神经网络是一种模仿人脑神经系统的计算模型,它的设计灵感来源于人类大脑中的神经元网络。
1.神经元网络
人类的大脑更是包含800多亿个神经元,由这些神经元组成的神经网络非常复杂。下图为两个神经元的简单示意图。
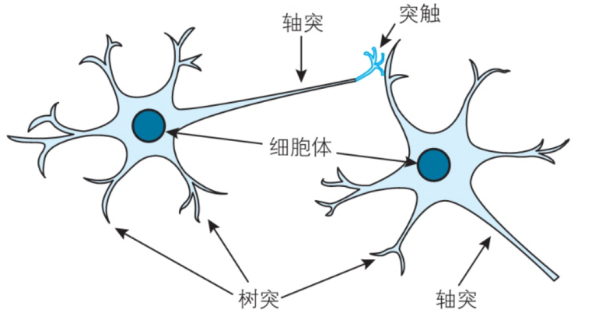
在人脑中存在大量的神经元,每个神经元可以接收来自其他神经元的信号,经过处理之后再将信号传递给下一个神经元。神经网络尝试模仿这个过程。它的基本单元被称为神经元或节点,这些神经元相互连接形成网络。每个神经元会接收来自其他神经元的输入信号,对这些信号进行加权处理,然后通过激活函数来决定输出。激活函数的作用在于帮助神经网络进行非线性计算,使得网络可以处理复杂的模式和关系。
2.人工神经元
人工神经元则是模仿生物神经元的结构,建立起来的数学模型。如下图所示:
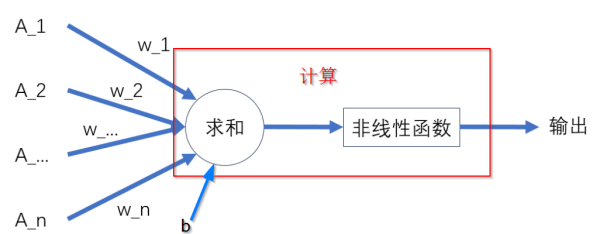
该人工神经元包含多个输入A_1, A_2...A_n(模仿多个树突),一个计算功能(模仿细胞核),以及一个输出(模仿一个轴突)。其中,w_n表示每个输入的权值,可以类比为输入信号的强弱。
用F()表示非线性函数,Y表示输出,则上述神经元模型可用数学公式表示为:
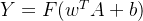
其中,b表示一个偏置项,它的作用是使得神经元在输入信号为0时仍然能被激活,从而改善模型的表达能力。如果没有偏置项,神经元只能通过权重来调整输入信号的影响,可能导致模型对输入数据的拟合能力受限。 总结起来,偏置项在神经网络中的作用是提供一个可调节的阈值,使得模型能够更好地适应输入数据。 没有偏置项可能会限制模型的表达能力。
3.人工神经网络(Artificial Neural Network,ANN)
人工神经网络(Artificial Neural Network,ANN)的结构通常由以下几个部分组成: - 输入层:这是神经网络的第一层,它的作用是接收输入数据。输入层的每个神经元对应输入数据的一个特征。 - 隐藏层:位于输入层和输出层之间的层称为隐藏层。它可以有一层或多层。隐藏层并不直接接触外部数据,它的作用是对输入数据进行非线性变换,提取数据的特征。 - 输出层:这是神经网络的最后一层,它的作用是产生网络的最终输出结果。输出层的神经元数目取决于任务的类型,例如在分类任务中,输出层的神经元数目可能对应分类的类别数目。
前馈神经网络就是是人工神经网络(Artificial Neural Network,ANN)的最常见的一种类型。前馈神经网络(Feedforward Neural Networks)是最基础的神经网络模型,也被称为多层感知机(MLP)。
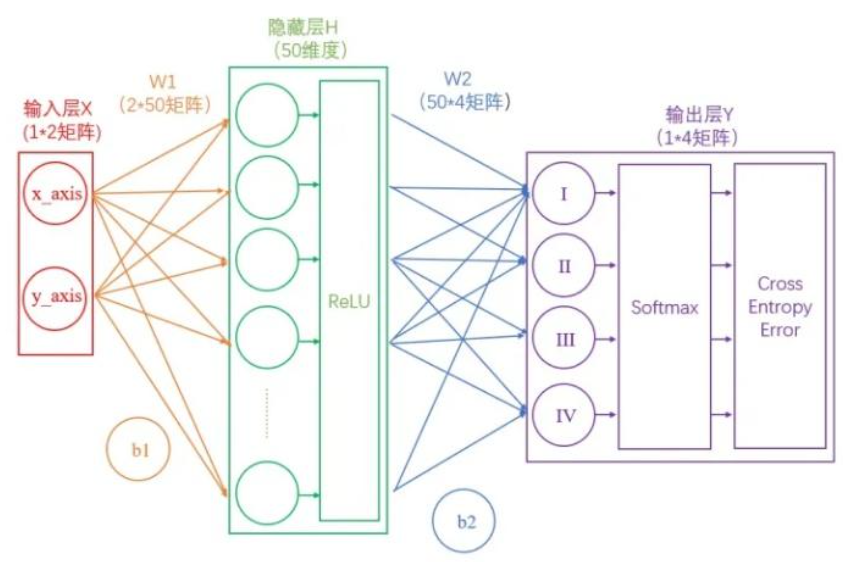
3.1 从输入层到隐藏层
连接输入层和隐藏层的是W1和b1。由X计算得到H十分简单,就是矩阵运算,就是输入数据与权值矩阵相乘,加上偏置:
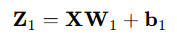
3.2 从隐藏层到输出层
隐藏层的输出与权值矩阵相乘,加上偏置:
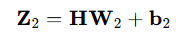
通过上述两个线性方程的计算,我们就能得到最终的输出Y了,但是如果你还对线性代数的计算有印象的话,应该会知道:一系列线性方程的运算最终都可以用一个线性方程表示。也就是说,上述两个式子联立后可以用一个线性方程表达。对于两次神经网络是这样,就算网络深度加到100层,也依然是这样。
3.3 激活层
简而言之,激活层是为矩阵运算的结果添加非线性的。常用的激活函数有三种,分别是阶跃函数、Sigmoid和ReLU。不要被奇怪的函数名吓到,其实它们的形式都很简单,如下图:
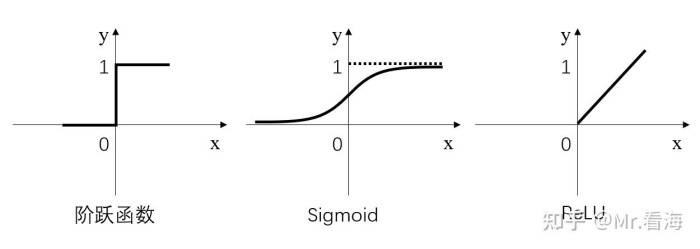
- 阶跃函数:当输入小于等于0时,输出0;当输入大于0时,输出1。
