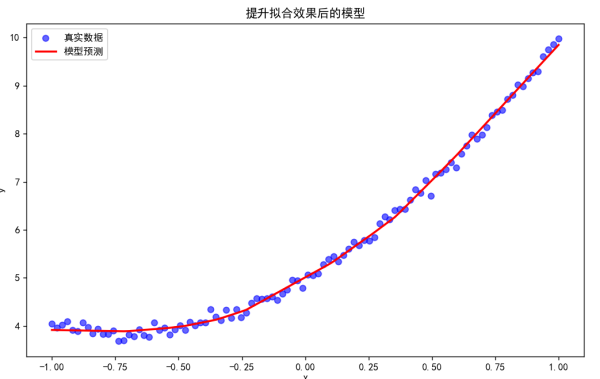
我们可以通过增加模型的复杂度来提升拟合效果,代码修改如下:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用 SimHei 字体(黑体)
plt.rcParams['axes.unicode_minus'] = False # 用于显示负号
# 生成模拟数据
np.random.seed(42)
X = np.linspace(-1, 1, 100).reshape(-1, 1) # 输入特征
y = 2 * X**2 + 3 * X + 5 + np.random.normal(0, 0.1, X.shape) # 目标值(带噪声)
# 转换为 PyTorch 张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)
# 定义更复杂的神经网络模型
class ComplexModel(nn.Module):
def __init__(self):
super(ComplexModel, self).__init__()
self.layer1 = nn.Linear(1, 32) # 输入层到隐藏层
self.layer2 = nn.Linear(32, 32) # 隐藏层到隐藏层
self.layer3 = nn.Linear(32, 1) # 隐藏层到输出层
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
x = self.relu(self.layer1(x))
x = self.relu(self.layer2(x))
x = self.layer3(x)
return x
# 创建模型实例
model = ComplexModel()
# 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 优化器
# 训练模型
num_epochs = 500
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_tensor)
loss = criterion(outputs, y_tensor)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每 100 个 epoch 打印一次损失
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 可视化结果
with torch.no_grad():
y_pred = model(X_tensor).numpy()
plt.figure(figsize=(10, 6))
plt.scatter(X, y, label='真实数据', color='blue', alpha=0.6)
plt.plot(X, y_pred, label='模型预测', color='red', linewidth=2)
plt.xlabel('X')
plt.ylabel('y')
plt.title('提升拟合效果后的模型')
plt.legend()
plt.show()
3.过拟合
过拟合是指模型在训练数据上表现得非常好,但在未见过的新数据(测试数据)上性能却很差的情况。这是因为模型学习到了训练数据中的噪声和细节,而这些噪声和细节并不能泛化到新数据中。
过拟合产生原因:
- 模型复杂度高 :当模型的参数过多,例如一个深度神经网络的层数太多、神经元数量过多,模型具有很强的拟合能力。它可能会把训练数据中的每一个点,包括噪声点,都很好地拟合,导致过拟合。比如说,在一个分类问题中,模型为了使训练数据中的每一个样本都分类正确,会调整决策边界去适应噪声点。
- 训练数据量不足 :当训练数据较少时,模型更容易过拟合。因为少量的数据可能无法代表整体数据分布,模型很容易记住这些少量数据的细节。例如,在一个图像分类问题中,如果有 100 张图像作为训练数据,而模型又很复杂,那么模型可能会过度拟合这 100 张图像的特点,而无法泛化到更多的图像数据上。
