机器学习之动物识别案例
机器学习之动物识别案例
1.下载数据集
我们在Kaggle数据集网站搜索:90 Different Animals 关键字。可以迅速找到要下载的数据集首页。
在这个数据集中,我们有90个不同类别或类别的5400张动物图像。
数据集下载百度网盘地址如下:
通过网盘分享的文件:90 Different Animals 数据集 链接: https://pan.baidu.com/s/1NGLi14U5uIJmyEv43j3yaw?pwd=9527 提取码: 9527
2.项目结构
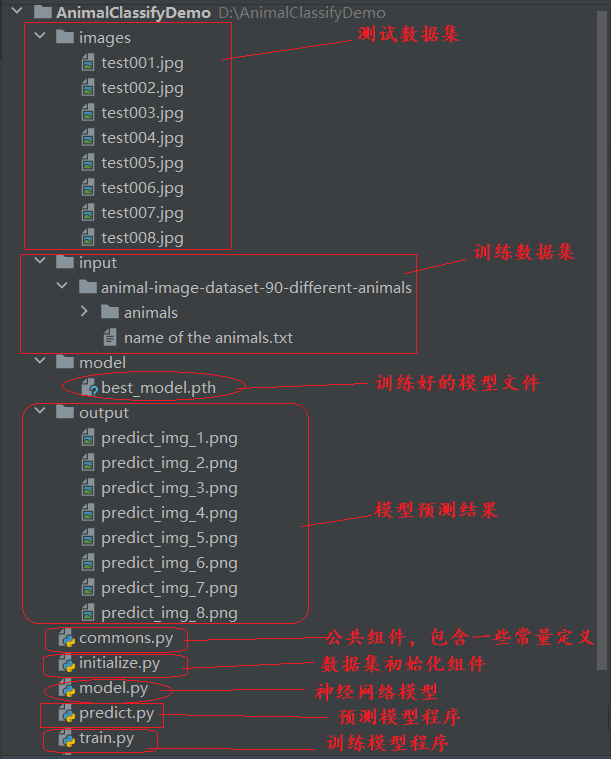
3.代码实现
创建环境。
@echo off
call conda create -n sklearn_gpu_env python==3.11.0
call conda activate sklearn_gpu_env
pip install torch-2.4.0+cu121-cp311-cp311-win_amd64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torchaudio-2.4.0+cu121-cp311-cp311-win_amd64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torchvision-0.19.0+cu121-cp311-cp311-win_amd64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install numpy==1.26.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install ipywidgets==8.1.5 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
把90 Different Animals 数据集下载好解压缩至input文件夹。分别创建images,model,output项目目录。
编写commons.py组件。
from torch._prims import le
from sklearn import preprocessing
# 定义了数据集路径的常量
path = "./input/animal-image-dataset-90-different-animals"
animal_path = path + "/animals"
# 初始化返回一个LabelEncoder解码器
def get_label_encoder():
with open(path + "/name of the animals.txt", 'r') as f:
classes = f.read().split('\n')
# View classes
num_classes = len(classes)
print(f'Number of classes: {num_classes}')
print(f'Classes of animals: {", ".join(classes)}')
le = preprocessing.LabelEncoder()
le.fit(classes)
return le
if __name__ == '__main__':
get_label_encoder()
测试运行效果:
Number of classes: 90
Classes of animals: antelope, badger, bat, bear, bee, beetle, bison, boar, butterfly, cat, caterpillar, chimpanzee, cockroach, cow, coyote, crab, crow, deer, dog, dolphin, donkey, dragonfly, duck, eagle, elephant, flamingo, fly, fox, goat, goldfish, goose, gorilla, grasshopper, hamster, hare, hedgehog, hippopotamus, hornbill, horse, hummingbird, hyena, jellyfish, kangaroo, koala, ladybugs, leopard, lion, lizard, lobster, mosquito, moth, mouse, octopus, okapi, orangutan, otter, owl, ox, oyster, panda, parrot, pelecaniformes, penguin, pig, pigeon, porcupine, possum, raccoon, rat, reindeer, rhinoceros, sandpiper, seahorse, seal, shark, sheep, snake, sparrow, squid, squirrel, starfish, swan, tiger, turkey, turtle, whale, wolf, wombat, woodpecker, zebra
编写initialize.py
import numpy as np
import matplotlib.image as mpimg
from torch._prims import le
from sklearn import preprocessing
from torch.utils.data import Dataset
import torchvision.transforms as transforms
import os
from commons import path,animal_path
from commons import get_label_encoder
le = get_label_encoder()
class _Dataset(Dataset):
def __init__(self, data, transform=None):
data, label = zip(*data)
# Transform string labels into integers
label = le.transform(label)
self.x = np.array(data)
self.y = np.array(label)
self.num_samples = len(data)