- Sigmoid:当输入趋近于正无穷/负无穷时,输出无限接近于1/0。
- ReLU:当输入小于0时,输出0;当输入大于0时,输出等于输入。
假如经过公式H=X*W1+b1计算得到的H值为:(1,-2,3,-4,7...),那么经过阶跃函数激活层后就会变为(1,0,1,0,1...),经过ReLU激活层之后会变为(1,0,3,0,7...)。
4.Pytorch实现一个最简单的神经网络
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的前馈神经网络
class SimpleFeedForwardNN(nn.Module):
def __init__(self):
super(SimpleFeedForwardNN, self).__init__()
# 定义输入层 -> 隐藏层
self.fc1 = nn.Linear(in_features=1, out_features=2) # 输入层有一个神经元,隐藏层有两个神经元
self.relu = nn.ReLU() # 添加激活函数,这里使用 ReLU
# 定义隐藏层 -> 输出层
self.fc2 = nn.Linear(in_features=2, out_features=1) # 隐藏层有两个神经元,输出层有一个神经元
def forward(self, x):
# 前向传播过程
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 初始化网络
model = SimpleFeedForwardNN()
# 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失函数,适用于回归问题
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 优化器,学习率为 0.01
# 创建一些简单的训练数据
# 输入数据
inputs = torch.tensor([[1.0], [2.0], [3.0], [4.0], [5.0], [6.0], [7.0], [8.0], [9.0], [10.0]], dtype=torch.float32)
# 期望的输出数据
# 其实就是y=2*x
labels = torch.tensor([[2.0], [4.0], [6.0], [8.0], [10.0], [12.0], [14.0], [16.0], [18.0], [20.0]], dtype=torch.float32)
# 训练模型
num_epochs = 500 # 训练周期数
for epoch in range(num_epochs):
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels) # 计算损失
# 反向传播和优化
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新权重
# 打印每个周期的损失
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 输出模型的参数
for name, param in model.named_parameters():
print(f'Parameter name: {name}, Parameter value: {param}')
# 测试模型
# 输入测试数据
test_input = torch.tensor([[5.0]], dtype=torch.float32)
# 输出预测结果
test_output = model(test_input)
print('\nTest Input:', test_input.item())
print('Predicted Output:', test_output.item())
运行结果:
Epoch [1/500], Loss: 142.5251
...
