机器学习之利用线性回归模型来预测California的房价
机器学习之利用线性回归模型来预测California的房价
1.数据集简介
加利福尼亚房价数据集是由美国人口普查局(U.S. Census Bureau)提供的数据,它包含了1990年时加利福尼亚州的10个区域(即块)数据。这些区域的特征反映了该地区的地理和人口统计信息,如房屋的规模、收入水平等。
数据集的结构:数据集包含了 20,640 个样本(即区域的数量),每个样本具有 8 个特征,以及 1 个目标变量(即房价中位数)。
数据特征具体含义; - MedInc:区域内家庭收入的中位数(单位:10,000美元)。 - HouseAge:房屋的中位数年龄(单位:年)。 - AveRooms:每个住宅单元的平均房间数。 - AveBedrms:每个住宅单元的平均卧室数。 - Population:区域内的总人口数量。 - AveOccup:每个住宅单元的平均住户人数。 - Latitude:区域的纬度(地理坐标)。 - Longitude:区域的经度(地理坐标)。 - MedHouseVal:目标变量,区域内房价的中位数(单位:10,000美元),这是我们想要预测的目标。
2.代码实现
项目结构图如下:
下载数据集。放到项目的dataset目录里。 通过百度网盘分享的文件:cal_housing.tgz 链接:https://pan.baidu.com/s/1W_lyHP4ohbIUS-wv7wwCAw?pwd=1111 提取码:1111
程序实现:
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号显示问题
plt.rcParams['axes.unicode_minus'] = False
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
import joblib
import tarfile
import os
# ------------------------- 数据加载函数 -------------------------
def load_data():
"""
加载加利福尼亚房屋数据集并转换为DataFrame格式。
"""
#california_housing = fetch_california_housing()
archive_path = os.path.join(os.path.dirname(__file__), './dataset/cal_housing.tgz')
with tarfile.open(mode="r:gz", name=archive_path) as f:
cal_housing = np.loadtxt(
f.extractfile("CaliforniaHousing/cal_housing.data"), delimiter=","
)
# Columns are not in the same order compared to the previous
# URL resource on lib.stat.cmu.edu
columns_index = [8, 7, 2, 3, 4, 5, 6, 1, 0]
cal_housing = cal_housing[:, columns_index]
feature_names = [
"MedInc",
"HouseAge",
"AveRooms",
"AveBedrms",
"Population",
"AveOccup",
"Latitude",
"Longitude",
]
target, data = cal_housing[:, 0], cal_housing[:, 1:]
# avg rooms = total rooms / households
data[:, 2] /= data[:, 5]
# avg bed rooms = total bed rooms / households
data[:, 3] /= data[:, 5]
# avg occupancy = population / households
data[:, 5] = data[:, 4] / data[:, 5]
# target in units of 100,000
target = target / 100000.0
df = pd.DataFrame(data, columns=feature_names)
df['PRICE'] = target # 添加目标变量(房屋价格)
return df
# ------------------------- 数据分析与可视化函数 -------------------------
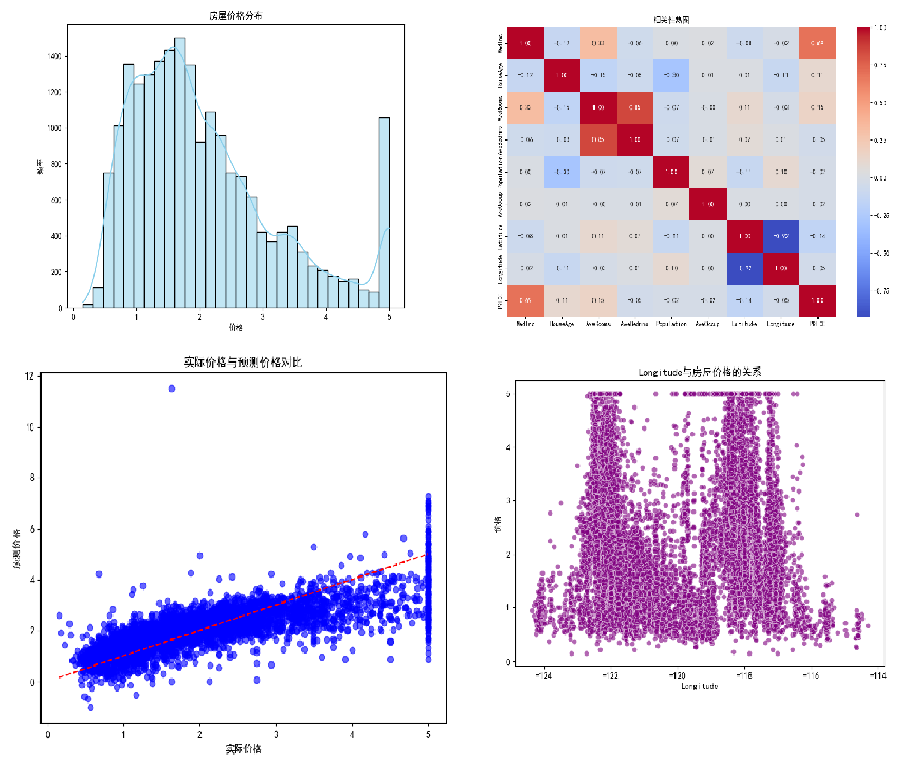
def plot_data_distribution(df):
"""
可视化目标变量(房屋价格)的分布。
"""
plt.figure(figsize=(8, 6))
sns.histplot(df['PRICE'], kde=True, bins=30, color='skyblue')
plt.title('房屋价格分布')
plt.xlabel('价格')
plt.ylabel('频率')
