在深度学习中,优化器(Optimizer)是一个核心概念,它负责调整神经网络的权重和偏置,以便最小化损失函数,从而提高模型的准确性和性能。
1.优化器
优化器是一种特定的深度学习算法,用于在训练深度学习模型时调整权重和偏差,从而更新神经网络参数以最小化某个损失函数。损失函数衡量了模型的预测值与真实值之间的差异,而优化器的目标是通过调整网络参数来最小化这个差异,从而提高模型的准确性和性能。
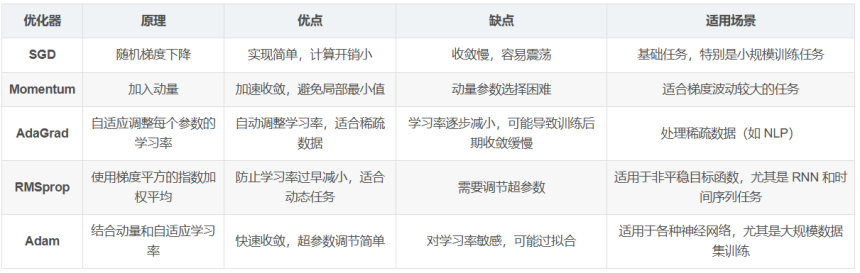
常用的优化器主要包括SGD、BGD、Momentum、NAG、Adagrad、RMSprop、Adadelta和Adam等,它们通过不同的策略调整学习率和梯度方向,以实现快速、稳定的模型训练。
2.SGD原理
随机梯度下降(Stochastic Gradient Descent,SGD)是一种常用的优化算法,用于训练机器学习模型特别是神经网络。它通过迭代地更新模型参数来最小化损失函数。
SGD的工作原理: 1. 随机选择一个样本(或一个小批量样本)。 2. 计算该样本(或小批量样本)的梯度。 3. 按照梯度的反方向更新模型参数。 4. 重复上述步骤,直到满足停止条件(如达到最大迭代次数或损失函数收敛)。
这种方法是最朴素的梯度下降方法,将全部的数据样本输入网络计算梯度后进行一次更新,其数学公式如下:

优点: - 计算效率高,因为每次只使用一个样本或小批量样本,减少了计算量。 - 可以快速收敛到损失函数的最小值,尤其是在损失函数不平整时。 - 有助于逃避免局部最小值。
缺点: - 由于噪声较大,损失函数的下降过程可能不稳定。 - 需要仔细选择学习率,否则可能发散或收敛过慢。
如何选择学习率:
- 固定学习率:在整个训练过程中使用一个固定的学习率。
- 学习率衰减:随着训练的进行,逐渐降低学习率。
- 自适应学习率:如Adam、RMSprop等优化器,可以自动调整学习率。
下面是使用SGD训练一个简单的线性回归模型的例子:
import numpy as np
# 使用SGD训练一个简单的线性回归模型
# 生成一些伪数据
np.random.seed(0)
X = np.random.rand(100, 1)
y = 3 * X + 2
# 初始化参数
theta = np.random.randn(2, 1)
print("Initial parameters:", theta)
learning_rate = 0.01
iterations = 100000
# 添加偏置项
X_b = np.c_[np.ones((100, 1)), X]
#print("X_b:", X_b)
for i in range(iterations):
# 随机选择一个样本
idx = np.random.randint(0, 100)
xi = X_b[idx:idx + 1]
yi = y[idx:idx + 1]
# 计算预测值
predictions = np.dot(xi, theta)
# 计算梯度
gradient = 2 * xi.T.dot(predictions - yi)
#观察梯度下降的过程
#print("gradient:", gradient)
# 更新参数
theta -= learning_rate * gradient
print("Learned parameters:")
print(theta)
输出结果:
Initial parameters: [[-1.16514984]
[ 0.90082649]]
Learned parameters:
[[2.]
[3.]]
