所谓多通道卷积 就是分别对每个通道进行卷积,然后把结果加起来。
1.多通道卷积
在图像处理中,通道是指图像的不同分量。 比如: - 灰度图像:只有一个通道(亮度)。 - 彩色图像:有三个通道(红、绿、蓝,简称 RGB)。
多通道卷积 的核心思想是:对每个通道分别进行卷积,然后把结果加起来。
以彩色图像为例,包含三个通道,分别表示RGB三原色的像素值,输入为(3,5,5),分别表示3个通道,每个通道的宽为5,高为5。假设卷积核只有1个,卷积核通道为3,每个通道的卷积核大小仍为3x3,padding=0,stride=1。
卷积过程如下,每一个通道的像素值与对应的卷积核通道的数值进行卷积,因此每一个通道会对应一个输出卷积结果,三个卷积结果对应位置累加求和,得到最终的卷积结果(这里卷积输出结果通道只有1个,因为卷积核只有1个。卷积多输出通道下面会继续讲到)。
可以这么理解:最终得到的卷积结果是原始图像各个通道上的综合信息结果。
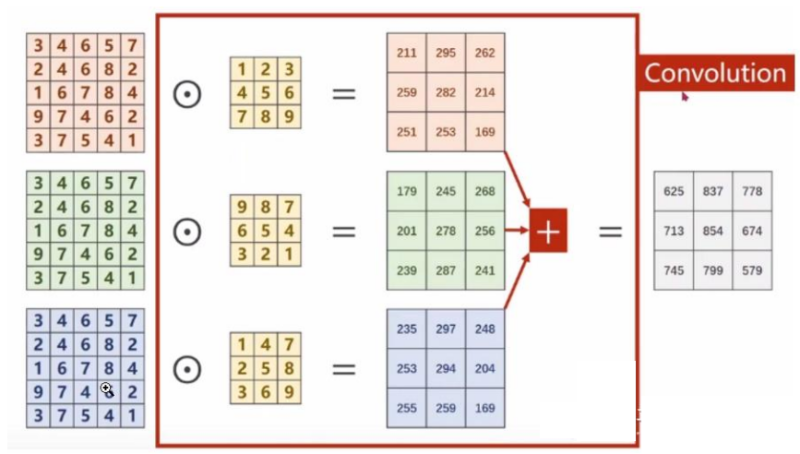
上述过程中,每一个卷积核的通道数量,必须要求与输入通道数量一致,因为要对每一个通道的像素值要进行卷积运算,所以每一个卷积核的通道数量必须要与输入通道数量保持一致。
我们把上述图像通道如果放在一块,计算原理过程还是与上面一样,堆叠后的表示如下:
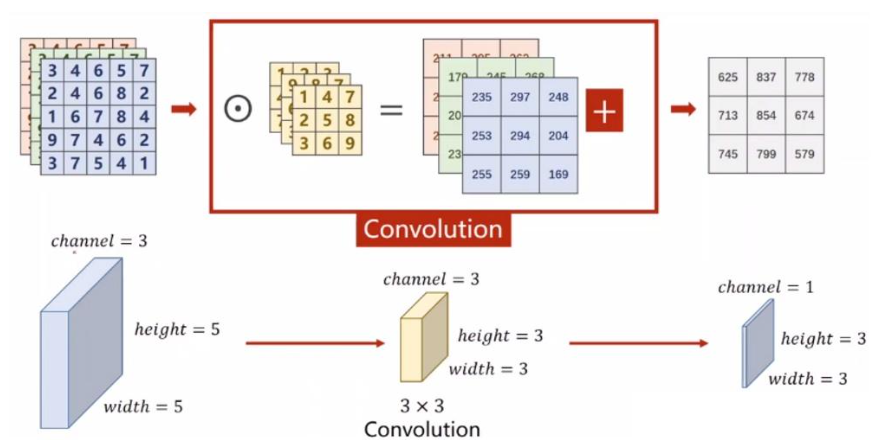
2.单卷积核多通道
我们来看下面的单卷积核多通道卷积的演变过程。

代码实现如下:
import torch
import torch.nn as nn
import numpy as np
# 创建一个大小为 28*28 的单通道图像
# input_data = torch.randn(1, 3, 3, 3) # 一个大小为28x28的单通道图像
# 创建一个 NumPy 数组
matrix_np = np.array([[[[0.0, 1.0, 1.0],
[0.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[0.0, 0.0, 1.0],
[1.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[1.0, 0.0, 1.0],
[1.0, 1.0, 1.0],
[1.0, 0.0, 0.0]]
]])
kernel = torch.tensor([
[
[1., 0.],
[0., 0.]