self.transform = transform
# Apply transformations to the image if specified, to preprocess it before returning along with its label.
def __getitem__(self, index):
sample = self.x[index], self.y[index]
img_path = os.path.join(animal_path, le.inverse_transform([sample[1]])[0], sample[0])
img = mpimg.imread(img_path)
if self.transform:
features = self.transform(img)
return features, sample[1]
def __len__(self):
return self.num_samples
data_transforms = {
'train': transforms.Compose(
[transforms.ToPILImage(),
transforms.Resize(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(p=0.5),
transforms.GaussianBlur(3),
transforms.ColorJitter(0.5),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
def init_data():
path = "./input/animal-image-dataset-90-different-animals"
with open(path + "/name of the animals.txt", 'r') as f:
classes = f.read().split('\n')
return classes
if __name__ == '__main__':
classes = init_data()
# View classes
num_classes = len(classes)
print(f'Number of classes: {num_classes}')
print(f'Classes of animals: {", ".join(classes)}')
构建神经网络模型,model.py
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import pylab
import seaborn as sns
import torch
from sklearn.metrics import classification_report
from torch._prims import le
from torch.utils.data import Dataset
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import models
from sklearn import preprocessing
import os
import time
import copy
from tqdm.notebook import trange, tqdm
from PIL import Image
import requests
from initialize import init_data
classes = init_data()
# View classes
num_classes = len(classes)
# Initializing the NeuralNet class by inheriting from PyTorch's nn.Module to define a custom neural network.
class NeuralNet(nn.Module):
def __init__(self):
super(NeuralNet, self).__init__()
# Use pre-trained model
self.model = models.densenet161(pretrained=True)
# Freeze all layers (No training)
for param in self.parameters():
param.requires_grad = False
# Change final FC layer to num_classes output. This is trainable by default
self.model.classifier = nn.Linear(2208, num_classes)
def forward(self, x):
x = self.model(x)
return x
# Extracting image data and labels by unpacking the paired dataset into separate variables.
# Early stopping adapted from: https://debuggercafe.com/using-learning-rate-scheduler-and-early-stopping-with-pytorch/
# Slightly modified to reset counter if increasing loss is not across consecutive epochs
class EarlyStopping():
"""
Early stopping to stop the training when the loss does not improve after
certain epochs.
"""
def __init__(self, patience=5, min_delta=0):
"""
:param patience: how many epochs to wait before stopping when loss is
not improving
:param min_delta: minimum difference between new loss and old loss for
new loss to be considered as an improvement
"""
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.best_loss = None
self.early_stop = False
def __call__(self, val_loss):
if self.best_loss == None:
self.best_loss = val_loss
elif self.best_loss - val_loss > self.min_delta:
self.best_loss = val_loss
if self.counter > 0:
print(f"Early stopping counter resetting from {self.counter} to 0.")
self.counter = 0
elif self.best_loss - val_loss < self.min_delta:
self.counter += 1
print(f"Early stopping counter {self.counter} of {self.patience}")
if self.counter >= self.patience:
self.early_stop = True
开始训练模型。train.py
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import torch
from sklearn.metrics import classification_report
from torch._prims import le
from torch.utils.data import Dataset
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import os
import time
import copy
from tqdm.notebook import trange, tqdm
from model import NeuralNet
from model import EarlyStopping
from commons import path,animal_path
from commons import get_label_encoder
from initialize import _Dataset, init_data, data_transforms
le = get_label_encoder()
# Function to shuffle data (X) randomly using a specified seed for reproducibility.
def shuffle_data(X, seed):
if seed:
np.random.seed(seed)
idx = np.arange(len(X))
np.random.shuffle(idx)
return np.array(X)[idx]
# Function to split each folder of animal images into shuffled training, validation, and test sets based on a given split size.
def data_split(animal_path, split_size=0.1):
"""
Based on split size,
Each folder is split into training and test sets.