这里我们重点解释一下损失函数对参数 θ 的梯度,即均方误差(MSE)损失函数对参数 θ 的导数,这行代码的含义。
gradient = 2 * xi.T.dot(predictions - yi)
我们知道MES公式为:
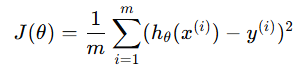

计算梯度: - 梯度是损失函数对参数 θ 的导数,表示损失函数在参数空间中的变化方向。 - 梯度下降通过沿着梯度的反方向更新参数,以最小化损失函数。


我们也可以把上边代码里面,观察梯度下降过程的代码注释打开,观察整个梯度下降的过程,这样更直观的理解损失函数对参数 θ 的梯度的求解过程。
import numpy as np
# 使用SGD训练一个简单的线性回归模型
# 生成一些伪数据
np.random.seed(0)
X = np.random.rand(100, 1)
y = 3 * X + 2
# 初始化参数
theta = np.random.randn(2, 1)
print("Initial parameters:", theta)
learning_rate = 0.01
iterations = 1000
# 添加偏置项
X_b = np.c_[np.ones((100, 1)), X]
#print("X_b:", X_b)
for i in range(iterations):
# 随机选择一个样本
idx = np.random.randint(0, 100)
xi = X_b[idx:idx + 1]
yi = y[idx:idx + 1]
# 计算预测值
predictions = np.dot(xi, theta)
# 计算梯度
gradient = 2 * xi.T.dot(predictions - yi)
#观察梯度下降的过程
print("gradient:", gradient)
# 更新参数
theta -= learning_rate * gradient
print("Learned parameters:")
print(theta)
运行程序,我们发现梯度是不断下降的,最终下降到一个很小的范围。
Initial parameters: [[-1.16514984]
[ 0.90082649]]
gradient: [[-9.81047759]
[-8.13229758]]
gradient: [[-9.86952148]
[-9.1351959 ]]
gradient: [[-7.32188262]
[-2.63227465]]
gradient: [[-9.50229767]
[-9.28147462]]
gradient: [[-8.7450683 ]
[-7.60831565]]
...
gradient: [[0.08308938]
[0.00806808]]
gradient: [[0.03748728]
[0.01192033]]
Learned parameters:
[[2.04998588]
[2.90045065]]
我们也可以使用pytorch内置的optim.SGD 来完成上面的任务。
import torch
import torch.optim as optim
import numpy as np
# 生成一些伪数据
np.random.seed(0)
X = np.random.rand(100, 1)
y = 3 * X + 2
# 转换为 PyTorch 张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)
# 添加偏置项
X_b = torch.cat([torch.ones(100, 1), X_tensor], dim=1)
# 初始化参数
theta = torch.randn(2, 1, requires_grad=True)
print("Initial parameters:", theta)
# 定义学习率和迭代次数
learning_rate = 0.01
iterations = 10000
# 定义优化器
optimizer = optim.SGD([theta], lr=learning_rate)
# 损失函数(均方误差)
def mse_loss(y_pred, y_true):
return ((y_pred - y_true) ** 2).mean()
for i in range(iterations):
# 随机选择一个样本
idx = np.random.randint(0, 100)
xi = X_b[idx:idx + 1]
yi = y_tensor[idx:idx + 1]
# 前向传播
predictions = torch.matmul(xi, theta)
# 计算损失
loss = mse_loss(predictions, yi)
# 反向传播和优化
optimizer.zero_grad() # 清除梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数
# 打印损失(每100次迭代打印一次)
if (i + 1) % 100 == 0:
print(f"Iteration {i + 1}, Loss: {loss.item():.4f}")
print("Learned parameters:")
#print(theta.detach().numpy())
print(theta)
3.SGD+Momentum优化器
SGD+Momentum是随机梯度下降(Stochastic Gradient Descent,SGD)的一种变体,它引入了动量(Momentum)动量的概念来改进传统的随机梯度下降算法。动量的引入有助于解决SGD中的震荡和收敛速度较慢的问题。可以更好地应对梯度变化和梯度消失问题,从而提高训练模型的效率和稳定性。
动量主要解决SGD的两个问题:一是随机梯度的方法(引入的噪声);二是Hessian矩阵病态问题(可以理解为SGD在收敛过程中和正确梯度相比来回摆动比较大的问题)。
简单理解:由于当前权值的改变会受到上一次权值改变的影响,类似于小球向下滚动的时候带上了惯性。这样可以加快小球向下滚动的速度。
我们把上面的SGD训练一个简单的线性回归模型的例子改为SGD+Momentum优化器实现,代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
# 生成一些模拟的线性回归数据
np.random.seed(0)
X = np.random.rand(100, 1) # 100个样本,1个特征
y = 3 * X + 2
# 转换为张量
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)
# 创建数据集
dataset = TensorDataset(X_tensor, y_tensor)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 定义一个简单的线性回归模型
model = nn.Sequential(
nn.Linear(1, 1)
)
# 定义损失函数(均方误差)
criterion = nn.MSELoss()
# 定义优化器:SGD + Momentum
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 训练循环
num_epochs = 1000
for epoch in range(num_epochs):
for batch_X, batch_y in dataloader:
# 前向传播
outputs = model(batch_X)
loss = criterion(outputs, batch_y)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
# 打印梯度
for name, param in model.named_parameters():
if param.grad is not None:
print(f"Parameter {name} gradient:")
print(param.grad.detach().numpy())
optimizer.step()
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
print("Training finished!")