]
,
[
[0., 1.],
[0., 0.]
]
,
[
[0., 0.],
[1., 0.]
]
], dtype=torch.float32)
matrix_np = np.array(matrix_np).astype(np.float32)
# 转换为 PyTorch 张量
input_data = torch.from_numpy(matrix_np)
print(input_data)
# 创建卷积层,输入通道数为 3
# 输出通道数1
# 步长默认是1
# 卷积核大小2*2
# 0个0填充
# 默认没有偏置项 bias=False
#conv_layer = nn.Conv2d(in_channels=3, out_channels=1, stride=1, kernel_size=2, padding=0,bias=True)
conv_layer = nn.Conv2d(in_channels=3, out_channels=1, stride=1, kernel_size=2, padding=0,bias=False)
# 手动设置卷积核权重(权重形状:[out_channels, in_channels, height, width])
conv_layer.weight.data = kernel.view(1, 3, 2, 2)
# 手动设置卷积核偏置项(偏置项形状:[out_channels])
#conv_layer.bias.data.fill_(-1.0)
# 对输入数据进行卷积操作
output_data = conv_layer(input_data)
# 输出结果
print(output_data.shape)
print(torch.round(output_data))
输出结果:
tensor([[[[0., 1., 1.],
[0., 0., 1.],
[0., 0., 0.]],
[[0., 0., 1.],
[1., 0., 1.],
[0., 0., 0.]],
[[1., 0., 1.],
[1., 1., 1.],
[1., 0., 0.]]]])
torch.Size([1, 1, 2, 2])
tensor([[[[1., 3.],
[1., 1.]]]], grad_fn=<RoundBackward0>)
上面是没有设置偏置项的情况,通常偏置项针对每一个通道都是一个固定的值。比如:我们设置偏置项为-1,则代码修改如下:
import torch
import torch.nn as nn
import numpy as np
# 创建一个大小为 28*28 的单通道图像
# input_data = torch.randn(1, 3, 3, 3) # 一个大小为28x28的单通道图像
# 创建一个 NumPy 数组
matrix_np = np.array([[[[0.0, 1.0, 1.0],
[0.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[0.0, 0.0, 1.0],
[1.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[1.0, 0.0, 1.0],
[1.0, 1.0, 1.0],
[1.0, 0.0, 0.0]]
]])
kernel = torch.tensor([
[
[1., 0.],
[0., 0.]
]
,
[
[0., 1.],
[0., 0.]
]
,
[
[0., 0.],
[1., 0.]
]
], dtype=torch.float32)
matrix_np = np.array(matrix_np).astype(np.float32)
# 转换为 PyTorch 张量
input_data = torch.from_numpy(matrix_np)
print(input_data)
# 创建卷积层,输入通道数为 3
# 输出通道数1
# 步长默认是1
# 卷积核大小2*2
# 0个0填充
# 默认没有偏置项 bias=False
#conv_layer = nn.Conv2d(in_channels=3, out_channels=1, stride=1, kernel_size=2, padding=0,bias=True)
conv_layer = nn.Conv2d(in_channels=3, out_channels=1, stride=1, kernel_size=2, padding=0,bias=True)
# 手动设置卷积核权重(权重形状:[out_channels, in_channels, height, width])
conv_layer.weight.data = kernel.view(1, 3, 2, 2)
# 手动设置卷积核偏置项(偏置项形状:[out_channels])
conv_layer.bias.data.fill_(-1.0)
# 对输入数据进行卷积操作
output_data = conv_layer(input_data)
# 输出结果
print(output_data.shape)
print(torch.round(output_data))
运行结果如下:
tensor([[[[0., 1., 1.],
[0., 0., 1.],
[0., 0., 0.]],
[[0., 0., 1.],
[1., 0., 1.],
[0., 0., 0.]],
[[1., 0., 1.],
[1., 1., 1.],
[1., 0., 0.]]]])