plt.savefig('./output/plot_data_distribution.png')
plt.show()
def plot_correlation_heatmap(df):
"""
可视化特征与目标变量之间的相关性热图。
"""
plt.figure(figsize=(12, 8))
sns.heatmap(df.corr(), annot=True, cmap='coolwarm', fmt='.2f')
plt.title('相关性热图')
plt.savefig('./output/plot_correlation_heatmap.png')
plt.show()
def plot_feature_vs_price(df):
"""
可视化每个特征与房屋价格之间的关系。
"""
for feature in df.columns[:-1]: # 排除目标变量
plt.figure(figsize=(8, 6))
sns.scatterplot(x=df[feature], y=df['PRICE'], alpha=0.6, color='purple')
plt.title(f'{feature}与房屋价格的关系')
plt.xlabel(feature)
plt.ylabel('价格')
plt.savefig('./output/plot_feature_vs_price.png')
plt.show()
# ------------------------- 数据预处理函数 -------------------------
def preprocess_data(df, polynomial_features=False):
"""
预处理数据:特征选择、标准化以及可选的多项式特征。
返回处理后的特征和目标变量。
"""
X = df.drop('PRICE', axis=1) # 特征
y = df['PRICE'] # 目标变量
# 划分数据:80% 训练,20% 测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 多项式特征
if polynomial_features:
poly = PolynomialFeatures(degree=2, include_bias=False)
X_train_scaled = poly.fit_transform(X_train_scaled)
X_test_scaled = poly.transform(X_test_scaled)
return X_train_scaled, X_test_scaled, y_train, y_test, scaler
# ------------------------- 模型训练函数 -------------------------
def train_linear_model(X_train_scaled, y_train):
"""
训练线性回归模型。
"""
model = LinearRegression()
model.fit(X_train_scaled, y_train)
return model
def train_ridge_model(X_train_scaled, y_train):
"""
训练岭回归模型,并使用GridSearchCV进行超参数调优。
"""
param_grid = {'alpha': [0.1, 1.0, 10.0, 100.0]}
ridge = Ridge()
grid_search = GridSearchCV(ridge, param_grid, cv=5, scoring='r2')
grid_search.fit(X_train_scaled, y_train)
print(f"最佳岭回归alpha值: {grid_search.best_params_['alpha']}")
return grid_search.best_estimator_
def train_lasso_model(X_train_scaled, y_train):
"""
训练套索回归模型,并使用GridSearchCV进行超参数调优。
"""
param_grid = {'alpha': [0.01, 0.1, 1.0, 10.0]}
lasso = Lasso()
grid_search = GridSearchCV(lasso, param_grid, cv=5, scoring='r2')
grid_search.fit(X_train_scaled, y_train)
print(f"最佳套索回归alpha值: {grid_search.best_params_['alpha']}")
return grid_search.best_estimator_
# ------------------------- 模型评估函数 -------------------------
def evaluate_model(model, X_test_scaled, y_test):
"""
使用均方误差、平均绝对误差和R²指标评估模型的性能。
"""
y_pred = model.predict(X_test_scaled)