# 打印模型参数
for name, param in model.named_parameters():
print(f"Parameter {name}:")
print(param.data.numpy())
运行结果如下:
Parameter 0.weight gradient:
[[-5.57008]]
Parameter 0.bias gradient:
[-9.272552]
...
Training finished!
Parameter 0.weight:
[[2.9999945]]
Parameter 0.bias:
[2.0000029]
4.Adagrad优化器
Adagrad 是一种用于机器学习优化算法,特别适用于处理大规模稀疏数据集。它是由 John Duchi、Leon Bottou、Lorris Sculley 和 Joshua Goodman 在 2011 年提出的。Adagrad 算法通过自适应地调整每个参数的学习率来优化模型的训练过程,从而有助于解决传统梯度下降法在稀疏数据上可能遇到的问题。
Adagrad 的核心思想是,对于每个参数,它都会维护一个历史梯度平方的累加器。在每次迭代中,该累加器会加上当前梯度的平方。然后,在更新参数时,使用这个累加器来调整学习率,使得对于出现频率较高的特征(即梯度较大的特征),学习率会减小;而对于出现频率较低的特征(即梯度较小的特征),学习率会增大。
优点: 它可以让参数在训练的前期更新得快一些,在后期更新得慢一些,有助于稳定训练,从而更快地收敛到最优值,不同更新频率的参数具有不同的学习率,减少摆动,在稀疏数据场景下表现会非常好。
缺点: 但是由于分母中是历史梯度平方的累积和,随着训练的进行,分母会逐渐增大,导致学习率递减得很快,可能造成训练提前停止。
我们把上面的SGD训练一个简单的线性回归模型的例子改为Adagrad优化器实现,代码如下:
import numpy as np
# 生成一些伪数据
np.random.seed(0)
X = np.random.rand(100, 1)
y = 3 * X + 2
# 初始化参数
theta = np.random.randn(2, 1)
print("Initial parameters:", theta)
learning_rate = 0.1 # Adagrad 通常需要较大的初始学习率
epsilon = 1e-8 # 防止除零的微小值
iterations = 10000
# 添加偏置项
X_b = np.c_[np.ones((100, 1)), X]
# 初始化 Adagrad 的累加器
cache = np.zeros_like(theta)
for i in range(iterations):
# 随机选择一个样本
idx = np.random.randint(0, 100)
xi = X_b[idx:idx + 1]
yi = y[idx:idx + 1]
# 计算预测值
predictions = np.dot(xi, theta)
# 计算梯度
gradient = 2 * xi.T.dot(predictions - yi)
# 观察梯度下降的过程
print("gradient:", gradient)
# 更新 Adagrad 累加器
cache += gradient ** 2
# 更新参数
theta -= learning_rate * gradient / (np.sqrt(cache) + epsilon)
print("Learned parameters:")
print(theta)
运行结果:
Initial parameters: [[-1.16514984]
[ 0.90082649]]
gradient: [[-9.81047759]
[-8.13229758]]
gradient: [[-9.83115625]
[-9.09968517]]
...