torch.Size([1, 1, 2, 2])
tensor([[[[0., 2.],
[0., 0.]]]], grad_fn=<RoundBackward0>)
3.多卷积核多通道
我们来看下面的多卷积核多通道卷积的演变过程。
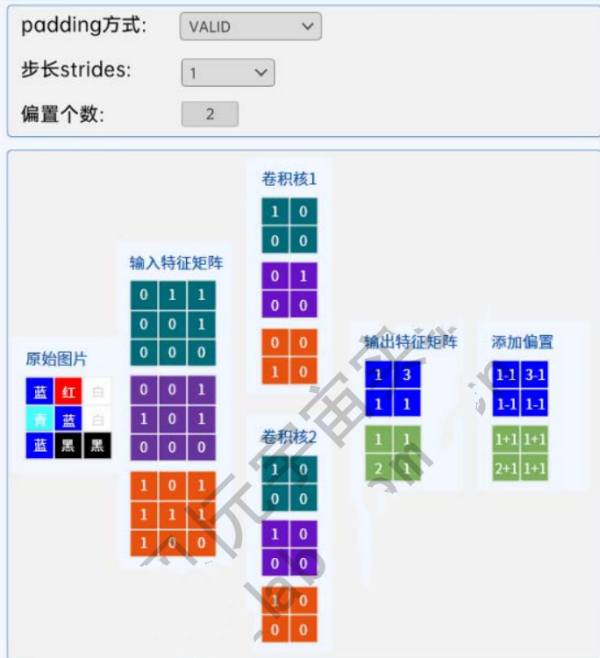
代码实现:
import torch
import torch.nn as nn
import numpy as np
# 创建一个大小为 28*28 的单通道图像
# input_data = torch.randn(1, 3, 3, 3) # 一个大小为28x28的单通道图像
# 创建一个 NumPy 数组
matrix_np = np.array([[[[0.0, 1.0, 1.0],
[0.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[0.0, 0.0, 1.0],
[1.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[1.0, 0.0, 1.0],
[1.0, 1.0, 1.0],
[1.0, 0.0, 0.0]]
]])
kernel = torch.tensor([
[
[
[1., 0.],
[0., 0.]
]
,
[
[0., 1.],
[0., 0.]
]
,
[
[0., 0.],
[1., 0.]
]
],
[
[
[1., 0.],
[0., 0.]
]
,
[
[1., 0.],
[0., 0.]
]
,
[
[1., 0.],
[0., 0.]
]
]
], dtype=torch.float32)
matrix_np = np.array(matrix_np).astype(np.float32)
# 转换为 PyTorch 张量
input_data = torch.from_numpy(matrix_np)
print(input_data)
# 创建卷积层,输入通道数为 3
# 输出通道数1
# 步长默认是1
# 卷积核大小2*2
# 0个0填充
# 默认没有偏置项 bias=False
conv_layer = nn.Conv2d(in_channels=3, out_channels=2, stride=1, kernel_size=2, padding=0, bias=True)
# conv_layer = nn.Conv2d(in_channels=3, out_channels=2, stride=1, kernel_size=2, padding=0, bias=True)
# 手动设置卷积核权重(权重形状:[out_channels, in_channels, height, width])
conv_layer.weight.data = kernel.view(2, 3, 2, 2)
# 手动设置卷积核偏置项(偏置项形状:[out_channels])
# conv_layer.bias.data.fill_(-1.0)
# 对输入数据进行卷积操作
output_data = conv_layer(input_data)
# 输出结果
print(output_data.shape)
print(torch.round(output_data))
输出结果:
tensor([[[[0., 1., 1.],
[0., 0., 1.],
[0., 0., 0.]],
[[0., 0., 1.],
[1., 0., 1.],
[0., 0., 0.]],
[[1., 0., 1.],
[1., 1., 1.],
[1., 0., 0.]]]])