Returns:
Shuffled training, validation and test dataset
Each set is in the form of: ['id.jpg', 'string label of id']
Example: [['1234.jpg', 'antelope'], ['12312.jpg', 'iguana'] ...]
"""
X_train, X_val, X_test = [], [], []
y_train, y_val, y_test = [], [], []
# For each label
for animal in os.listdir(animal_path):
# Extract same label for training, validation, test data
label = animal
# Image path for each animal
image_list = os.listdir(animal_path + "/" + animal)
# Shuffle images (path)
shuffled_data = shuffle_data(image_list, seed=None)
# Get the train, val, test split
split_i = len(shuffled_data) - int(len(shuffled_data) // (1 / (split_size * 2)))
split_j = len(shuffled_data) - int(len(shuffled_data) // (1 / split_size))
# Get training data from train_val_data split[:split_j]
train_data = shuffled_data[:split_i]
# Add training data, label to final training data
X_train.extend(train_data)
y_train.extend([label] * len(train_data))
# Get val data and label from train_val_data split[split_j:]
val_data = shuffled_data[split_i:split_j]
# Add val data, label to final val data
X_val.extend(val_data)
y_val.extend([label] * len(val_data))
# Get test data from shuffled_data[split_i:]
test_data = shuffled_data[split_j:]
# Add test data, label to final val data
X_test.extend(test_data)
y_test.extend([label] * len(test_data))
# Each image is presented as: ['image id.jpg', 'string label']
training_data = list(zip(X_train, y_train))
val_data = list(zip(X_val, y_val))
test_data = list(zip(X_test, y_test))
# Shuffle all data in respective sets
shuffled_training_data = shuffle_data(training_data, seed=None)
shuffled_val_data = shuffle_data(val_data, seed=None)
shuffled_test_data = shuffle_data(test_data, seed=None)
return shuffled_training_data, shuffled_val_data, shuffled_test_data
# Function to plot the first 30 images from the given dataset in a grid format using Matplotlib.
def image_plot(data, save_file):
fig = plt.figure(figsize=(20, 6))
rows = 3
columns = 10
ax = []
# See the first 30 images
for i in range(30):
image, label = data[i]
ax.append(fig.add_subplot(rows, columns, i + 1))
if torch.is_tensor(image):
image = image.permute(1, 2, 0)
ax[-1].set_title(le.inverse_transform([label])[0], fontsize=12, fontweight='bold')
else:
image_path = os.path.join(animal_path + "/" + label + "/" + image)
image = mpimg.imread(image_path)
ax[-1].set_title(label, fontsize=12, fontweight='bold')
plt.imshow(image)
plt.savefig(save_file)
plt.axis('off')
# pylab.show()
# Boilerplate code adapted: https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
def train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs, scheduler=None, early_stopping=None):
since = time.time()
training_accuracies, training_losses, val_accuracies, val_losses = [], [], [], []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch + 1, num_epochs))
print('-' * 60)
# Each epoch has a training and validation phase
for phase in ['Training', 'Validation']:
if phase == 'Training':
model.train() # Set model to training mode
dataloaders = train_loader
dataset_sizes = len(training_dataset)
else:
model.eval() # Set model to evaluate mode
dataloaders = val_loader
dataset_sizes = len(validation_dataset)
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in tqdm(dataloaders):
inputs = inputs.to(device)
labels = labels.long().to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'Training'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'Training':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'Training':
scheduler.step()
epoch_loss = running_loss / dataset_sizes
epoch_acc = running_corrects.double() / dataset_sizes
if phase == 'Training':
training_accuracies.append(epoch_acc)
training_losses.append(epoch_loss)
else:
val_accuracies.append(epoch_acc)
val_losses.append(epoch_loss)
# deep copy the model
if phase == 'Validation' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print('{} Loss after epoch: {:.4f}, Acc after epoch: {:.4f}\n'.format(
phase, epoch_loss, epoch_acc))
# Early stopping check with last average validation loss after end of epoch
if early_stopping is not None:
early_stopping(val_losses[-1])
if early_stopping.early_stop:
print('Early Stopping Initiated')
break
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
torch.save(model, "./model/best_model.pth")
return model, training_accuracies, training_losses, val_accuracies, val_losses
# Plots for accuracy and loss
def plot_history():
with plt.style.context('seaborn-v0_8'):
fig = plt.figure(figsize=(25, 10))
# Summarize history for accuracy
plt.subplot(1, 2, 1)
plt.plot([*range(len(training_accuracies))], training_accuracies)
plt.plot([*range(len(val_accuracies))], val_accuracies)
plt.title('Accuracy ', fontsize=15)
plt.ylabel('Accuracy', fontsize=15)
plt.xlabel('Epoch', fontsize=15)
# plt.ylim([0.4, 1.0])
plt.legend(['Training Accuracy', 'Validation Accuracy'], loc='upper right', fontsize=15)
# Summarize history for loss
plt.subplot(1, 2, 2)
plt.plot([*range(len(training_losses))], training_losses, label='training loss')
plt.plot([*range(len(val_losses))], val_losses, label='validation loss')
plt.title('Losses', fontsize=15)
plt.ylabel('Loss', fontsize=15)
plt.xlabel('Epoch', fontsize=15)
# plt.ylim([0.0, 1.5])
plt.legend(['Training Loss', 'Validation Loss'], loc='upper right', fontsize=15)
plt.show()
##################################################################################
# Function to visualize a set of model predictions on images from a data loader, showing the model's performance.
def visualize_model(model, data_loader, num_images=25):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure(figsize=(25, 30))
fig.canvas.draw()
rows = 5
columns = 5
MEAN = torch.tensor([0.485, 0.456, 0.406])
STD = torch.tensor([0.229, 0.224, 0.225])
with torch.no_grad():
for i, (inputs, labels) in enumerate(data_loader):
inputs = inputs.to(device)
outputs = model(inputs)
val, preds = torch.max(outputs, 1)
preds_invtrans = le.inverse_transform(preds.cpu())
labels_invtrans = le.inverse_transform(labels.cpu())
ax = []
for j in range(inputs.size()[0]):
images_so_far += 1
ax.append(plt.subplot(rows, columns, images_so_far))
# Reverse normalize
image = inputs.cpu().data[j] * STD[:, None, None] + MEAN[:, None, None]
image = image.permute(1, 2, 0)
ax[-1].set_title(f'Ground Truth: {labels_invtrans[j]}\nPredicted: {preds_invtrans[j]}', fontsize=15,
fontweight='bold')
# Draw boxes around subplots
bbox = ax[-1].get_tightbbox(fig.canvas.renderer)
x0, y0, width, height = bbox.transformed(fig.transFigure.inverted()).bounds
# slightly increase the very tight bounds:
xpad = 0.01 * width
ypad = 0.01 * height
if preds[j] == labels[j]:
fig.add_artist(
plt.Rectangle((x0 - xpad, y0 - ypad), width + 2 * xpad, height + 2 * ypad, edgecolor='green',
linewidth=5, fill=False))
else:
fig.add_artist(
plt.Rectangle((x0 - xpad, y0 - ypad), width + 2 * xpad, height + 2 * ypad, edgecolor='red',
linewidth=5, fill=False))
plt.imshow(image)
plt.axis('off')
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
if __name__ == '__main__':
classes = init_data()
# View classes
num_classes = len(classes)
# See the number of images for each class
for animal in os.listdir(animal_path):
print(f'Number of {animal} images: {len(os.listdir(animal_path + "/" + animal))}')
# Split size for training, validation, test
split_size = 0.08
print("######################################################")
train_data, val_data, test_data = data_split(animal_path, split_size=split_size)
print('Number of training images: {}'.format(len(train_data)))
print('Number of validation images: {}'.format(len(val_data)))
print('Number of testing images: {}'.format(len(test_data)))
print("########################See some of the training images before pre-processing##############################")
# See some of the training images before pre-processing
print(train_data)
image_plot(train_data, './train_data.png')
# To convert string labels into integers
le = get_label_encoder()
print(
"########################Creating training, validation, and test datasets with their respective transformations applied.#############################")