Learned parameters:
[[1.9880821 ]
[3.02243292]]
5.RMSprop (Root Mean Square Propagation 均方根传播)
RMSprop 是对 AdaGrad 的改进,通过引入衰减因子来防止学习率过快减小。它通过对梯度平方的指数加权平均来调整每个参数的学习率, 其核心思想是调整每个参数的学习率,使其能够根据过去梯度的历史表现动态调整。
我们把上面的SGD训练一个简单的线性回归模型的例子改为RMSprop优化器实现,代码如下:
import numpy as np
# 生成一些伪数据
np.random.seed(0)
X = np.random.rand(100, 1)
y = 3 * X + 2
# 初始化参数
theta = np.random.randn(2, 1)
print("Initial parameters:", theta)
learning_rate = 0.01 # RMSprop 的学习率
decay_rate = 0.9 # RMSprop 的衰减率
epsilon = 1e-8 # 防止除零的微小值
iterations = 10000
# 添加偏置项
X_b = np.c_[np.ones((100, 1)), X]
# 初始化 RMSprop 的累加器
cache = np.zeros_like(theta)
for i in range(iterations):
# 随机选择一个样本
idx = np.random.randint(0, 100)
xi = X_b[idx:idx + 1]
yi = y[idx:idx + 1]
# 计算预测值
predictions = np.dot(xi, theta)
# 计算梯度
gradient = 2 * xi.T.dot(predictions - yi)
# 观察梯度下降的过程
print("gradient:", gradient)
# 更新 RMSprop 累加器
cache = decay_rate * cache + (1 - decay_rate) * (gradient ** 2)
# 更新参数
theta -= learning_rate * gradient / (np.sqrt(cache) + epsilon)
print("Learned parameters:")
print(theta)
运行结果:
Initial parameters: [[-1.16514984]
[ 0.90082649]]
gradient: [[-9.81047759]
[-8.13229758]]
gradient: [[-10.09449015]
[ -9.34342615]]
...
Learned parameters:
[[1.99977818]
[3.00098945]]
6.Adam优化器
PyTorch中的Adam优化器是一种自适应学习率的优化算法,结合了Adagrad和RMSProp的特点,通过动态调整学习率来提高训练的稳定性和收敛速度。Adam优化器的工作原理基于两个关键概念:一阶矩估计和二阶矩估计。
Adam优化器通过计算每个参数的“动量”和“加权平方梯度”的指数加权平均来动态调整学习率。动量类似于物理中的动量概念,帮助参数更新时保留历史的梯度信息,从而加速收敛;加权平方梯度计算梯度的平方的指数加权平均,用来规范化梯度的变化幅度,防止梯度爆炸或消失的问题。
优点: - 结合了动量和自适应学习率,通常可以快速收敛。 - 适用于非平稳目标函数和大规模数据集。 - 超参数调整较为简单,少量调整即可获得较好的性能。
缺点: - 对小数据集或过于简单的任务,可能导致过拟合。 - 对学习率较为敏感,可能需要根据具体问题进行微调。
我们把上面的SGD训练一个简单的线性回归模型的例子改为Adam优化器实现,代码如下:
import numpy as np
# 生成一些伪数据
np.random.seed(0)
X = np.random.rand(100, 1)
y = 3 * X + 2
# 初始化参数
theta = np.random.randn(2, 1)
print("Initial parameters:", theta)
# Adam 的超参数
learning_rate = 0.01 # 学习率
beta1 = 0.9 # 一阶矩估计的指数衰减率
beta2 = 0.999 # 二阶矩估计的指数衰减率
epsilon = 1e-8 # 防止除零的微小值
iterations = 10000
# 添加偏置项
X_b = np.c_[np.ones((100, 1)), X]
# 初始化 Adam 的参数
m = np.zeros_like(theta) # 一阶矩估计
v = np.zeros_like(theta) # 二阶矩估计
t = 0 # 迭代计数器
for i in range(iterations):
t += 1 # 更新迭代计数器
# 随机选择一个样本
idx = np.random.randint(0, 100)
xi = X_b[idx:idx + 1]
yi = y[idx:idx + 1]
# 计算预测值
predictions = np.dot(xi, theta)
# 计算梯度
gradient = 2 * xi.T.dot(predictions - yi)
# 观察梯度下降的过程
print("gradient:", gradient)
# 更新一阶矩估计
m = beta1 * m + (1 - beta1) * gradient
# 更新二阶矩估计
v = beta2 * v + (1 - beta2) * (gradient ** 2)
# 偏差修正
m_hat = m / (1 - beta1 ** t)
v_hat = v / (1 - beta2 ** t)
# 更新参数
theta -= learning_rate * m_hat / (np.sqrt(v_hat) + epsilon)
print("Learned parameters:")
print(theta)
运行结果:
Initial parameters: [[-1.16514984]
[ 0.90082649]]
gradient: [[-9.81047759]
[-8.13229758]]
...
gradient: [[0.]
