在深度学习领域,全连接层(Fully Connected Layer,FC)和链式求导法则是构建和训练神经网络的基石。全连接层负责将特征从一种形式转换为另一种形式,而链式求导法则则是反向传播算法的核心,用于计算神经网络参数的梯度。
1.全连接层的工作原理
全连接层是神经网络中的一种基本构建块,其主要作用是将输入特征映射到输出特征。在全连接层中,每个输入神经元都与每个输出神经元相连,因此得名“全连接”。
前向传播:下面这段代码中,我们定义了一个ReLU激活函数,并在全连接层的前向传播中使用它。fully_connected_forward 函数接受输入向量 x,权重矩阵 W 和偏置向量 b,计算线性组合输出 z 和激活后的输出 a。
import numpy as np
def activation_function(z):
# 以ReLU激活函数为例
return np.maximum(0, z)
def fully_connected_forward(x, W, b):
# 计算线性组合
z = np.dot(W, x) + b
# 应用激活函数
a = activation_function(z)
return a, z # 返回激活后的输出和线性组合输出
# 示例输入
x = np.array([1.0, 2.0])
W = np.array([[1.0, 2.0], [3.0, 4.0]])
b = np.array([1.0, 2.0])
# 执行前向传播
output, pre_activation = fully_connected_forward(x, W, b)
print("Output of fully connected layer:", output)
print("Pre-activation output:", pre_activation)
输出结果:
Output of fully connected layer: [ 6. 13.]
Pre-activation output: [ 6. 13.]
代码解析:
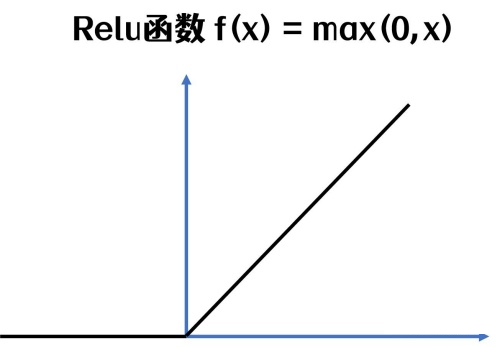
激活函数 activation_function: - 使用了 ReLU 激活函数,公式为 ReLU(z)=max(0,z)。 - ReLU 的作用是引入非线性,将负值输出为 0,正值保持不变。
全连接层前向传播 fully_connected_forward: - 计算线性组合 z=W⋅x+b,其中 W 是权重矩阵,x 是输入向量,b 是偏置向量。 - 将线性组合的结果 z 通过激活函数,得到激活后的输出 a。 - 返回激活后的输出 a 和线性组合输出 z。
示例输入: - 输入向量 x=[1.0,2.0] - 权重矩阵 W=[ 1.0 3.0 2.0 4.0 ] - 偏置向量 b=[1.0,2.0]