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"均方误差(MSE): {mse:.2f}")
print(f"平均绝对误差(MAE): {mae:.2f}")
print(f"R²值: {r2:.2f}")
return y_pred
# ------------------------- 结果可视化函数 -------------------------
def plot_actual_vs_predicted(y_test, y_pred):
"""
可视化实际房屋价格与预测房屋价格之间的对比。
"""
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue', alpha=0.6)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--')
plt.title('实际价格与预测价格对比')
plt.xlabel('实际价格')
plt.ylabel('预测价格')
plt.savefig('./output/plot_actual_vs_predicted.png')
plt.show()
# ------------------------- 模型持久化函数 -------------------------
def save_model(model, scaler, filename='house_price_model.pkl'):
"""
保存训练好的模型和标准化器。
"""
joblib.dump({'model': model, 'scaler': scaler}, filename)
print(f"模型和标准化器已保存为 {filename}")
def load_model(filename='house_price_model.pkl'):
"""
加载保存的模型和标准化器。
"""
data = joblib.load(filename)
print(f"从 {filename} 加载模型和标准化器")
return data['model'], data['scaler']
# ------------------------- 主函数 -------------------------
def main():
# 步骤1:加载数据
df = load_data()
print("数据加载成功!\n")
# 步骤2:数据分析与可视化
plot_data_distribution(df) # 房屋价格分布
plot_correlation_heatmap(df) # 特征相关性热图
plot_feature_vs_price(df) # 特征与价格散点图
# 步骤3:数据预处理
X_train_scaled, X_test_scaled, y_train, y_test, scaler = preprocess_data(df, polynomial_features=False)
print("数据预处理完成!\n")
# 步骤4:训练模型
print("训练线性回归模型...")
linear_model = train_linear_model(X_train_scaled, y_train)
print("训练岭回归模型...")
ridge_model = train_ridge_model(X_train_scaled, y_train)
print("训练套索回归模型...")
lasso_model = train_lasso_model(X_train_scaled, y_train)
# 步骤5:评估模型
print("\n线性回归模型评估:")
linear_y_pred = evaluate_model(linear_model, X_test_scaled, y_test)
print("\n岭回归模型评估:")
ridge_y_pred = evaluate_model(ridge_model, X_test_scaled, y_test)
print("\n套索回归模型评估:")
lasso_y_pred = evaluate_model(lasso_model, X_test_scaled, y_test)
# 步骤6:结果可视化
print("\n可视化结果...")
plot_actual_vs_predicted(y_test, linear_y_pred)
# 步骤7:保存最佳模型
save_model(linear_model, scaler)
if __name__ == "__main__":
main()
运行效果:
数据加载成功!
数据预处理完成!
训练线性回归模型...
训练岭回归模型...
最佳岭回归alpha值: 0.1
训练套索回归模型...
最佳套索回归alpha值: 0.01
线性回归模型评估:
均方误差(MSE): 0.56
平均绝对误差(MAE): 0.53
R²值: 0.58
岭回归模型评估:
均方误差(MSE): 0.56
平均绝对误差(MAE): 0.53
R²值: 0.58
套索回归模型评估:
均方误差(MSE): 0.55
平均绝对误差(MAE): 0.54
R²值: 0.58
可视化结果...
模型和标准化器已保存为 house_price_model.pkl