Softmax 函数通常用于多分类问题,尤其是当输出类别不止两个时。它将输入的实数值(通常是神经网络的未经过归一化的输出,称为 logits)转换为一个概率分布,使得每个类别的输出值(概率)都位于 0 和 1 之间,并且所有类别的概率之和等于 1。这样,Softmax 可以将模型的输出转化为可用于决策的概率。
1.Softmax函数
Softmax函数与交叉熵损失(Cross-Entropy Loss)的组合堪称经典组合。这对黄金搭档不仅具有数学上的优雅性,更能显著提升模型训练效率。
对于神经网络的原始输出值 z = [ z 1 , z 2 , . . . , z n ] Softmax函数通过指数归一化将其转化为概率分布:
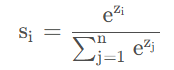
softmax函数的特点有:
- 函数值在[0-1]的范围之内。
- Softmax(xi)相加的总和为1。
- 指数运算放大差异:原始输出的微小差距会被指数函数显著放大。
下面是Softmax的代码演示:
import torch
import torch.nn.functional as F
# 创建一个输入张量
input_tensor = torch.tensor([2.0, 1.0, 0.1])
# 应用 Softmax 函数
softmax_output = F.softmax(input_tensor, dim=0)
print("输入张量:", input_tensor)
print("Softmax 输出:", softmax_output)
运行结果:
输入张量: tensor([2.0000, 1.0000, 0.1000])
Softmax 输出: tensor([0.6590, 0.2424, 0.0986])
以上结果的推导过程如下:

2.交叉熵(Cross-Entropy)的数学原理
交叉熵(Cross-Entropy)是衡量两个概率分布之间差异的度量,常用于机器学习和信息论,特别是在分类任务中衡量预测分布与真实分布的匹配程度。
对于两个概率分布p(x) 和q(x),交叉熵定义为:
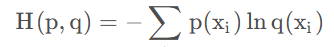
其中: - p(x) 表示真实分布(ground truth label),通常是独热编码(one-hot encoding)。 - q(x) 表示预测分布(模型输出的概率分布)。
3.softmax+交叉熵求导
在多分类问题中,通常与 Softmax 激活函数一起使用。Softmax 用于将模型的输出 logits 转换为概率分布,交叉熵损失函数(Cross-Entropy Loss)是机器学习中常用于分类任务,特别是 多分类 和 二分类 问题中的一种损失函数。它衡量的是模型预测的概率分布与实际标签的概率分布之间的差异,核心思想是:当模型预测的类别概率接近真实标签的概率时,交叉熵损失较小;反之,当两者差异较大时,交叉熵损失增大。
通过下面代码举例说明:
import torch
import torch.nn.functional as F
# 创建一个输入张量(假设是模型的输出)
logits = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
# 创建一个目标张量(假设是真实标签)
targets = torch.tensor([2, 2])
# 手动计算 Softmax
softmax_output = F.softmax(logits, dim=1)
# 手动计算交叉熵
log_softmax_output = torch.log(softmax_output)
loss = F.nll_loss(log_softmax_output, targets)
print("Softmax 输出:", softmax_output)
print("交叉熵损失(loss):", loss.item())
代码解释:
Softmax计算: F.softmax 将每个样本的得分转换为概率分布。 对于第一个样本,概率分布为 [0.0901, 0.2447, 0.6652],表示属于类别 0、1 和 2 的概率。 对于第二个样本,概率分布为 [0.0900, 0.2447, 0.6652],表示属于类别 0、1 和 2 的概率。
显然这两个样本都属于2个概率很大。 交叉熵计算: torch.log 计算 Softmax 输出的对数。 F.nll_loss(负对数似然损失)计算预测概率分布与真实标签之间的交叉熵损失。
运行结果:
Softmax 输出: tensor([[0.0900, 0.2447, 0.6652],
[0.0900, 0.2447, 0.6652]])
交叉熵损失(loss): 0.40760597586631775
由于真实标签是真实标签是[2,2],表示这两个样本都是2,和softmax 计算出来的每个样本的得分转换为概率分布基本吻合,所以得到的交叉熵损失也较小,表示模型预测比较准确。
如果我们调整真实标准为:[0,1],我们发现交叉熵损失会变大,说明模型预测的不准确。
import torch
import torch.nn.functional as F
# 创建一个输入张量(假设是模型的输出)
logits = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
# 创建一个目标张量(假设是真实标签)
targets = torch.tensor([0, 1])
# 手动计算 Softmax
softmax_output = F.softmax(logits, dim=1)
# 手动计算交叉熵
log_softmax_output = torch.log(softmax_output)
loss = F.nll_loss(log_softmax_output, targets)
print("Softmax 输出:", softmax_output)
print("交叉熵损失(loss):", loss.item())
运行结果:
Softmax 输出: tensor([[0.0900, 0.2447, 0.6652],
[0.0900, 0.2447, 0.6652]])
交叉熵损失(loss): 1.9076058864593506
小结:
Softmax 函数和交叉熵损失函数的组合在多分类任务中非常高效。Softmax 函数将神经网络的输出转化为概率分布,而交叉熵损失函数则衡量预测分布与真实分布之间的差异。这种组合不仅能够有效衡量模型的预测性能,还能在反向传播过程中提供简洁且稳定的梯度更新。