torch.Size([1, 2, 2, 2])
tensor([[[[1., 3.],
[1., 1.]],
[[1., 1.],
[2., 1.]]]], grad_fn=<RoundBackward0>)
上面是没有设置偏置项的情况,每个卷积核对应一个偏置项。比如:我们设置第一个卷积核的偏置项为-1,第二个卷积核的偏置项为1,则代码修改如下:
import torch
import torch.nn as nn
import numpy as np
# 创建一个大小为 28*28 的单通道图像
# input_data = torch.randn(1, 3, 3, 3) # 一个大小为28x28的单通道图像
# 创建一个 NumPy 数组
matrix_np = np.array([[[[0.0, 1.0, 1.0],
[0.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[0.0, 0.0, 1.0],
[1.0, 0.0, 1.0],
[0.0, 0.0, 0.0]]
,
[[1.0, 0.0, 1.0],
[1.0, 1.0, 1.0],
[1.0, 0.0, 0.0]]
]])
kernel = torch.tensor([
[
[
[1., 0.],
[0., 0.]
]
,
[
[0., 1.],
[0., 0.]
]
,
[
[0., 0.],
[1., 0.]
]
],
[
[
[1., 0.],
[0., 0.]
]
,
[
[1., 0.],
[0., 0.]
]
,
[
[1., 0.],
[0., 0.]
]
]
], dtype=torch.float32)
matrix_np = np.array(matrix_np).astype(np.float32)
# 转换为 PyTorch 张量
input_data = torch.from_numpy(matrix_np)
print(input_data)
# 创建卷积层,输入通道数为 3
# 输出通道数1
# 步长默认是1
# 卷积核大小2*2
# 0个0填充
# 默认没有偏置项 bias=False
#conv_layer = nn.Conv2d(in_channels=3, out_channels=2, stride=1, kernel_size=2, padding=0, bias=True)
conv_layer = nn.Conv2d(in_channels=3, out_channels=2, stride=1, kernel_size=2, padding=0, bias=True)
# 手动设置卷积核权重(权重形状:[out_channels, in_channels, height, width])
conv_layer.weight.data = kernel.view(2, 3, 2, 2)
# 手动设置卷积核偏置项(偏置项形状:[out_channels])
# 第一个卷积核偏置项设置为-1.0
conv_layer.bias.data[0].fill_(-1.0)
# 第二个卷积核偏置项设置为1.0
conv_layer.bias.data[1].fill_(1.0)
# 对输入数据进行卷积操作
output_data = conv_layer(input_data)
# 输出结果
print(output_data.shape)
print(torch.round(output_data))
输出结果:
tensor([[[[0., 1., 1.],
[0., 0., 1.],
[0., 0., 0.]],
[[0., 0., 1.],
[1., 0., 1.],
[0., 0., 0.]],
[[1., 0., 1.],
[1., 1., 1.],
[1., 0., 0.]]]])
torch.Size([1, 2, 2, 2])
tensor([[[[0., 2.],
[0., 0.]],
[[2., 2.],
[3., 2.]]]], grad_fn=<RoundBackward0>)
由此我们得到两个结论: 1. 输入特征的通道数决定了卷积核的通道数(卷积核通道个数=输入特征通道个数)。 2. 卷积核的个数决定了输出特征矩阵的通道数与偏置矩阵的通道数(卷积核个数=输出特征通道数=偏置矩阵通道数)。