# Creating training, validation, and test datasets with their respective transformations applied.
training_dataset = _Dataset(train_data, transform=data_transforms['train'])
validation_dataset = _Dataset(val_data, transform=data_transforms['val'])
test_dataset = _Dataset(test_data, transform=data_transforms['val'])
# Visualise augmented ugly images
image_plot(training_dataset, './training_dataset.png')
BATCH_SIZE = 32
train_loader = torch.utils.data.DataLoader(dataset=training_dataset, shuffle=True, batch_size=BATCH_SIZE)
val_loader = torch.utils.data.DataLoader(dataset=validation_dataset, shuffle=False, batch_size=BATCH_SIZE)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, shuffle=False, batch_size=BATCH_SIZE)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = NeuralNet().to(device)
# Model Summary
print(model)
print("##############################star to train model##############################")
""""""
learning_rate = 0.01
num_epochs = 100
criterion = nn.CrossEntropyLoss()
# Optimizer
optimizer_ft = optim.Adam(model.parameters(), lr=learning_rate)
# Decay LR by a factor of 0.1 every 10 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=10, gamma=0.1)
# Early stopping if val_loss does not improve from the best - 1e-5 over next 5 epochs
es = EarlyStopping(patience=5, min_delta=1e-5)
model_ft, training_accuracies, training_losses, val_accuracies, val_losses = train_model(model=model,
train_loader=train_loader,
val_loader=val_loader,
criterion=criterion,
optimizer=optimizer_ft,
num_epochs=num_epochs,
scheduler=exp_lr_scheduler,
early_stopping=es)
plot_history()
# Visualise on validation dataset
model_ft = torch.load('model/best_model.pth')
visualize_model(model_ft, val_loader)
labels_list = []
preds_list = []
with torch.no_grad():
for inputs, labels in tqdm(test_loader):
inputs = inputs.to(device)
labels = labels.to(device)
labels_list.extend(label.item() for label in labels)
outputs = model_ft(inputs)
predictions = torch.argmax(outputs, dim=1)
preds_list.extend(prediction.item() for prediction in predictions)
count = 0
for i in range(len(preds_list)):
if preds_list[i] == labels_list[i]:
count += 1
accuracy = count / len(preds_list)
print(f'Test accuracy = {accuracy:.4f}')
# Visualise predictions on test dataset
visualize_model(model_ft, test_loader)
report = classification_report(labels_list, preds_list)
print(report)
模型训练输出效果如下:
Epoch 1/100
------------------------------------------------------------
0%| | 0/144 [00:00<?, ?it/s]
Training Loss after epoch: 2.5360, Acc after epoch: 0.5682
0%| | 0/15 [00:00<?, ?it/s]
Validation Loss after epoch: 1.0145, Acc after epoch: 0.7622
...
训练好的模型会自动保存到 model/best_model.pth 文件里。
开始模型预测。predict.py
import matplotlib.pyplot as plt
import torch
from torch._prims import le
import torchvision.transforms as transforms
from PIL import Image
from sklearn import preprocessing
from initialize import init_data
classes = init_data()
# View classes
num_classes = len(classes)
# To convert string labels into integers
le = preprocessing.LabelEncoder()
le.fit(classes)
def predict(model, url,counter_index):
filename = 'predict_img_'+ str(counter_index)
tfms = transforms.Compose([
transforms.Resize(256),
transforms.RandomCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
plt.figure(figsize=(5, 5))
image = Image.open(url)
img_tensor = tfms(image).to('cuda').unsqueeze(0)
output = model(img_tensor)
prediction = torch.argmax(output, dim=1)
prediction = le.inverse_transform(prediction.cpu())
plt.imshow(image)
plt.title(f'Prediction: {prediction[0]}', fontsize="15")
plt.savefig('./output/'+filename+'.png')
plt.axis('off')
if __name__ == '__main__':
model_ft = torch.load('./model/best_model.pth')
# Insert image address for single image prediction
url_list = [
"./images/test001.jpg",
"./images/test002.jpg",
"./images/test003.jpg",
"./images/test004.jpg",
"./images/test005.jpg",
"./images/test006.jpg",
"./images/test007.jpg",
"./images/test008.jpg"
]
counter_index=0
for url in url_list:
counter_index = counter_index+1
predict(model_ft, url, counter_index)
模型预测效果:

注意:如果使用cpu环境测试模型预测效果,代码修改如下:
main入口:
model_ft = torch.load('./model/best_model.pth', map_location=torch.device('cpu'))
predict方法:
img_tensor = tfms(image).to('cpu').unsqueeze(0)