ReLU 激活函数的作用是引入非线性,将负值输出为 0,正值保持不变。我尝试修改输入向量为:x=[1.0,-2.0],这样经过全连接层前向传播计算线性组合结果是负数。但是经过激活层后,将负值全部输出为 0。
修改代码如下:
import numpy as np
def activation_function(z):
# 以ReLU激活函数为例
return np.maximum(0, z)
def fully_connected_forward(x, W, b):
# 计算线性组合
z = np.dot(W, x) + b
# 应用激活函数
a = activation_function(z)
return a, z # 返回激活后的输出和线性组合输出
# 示例输入
x = np.array([1.0, -2.0])
W = np.array([[1.0, 2.0], [3.0, 4.0]])
b = np.array([1.0, 2.0])
# 执行前向传播
output, pre_activation = fully_connected_forward(x, W, b)
print("Output of fully connected layer:", output)
print("Pre-activation output:", pre_activation)
输出结果:
Output of fully connected layer: [0. 0.]
Pre-activation output: [-2. -3.]
2.反向传播
在训练神经网络时,我们需要计算损失函数L 关于网络参数权重 (W) 和偏置 (b)的梯度。这一过程依赖于链式求导法则。链式求导法则是微积分中的一个基本法则,它允许我们计算复合函数的导数。在神经网络的背景下,链式求导法则被用来计算损失函数关于网络参数的梯度,这是反向传播算法的核心。
链式求导法则:
复合函数f(g(x))求导可以使用链式法则(Chain Rule)。如果y=f(u) 和u=g(x),那么复合函数y=f(g(x))的导数可以通过链式法则计算如下:
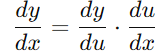
import numpy as np
def activation_function(z):
# ReLU 激活函数
return np.maximum(0, z)
def activation_function_derivative(z):
# ReLU 的导数
return (z > 0).astype(float)
def fully_connected_forward(x, W, b):
# 前向传播
z = np.dot(W, x) + b # 线性组合
a = activation_function(z) # 应用激活函数
return a, z # 返回激活后的输出和线性组合输出
def fully_connected_backward(d_a, x, W, b, z):
# 反向传播
# d_a 是损失函数对激活输出 a 的梯度
# 计算损失函数对线性组合 z 的梯度
d_z = d_a * activation_function_derivative(z)
# 计算损失函数对权重 W 的梯度
d_W = np.outer(d_z, x)
# 计算损失函数对偏置 b 的梯度
d_b = d_z
# 计算损失函数对输入 x 的梯度
d_x = np.dot(W.T, d_z)
return d_W, d_b, d_x
# 示例输入
x = np.array([1.0, 2.0])
W = np.array([[1.0, 2.0], [3.0, 4.0]])
b = np.array([1.0, 2.0])
# 前向传播
output, pre_activation = fully_connected_forward(x, W, b)
print("Output of fully connected layer:", output)
print("Pre-activation output:", pre_activation)
# 假设损失函数对输出 a 的梯度为 d_a
d_a = np.array([1.0, 1.0]) # 这里假设损失函数对输出 a 的梯度为 [1.0, 1.0]
# 反向传播
d_W, d_b, d_x = fully_connected_backward(d_a, x, W, b, pre_activation)
print("Gradient of W:", d_W)
print("Gradient of b:", d_b)
print("Gradient of x:", d_x)
运行结果:
Output of fully connected layer: [ 6. 13.]
Pre-activation output: [ 6. 13.]
Gradient of W: [[1. 2.]
[1. 2.]]
Gradient of b: [1. 1.]
Gradient of x: [4. 6.]
下来我们详细解释一下d_w,d_b,d_x的推导过程,这些梯度是通过链式法则计算的,用于更新权重和偏置,以最小化损失函数。
计算 d_z(损失函数对线性组合 z 的梯度)
在反向传播中,我们需要计算损失函数对权重矩阵 W 的梯度 dW 。根据链式法则,我们有:
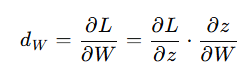

计算 d_W(损失函数对权重矩阵 W 的梯度)

这里为什么是x的转置矩阵呢?



计算 d_b(损失函数对偏置向量 b 的梯度)

计算 d_x(损失函数对输入向量 x 的梯度)

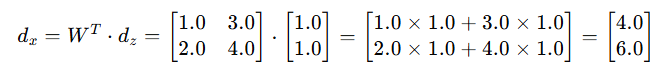

小结:
全连接层和链式求导法则是深度学习中不可或缺的部分。全连接层负责特征的线性变换和非线性激活,而链式求导法则则使得我们能够通过反向传播算法有效地训练神经网络。理解这两个概念对于构建和优化深度学习模型至关重要。通过上述代码示例,我们可以看到如何将这些理论应用于实际的神经网络训练过程中。这些代码示例不仅展示了全连接层的前向传播和反向传播的数学原理,还提供了如何在Python中实现这些过程的具体方法。
这些原理和代码的实现不仅适用于全连接层,而且是构建更复杂神经网络结构的基础。例如,在卷积神经网络(CNN)中,全连接层通常用于网络的末端,以将学习到的特征映射到最终的输出类别。在循环神经网络(RNN)中,链式求导法则被用来处理序列数据中的依赖关系,从而计算时间步上的梯度。掌握这些基础知识,可以帮助我们更好地理解和改进深度学习模型,以解决更复杂的实际问题。