- 数据噪声大 :如果训练数据中存在大量的噪声,模型可能会把噪声也当作数据的一部分特征来学习。例如,在一个语音识别系统中,如果训练语音数据中有很多背景噪音,且模型没有很好地处理这些噪音,就可能过拟合这些噪声。
下面是一个过拟合的简单示例:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用 SimHei 字体(黑体)
plt.rcParams['axes.unicode_minus'] = False # 用于显示负号
# 生成模拟数据
np.random.seed(42)
X = np.linspace(-1, 1, 100).reshape(-1, 1) # 输入特征
y = 2 * X ** 2 + 3 * X + 5 + np.random.normal(0, 0.5, X.shape) # 增加更多噪声
# 转换为 PyTorch 张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)
class ComplexModel(nn.Module):
def __init__(self):
super(ComplexModel, self).__init__()
self.layer1 = nn.Linear(1, 64) # 输入层到隐藏层
self.layer2 = nn.Linear(64, 64) # 隐藏层到隐藏层
self.layer3 = nn.Linear(64, 1) # 隐藏层到输出层
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
x = self.relu(self.layer1(x))
x = self.relu(self.layer2(x))
x = self.layer3(x)
return x
# 创建模型实例
model = ComplexModel()
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 优化器
# 训练模型
num_epochs = 2000
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_tensor)
loss = criterion(outputs, y_tensor)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每 200 个 epoch 打印一次损失
if (epoch + 1) % 200 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 可视化结果
with torch.no_grad():
y_pred = model(X_tensor).numpy()
plt.figure(figsize=(10, 6))
plt.scatter(X, y, label='真实数据', color='blue', alpha=0.6)
plt.plot(X, y_pred, label='模型预测', color='red', linewidth=2)
plt.xlabel('X')
plt.ylabel('y')
plt.title('过拟合示例')
plt.legend()
plt.show()
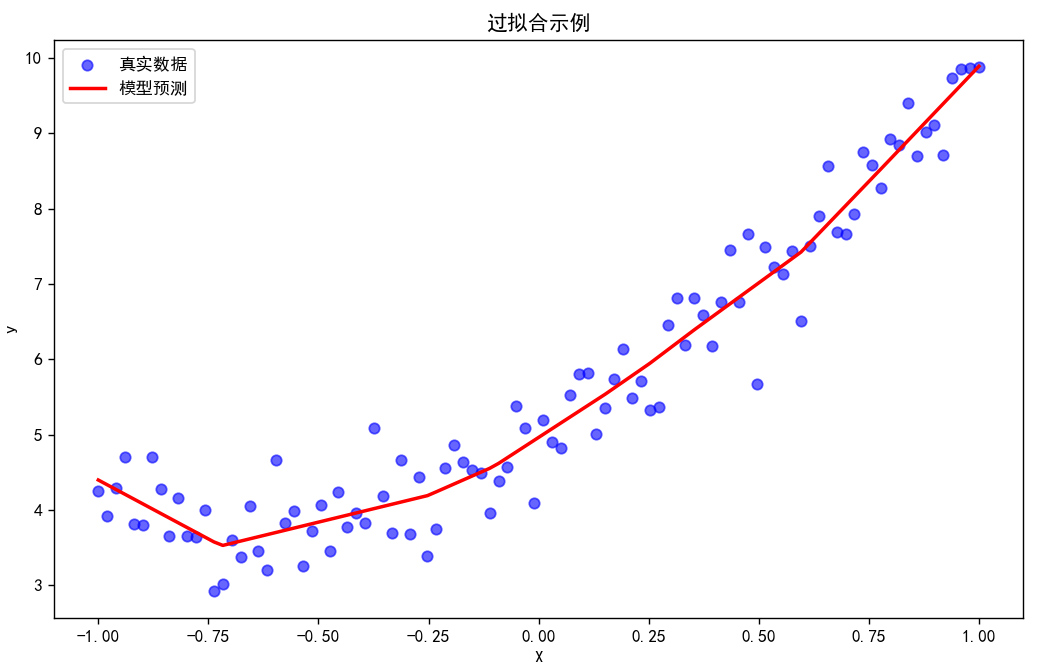
在上述代码中,我们使用了一个复杂的神经网络模型来拟合一个简单的非线性数据。由于模型的复杂度较高,它可能会过拟合训练数据,即学习到了数据中的噪声和细节。从可视化结果中可以看到,模型的预测线(红色)可能会过度波动,试图拟合每一个训练数据点,包括噪声点,导致在新的测试数据上表现不佳。