Epoch [500/500], Loss: 0.8474
Parameter name: fc1.weight, Parameter value: Parameter containing:
tensor([[ 0.9054],
[-0.2367]], requires_grad=True)
Parameter name: fc1.bias, Parameter value: Parameter containing:
tensor([0.6325, 0.0069], requires_grad=True)
Parameter name: fc2.weight, Parameter value: Parameter containing:
tensor([[1.8864, 0.5295]], requires_grad=True)
Parameter name: fc2.bias, Parameter value: Parameter containing:
tensor([0.7847], requires_grad=True)
Test Input: 5.0
Predicted Output: 10.517326354980469
下来我们简单推导一下,从模型参数是如何推导出预测结果的:
输入层: 每次输入一个正整数:x
隐藏层: 隐藏层有 1 个神经元 权值矩阵:[[ 0.9054], [-0.2367]] 偏置向量:[0.6325, 0.0069] 激活函数:ReLU
输出层:
输出层有 1 个神经元 权值矩阵:[[1.8864, 0.5295]] 偏置:[0.7847] 激活函数:线性(恒等函数)
完整的推导过程如下图:

另外一个PyTorch 搭建的简单全连接神经网络示例,用于解决回归任务,推导过程大家可以自行验证。
import torch
import torch.nn as nn
import torch.optim as optim
# 生成示例数据(回归任务)
torch.manual_seed(0) # 设置随机种子保证可重复性
X = torch.randn(100, 1) # 100个样本,1个特征
#y = 3 * X + 2 + torch.randn(100, 1) * 0.1 # 线性关系 + 噪声
#线性关系 ,不添加噪声
y = 3 * X + 2
# 定义神经网络结构
class SimpleNN(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(1, 10) # 输入层到隐藏层
self.relu = nn.ReLU() # 激活函数
self.output = nn.Linear(10, 1) # 隐藏层到输出层
def forward(self, x):
x = self.hidden(x)
x = self.relu(x)
x = self.output(x)
return x
# 实例化模型、损失函数和优化器
model = SimpleNN()
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降
# 训练循环
epochs = 500
for epoch in range(epochs):
# 前向传播
predictions = model(X)
loss = criterion(predictions, y)
# 反向传播和优化
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数
# 每50个epoch打印进度
if (epoch + 1) % 50 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')
# 输出模型的参数
for name, param in model.named_parameters():
print(f'Parameter name: {name}, Parameter value: {param}')
# 测试预测
test_inputs = torch.tensor([[0.5], [1.0], [2.0],[3.0]], dtype=torch.float32)
with torch.no_grad(): # 禁用梯度计算
predictions = model(test_inputs)
print("\nTest predictions:")
for x, pred in zip(test_inputs, predictions):
print(f"Input: {x.item():.2f} -> Predicted: {pred.item():.2f}")
运行结果:
Epoch [50/500], Loss: 0.3070
Epoch [100/500], Loss: 0.1312
Epoch [150/500], Loss: 0.1038
Epoch [200/500], Loss: 0.0849
Epoch [250/500], Loss: 0.0687
Epoch [300/500], Loss: 0.0546
Epoch [350/500], Loss: 0.0429
Epoch [400/500], Loss: 0.0337
Epoch [450/500], Loss: 0.0266
Epoch [500/500], Loss: 0.0206
Parameter name: hidden.weight, Parameter value: Parameter containing:
tensor([[-0.3033],
[ 0.0451],
[ 0.2211],
[ 0.2372],
[ 1.2149],
[ 0.5667],
[-0.3110],
[ 0.9040],