[0.]]
Learned parameters:
[[2.]
[3.]]
小结:
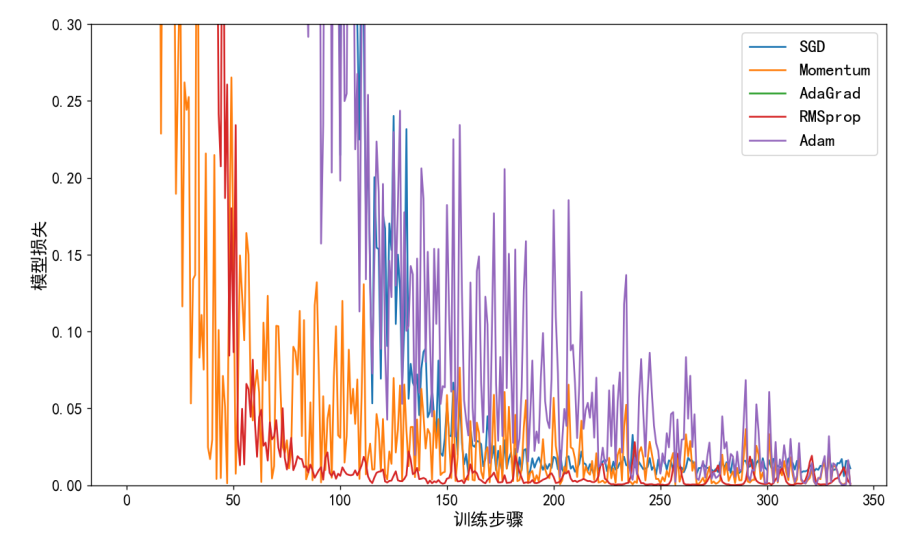
五种优化器对比示例可视化代码:
import torch
import torch.nn
import torch.utils.data as Data
import matplotlib
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
#准备建模数据
x = torch.unsqueeze(torch.linspace(-1, 1, 500), dim=1)
y = 3 * x + 2
#设置超参数
LR = 0.01
batch_size = 15
epoches = 10
torch.manual_seed(10)
#设置数据加载器
dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
dataset=dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2)
#搭建神经网络
class Net(torch.nn.Module):
def __init__(self, n_input, n_hidden, n_output):
super(Net, self).__init__()
self.hidden_layer = torch.nn.Linear(n_input, n_hidden)
self.output_layer = torch.nn.Linear(n_hidden, n_output)
def forward(self, input):
x = torch.relu(self.hidden_layer(input))
output = self.output_layer(x)
return output
#训练模型并输出折线图
def train():
net_SGD = Net(1, 10, 1)
net_Momentum = Net(1, 10, 1)
net_AdaGrad = Net(1, 10, 1)
net_RMSprop = Net(1, 10, 1)
net_Adam = Net(1, 10, 1)
nets = [net_SGD, net_Momentum, net_AdaGrad, net_RMSprop, net_Adam]
#定义优化器
optimizer_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
optimizer_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.6)
optimizer_AdaGrad = torch.optim.Adagrad(net_AdaGrad.parameters(), lr=LR, lr_decay=0)
optimizer_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
optimizer_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [optimizer_SGD, optimizer_Momentum, optimizer_AdaGrad, optimizer_RMSprop, optimizer_Adam]
#定义损失函数
loss_function = torch.nn.MSELoss()
losses = [[], [], [], [], []]
for epoch in range(epoches):
for step, (batch_x, batch_y) in enumerate(loader):
for net, optimizer, loss_list in zip(nets, optimizers, losses):
pred_y = net(batch_x)
loss = loss_function(pred_y, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_list.append(loss.data.numpy())
plt.figure(figsize=(12,7))
labels = ['SGD', 'Momentum', 'AdaGrad', 'RMSprop', 'Adam']
for i, loss in enumerate(losses):
plt.plot(loss, label=labels[i])
plt.legend(loc='upper right',fontsize=15)
plt.tick_params(labelsize=13)
plt.xlabel('训练步骤',size=15)
plt.ylabel('模型损失',size=15)
plt.ylim((0, 0.3))
plt.show()
if __name__ == "__main__":
train()
运行效果: