机器学习之朴素贝叶斯新闻分类案例
机器学习之朴素贝叶斯新闻分类案例
1.数据集简介
在机器学习领域,新闻组数据集是一个经典的数据集,用于文本分类任务。这里,我们将使用Python的scikit-learn库中的新闻组数据集,并利用朴素贝叶斯分类器来进行分类。
这里我们使用爬虫技术,爬取了5000条新闻数据,涵盖:汽车、财经、科技、健康、体育、教育、文化、军事、娱乐、时尚十个类别。每个类别500条新闻样本。
2.模型构建与训练
- 加载数据集
- 预处理数据
- 分割数据集
- 特征提取
- 训练模型
- 验证模型
3.代码实现
项目结构图如下:
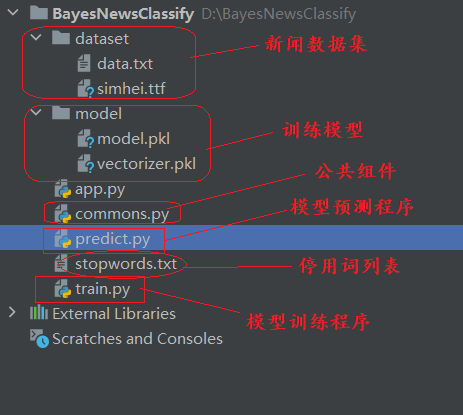
commons.py
import pandas as pd
import jieba
# 读取数据
df_news = pd.read_table('./dataset/data.txt', names=['category', 'theme', 'URL', 'content'], encoding='utf-8')
df_news = df_news.dropna()
# 停用词处理
stopwords = pd.read_csv(r"./stopwords.txt", index_col=False, sep="\t", quoting=3, names=['stopword'], encoding='utf-8')
stopwords_list = stopwords.stopword.values.tolist()
def preprocess(text, stopwords):
words = jieba.lcut(text)
words_clean = [word for word in words if word not in stopwords]
return ' '.join(words_clean)
train.py
import pandas as pd
import jieba
from sklearn.model_selection import train_test_split, cross_val_score, cross_validate
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score, make_scorer
import joblib
import matplotlib.pyplot as plt
from commons import preprocess,stopwords,stopwords_list,df_news
# 分词
content = df_news.content.values.tolist()
content_S = []
for line in content:
current_segment = jieba.lcut(line)
if len(current_segment) > 1 and current_segment != '\r\n':
content_S.append(current_segment)
# 分词并去除停用词
def drop_stopwords(contents, stopwords):
contents_clean = []
for line in contents:
line_clean = [word for word in line if word not in stopwords]
contents_clean.append(line_clean)
return contents_clean
contents_clean = drop_stopwords(content_S, stopwords_list)
# 创建并训练分类器
classifier = MultinomialNB()
# 准备训练数据
df_train = pd.DataFrame({'contents_clean': contents_clean, 'label': df_news['category']})
label_mapping = {"汽车": 1, "财经": 2, "科技": 3, "健康": 4, "体育": 5, "教育": 6, "文化": 7, "军事": 8, "娱乐": 9,
"时尚": 0}
df_train['label'] = df_train['label'].map(label_mapping)
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(df_train['contents_clean'].values, df_train['label'].values,
random_state=1)
#训练模型
def train_model():
# 将词列表转换为字符串
x_train_str = [' '.join(doc) for doc in x_train]
x_test_str = [' '.join(doc) for doc in x_test]
# 创建 CountVectorizer 对象
vec = CountVectorizer(analyzer='word', max_features=4000, lowercase=False)
# 用训练数据拟合词汇表
vec.fit(x_train_str)
# 转换训练数据和测试数据
x_train_vec = vec.transform(x_train_str)
x_test_vec = vec.transform(x_test_str)
# 创建并训练分类器
classifier = MultinomialNB()
classifier.fit(x_train_vec, y_train) # 确保在这里训练模型
# 保存模型和特征提取器
joblib.dump(classifier, './model/model.pkl')
joblib.dump(vec, './model/vectorizer.pkl')
# 预测测试集
y_pred = classifier.predict(x_test_vec)
# 评估分类器
print("Accuracy on Test Set:", accuracy_score(y_test, y_pred))
print("Classification Report:\n", classification_report(y_test, y_pred))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
# 使用交叉验证计算准确率和损失
scoring = {'accuracy': 'accuracy', 'loss': make_scorer(lambda y_true, y_pred: -accuracy_score(y_true, y_pred))}
cv_results = cross_validate(classifier, x_train_vec, y_train, cv=5, scoring=scoring, return_train_score=True)
# 训练指标展示
train_accuracy = cv_results['train_accuracy']
train_loss = -cv_results['train_loss']
test_accuracy = cv_results['test_accuracy']
test_loss = -cv_results['test_loss']
# 创建一个表格来展示性能指标
performance_metrics = pd.DataFrame({
'Fold': range(1, 6),
'Train Accuracy': train_accuracy,
'Train Loss': train_loss,
'Test Accuracy': test_accuracy,
'Test Loss': test_loss
})
print("Performance Metrics:")
print(performance_metrics)
# 绘制准确率和损失的折线图
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(range(1, 6), train_accuracy, label='Train Accuracy', marker='o')
plt.plot(range(1, 6), test_accuracy, label='Test Accuracy', marker='o')
plt.xlabel('Fold')
plt.ylabel('Accuracy')
plt.title('Accuracy on Training and Test Sets')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(range(1, 6), train_loss, label='Train Loss', marker='o')
plt.plot(range(1, 6), test_loss, label='Test Loss', marker='o')
plt.xlabel('Fold')
plt.ylabel('Loss')
plt.title('Loss on Training and Test Sets')
plt.legend()
plt.tight_layout()
plt.show()
if __name__ == '__main__':
train_model()
predict.py
import joblib
from commons import preprocess,stopwords,stopwords_list
# 预测函数
def predict_news_category(text, classifier, vec, stopwords):
# 预处理文本
text_clean = preprocess(text, stopwords)
# 转换为特征向量
text_vec = vec.transform([text_clean])
# 预测类别
category = classifier.predict(text_vec)[0]
# 将类别编号转换为类别名称
category_mapping = {1: "汽车", 2: "财经", 3: "科技", 4: "健康", 5: "体育", 6: "教育", 7: "文化", 8: "军事", 9: "娱乐", 0: "时尚"}
return category_mapping[category]
if __name__ == '__main__':
# 加载模型和特征提取器
classifier = joblib.load('./model/model.pkl')
vec = joblib.load('./model/vectorizer.pkl')
# 用户交互界面
print("请输入需要分类的新闻文本:")
user_input = input()
# 将用户输入的值赋给 news_text 变量
news_text = user_input
# 进行预测
predicted_category = predict_news_category(news_text, classifier, vec, stopwords_list)
print(f"预测的新闻类别是:{predicted_category}")
app.py
import joblib
from commons import preprocess, stopwords, stopwords_list
import gradio as gr
from predict import predict_news_category
def predict_news(news_text):
# 加载模型和特征提取器
classifier = joblib.load('./model/model.pkl')
vec = joblib.load('./model/vectorizer.pkl')
# 进行预测
predicted_category = predict_news_category(news_text, classifier, vec, stopwords_list)
return f"预测的新闻类别是:{predicted_category}"
demo = gr.Interface(
fn=predict_news,
title='机器学习-朴素贝叶斯新闻分类案例',
inputs=[gr.Text(label='源新闻文本')],
outputs=[gr.Text(label='预测结果')]
)
if __name__ == "__main__":
demo.launch()
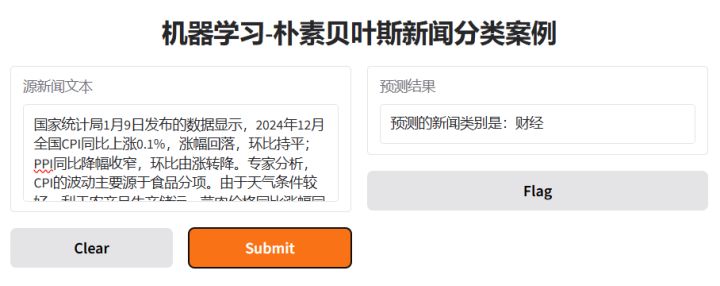
运行效果:
3. 小结
朴素贝叶斯分类器在文本分类任务中表现得非常好,尤其是在像新闻组数据集这样具有多个类别的分类任务中。通过使用scikit-learn的管道功能,我们可以轻松地组合特征提取和模型训练,大大简化了工作流程。