[-1.4867],
[-0.9160]], requires_grad=True)
Parameter name: hidden.bias, Parameter value: Parameter containing:
tensor([-0.2262, -0.4871, -0.3226, -0.8196, 0.0968, 0.9987, -0.7318, -0.0110,
0.4810, -0.2350], requires_grad=True)
Parameter name: output.weight, Parameter value: Parameter containing:
tensor([[-0.1368, -0.0273, 0.1157, 0.2011, 1.1709, 1.1440, 0.2443, 0.7736,
-1.0461, -0.7459]], requires_grad=True)
Parameter name: output.bias, Parameter value: Parameter containing:
tensor([1.0468], requires_grad=True)
Test predictions:
Input: 0.50 -> Predicted: 3.68
Input: 1.00 -> Predicted: 5.06
Input: 2.00 -> Predicted: 7.85
Input: 3.00 -> Predicted: 10.64
代码说明:
- 数据生成:创建带有噪声的线性数据(y = 3x + 2 + noise)
- 网络结构: -- 输入层(1个神经元) -- 隐藏层(10个神经元 + ReLU激活) -- 输出层(1个神经元)
- 训练配置: -- 损失函数:均方误差(MSE) -- 优化器:随机梯度下降(SGD)
- 学习率:0.01 -- 训练轮次:500
- 预测测试:使用训练好的模型对三个新样本进行预测
我们也以使用pytorch代码进行结果验证,比如我们验证输入是3.0时,预测结果是:10.64, 其验证代码如下:
import torch
import numpy as np
import pandas as pd
if __name__ == '__main__':
t1 = torch.tensor([-0.3033,
0.0451,
0.2211,
0.2372,
1.2149,
0.5667,
-0.3110,
0.9040,
-1.4867,
-0.9160])
bias1 = torch.tensor([-0.2262, -0.4871, -0.3226, -0.8196, 0.0968, 0.9987, -0.7318, -0.0110,
0.4810, -0.2350])
output1 = 3.0 * t1 + bias1
print(output1)
relu = torch.nn.ReLU()
output2 = relu(output1)
print(output2)
t2 = torch.tensor([-0.1368, -0.0273, 0.1157, 0.2011, 1.1709, 1.1440, 0.2443, 0.7736,
-1.0461, -0.7459])
bias2 = 1.0468
result = output2 @ t2 + bias2
print(result)
输出结果:
tensor([-1.1361, -0.3518, 0.3407, -0.1080, 3.7415, 2.6988, -1.6648, 2.7010,
-3.9791, -2.9830])
tensor([0.0000, 0.0000, 0.3407, 0.0000, 3.7415, 2.6988, 0.0000, 2.7010, 0.0000,
0.0000])
tensor(10.6441)
增加模型保存与预测功能:
我们只需要在模型训练完成后增加模型保存代码如下:
#torch保存模型
torch.save(model.state_dict(),'./best.pt')
模型预测时,我们只需要加载模型文件后去预测样本。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义神经网络结构
class SimpleNN(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(1, 10) # 输入层到隐藏层
self.relu = nn.ReLU() # 激活函数
self.output = nn.Linear(10, 1) # 隐藏层到输出层
def forward(self, x):
x = self.hidden(x)
x = self.relu(x)
x = self.output(x)
return x
if __name__ == '__main__':
model = SimpleNN()
#加载模型
model.load_state_dict(torch.load("./best.pt"))
model = model.eval()
# 测试预测
test_inputs = torch.tensor([[0.5], [1.0], [2.0], [3.0]], dtype=torch.float32)
with torch.no_grad(): # 禁用梯度计算
predictions = model(test_inputs)
print("\nTest predictions:")
for x, pred in zip(test_inputs, predictions):
print(f"Input: {x.item():.2f} -> Predicted: {pred.item():.2f}")