输出结果 运行上述代码后,你将看到一个图像,其中: - 蓝色散点表示真实数据。 - 红色线条表示模型的预测结果。
由于模型过于复杂,红色线条会显得过于波动,试图拟合每一个训练数据点,这就是过拟合的典型表现。
为了减少过拟合,可以尝试以下方法: 1. 增加数据量:增加训练数据的样本数量。 2. 减少模型复杂度:减少神经网络的层数或神经元数量。 3. 使用正则化:在损失函数中添加正则化项(如 L1 或 L2 正则化)。 4. 使用 dropout:在训练过程中随机失活一部分神经元,防止模型过度依赖某些特征。
以下是修改后的代码,使用 L2 正则化来减少过拟合:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用 SimHei 字体(黑体)
plt.rcParams['axes.unicode_minus'] = False # 用于显示负号
# 生成模拟数据
np.random.seed(42)
X = np.linspace(-1, 1, 100).reshape(-1, 1) # 输入特征
y = 2 * X ** 2 + 3 * X + 5 + np.random.normal(0, 0.5, X.shape) # 增加更多噪声
# 转换为 PyTorch 张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)
class ComplexModel(nn.Module):
def __init__(self):
super(ComplexModel, self).__init__()
self.layer1 = nn.Linear(1, 64) # 输入层到隐藏层
self.layer2 = nn.Linear(64, 64) # 隐藏层到隐藏层
self.layer3 = nn.Linear(64, 1) # 隐藏层到输出层
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
x = self.relu(self.layer1(x))
x = self.relu(self.layer2(x))
x = self.layer3(x)
return x
# 创建模型实例
model = ComplexModel()
# 定义损失函数和优化器,添加 L2 正则化
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.01, weight_decay=0.05) # 添加 L2 正则化
# 重新训练模型
num_epochs = 2000
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_tensor)
loss = criterion(outputs, y_tensor)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每 200 个 epoch 打印一次损失
if (epoch + 1) % 200 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 可视化结果
with torch.no_grad():
y_pred = model(X_tensor).numpy()
plt.figure(figsize=(10, 6))
plt.scatter(X, y, label='真实数据', color='blue', alpha=0.6)
plt.plot(X, y_pred, label='模型预测', color='red', linewidth=2)
plt.xlabel('X')
plt.ylabel('y')
plt.title('减少过拟合后的模型')
plt.legend()
plt.show()
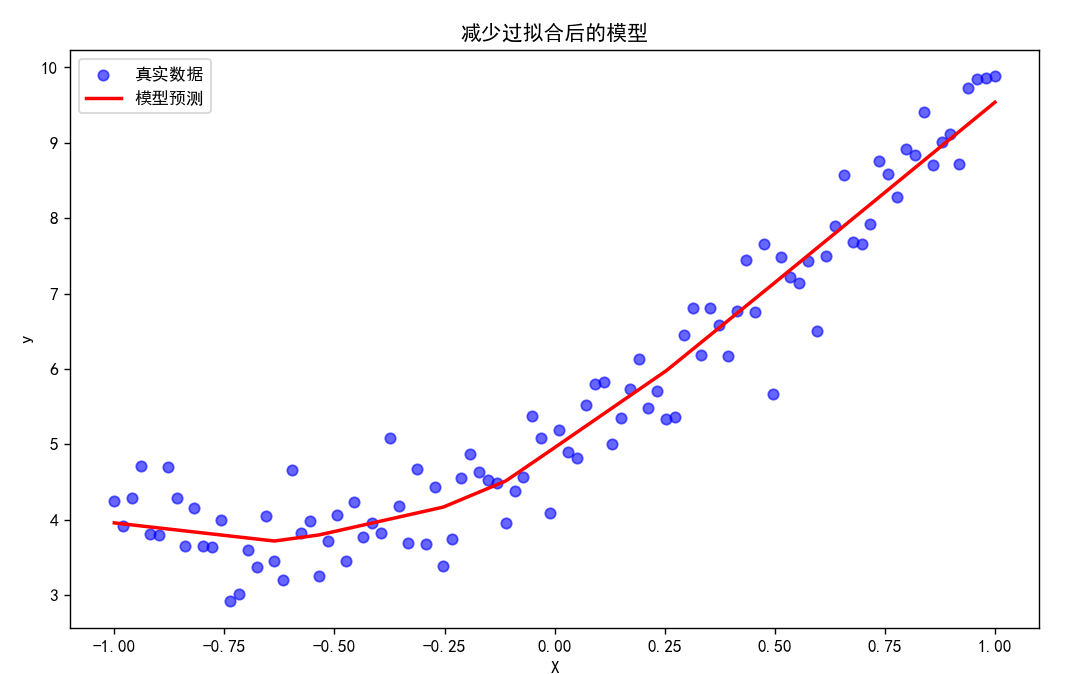
我们发现通过使用 L2 正则化,模型的预测线会更加平滑,减少对噪声的过度拟合。