KNN算法几乎是机器学习里最简单的算法了,简单到根本不需要训练直接拿来就可以使用的一种算法。KNN的核心思想是通过比较新数据点与已知类别训练集中数据点的距离,找出最近K个邻居,并根据多数类别决定新数据点的类别。KNN广泛应用于推荐系统、金融市场分析、市场细分等领域。在Python中,可使用scikit-learn库实现KNN算法,并通过数据预处理、参数调整等优化策略提高预测性能。
1.KNN算法核心思想
KNN 的核心思想非常直观:“一个样本的类别(或数值)取决于其最邻近的K个邻居的类别(或数值)。”
KNN算法是一种非参数、基于距离的分类方法,无需构建显式模型,而是直接依赖于训练数据进行预测。其主要工作流程如下:
- 确定K值:K是一个预先设定的正整数,表示在训练集中选取与待分类点最近的邻居数量。K值的选择对最终预测结果有显著影响,需根据具体问题和数据特性进行合理选择。
- 距离计算:计算待分类点与训练集中每一个点之间的距离。常用的距离度量包括欧氏距离、曼哈顿距离、切比雪夫距离、马氏距离等。这些距离函数旨在量化不同维度特征间差异的程度。
- 寻找最近的K个邻居:根据计算得到的距离,按由近及远排序,选择与待分类点距离最近的K个训练数据点作为其邻居。
- 类别决策:统计这K个邻居中各个类别的出现频率,将待分类点归为出现频率最高的类别。这种决策规则被称为“多数表决”或“硬投票”。此外,还可以采用加权投票的方式,赋予距离更近的邻居更大的权重。
好了,我想现在你应该对KNN算法有了基本的认识了。不过有几个问题还得明确一下:
- K值如何确定?
- 如何度量距离?
先来说说如何确定K值。对于K值,从KNN算法的名称中,我们可以看出K值得重要性是毋庸置疑的。我们用下图的例子来说一说K值得样本分类的重要性:
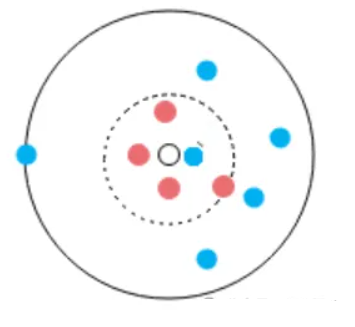
图中所有圆点构成一个数据集,圆点颜色代表分类,那么,图中无色圆点划分到哪个类呢?
- 当K=1时,离透明点最近的点是蓝点,那么我们应该将透明圆点划分到蓝点所在类别中;
- 当K=5时,离透明点最近的5个点中有4个红点,1个蓝点,那么我们应该将透明圆点划分到红点所属的类别中;
- 当K=10时,离透明点最近的10个点中有4个红点,6个蓝点,那么我们应该将透明圆点划分到蓝点所属的类别中。
你看,最终的结果因K值而异,K值过大过小都会对数据的分类产生不同程度的影响。对于K值的确定,目前并没有专门的理论方案,一个较普遍的做法就是将数据集分为两部分,一部分用作训练集,一部分用作测试集,从K取一个较小值开始,逐步增加K值,最终去准确率最高的一个K值。通常把这种方法称为遍历搜索结合交叉验证。
我们以莺尾花案例为例子,看看如何选择最佳的K值。
from sklearn import datasets
from sklearn import neighbors
from sklearn.model_selection import cross_val_score
# 获取鸢尾花数据集
iris = datasets.load_iris()
for k in range(3, 16, 2):
# K近邻算法
knn = neighbors.KNeighborsClassifier(n_neighbors=k)
# 5折交叉验证
scores = cross_val_score(knn, iris.data, iris.target, cv=5)
print(f'K = {k}: the mean accuracy is {100 * scores.mean():.2f}%.')
运行结果:
K = 3: the mean accuracy is 96.67%.
K = 5: the mean accuracy is 97.33%.
K = 7: the mean accuracy is 98.00%.
K = 9: the mean accuracy is 97.33%.
K = 11: the mean accuracy is 98.00%.
K = 13: the mean accuracy is 97.33%.
K = 15: the mean accuracy is 96.67%.
我们发现K取7和11获得了最佳的准确率。因此我们可以尝试取K=7或者K=11。
总结一下,一般而言K取奇数并且要大于样本的维度,K既不能太小也不能过大,通常采用遍历搜索结合交叉验证方式寻找最佳K值。
关于距离度量,我们最熟悉的、使用最广泛的就是欧式距离了。对于维数据点和之间的欧氏距离定义为:
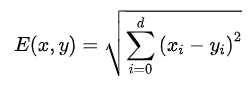
除了欧氏距离外,距离度量方法还有余弦距离、哈曼顿距离、切比雪夫距离等,但使用不多,不介绍了。
2.KNN算法对样本的要求与优缺点分析
KNN算法要求样本的数量必须大于样本的维度,样本的范围越大越好,否则范围之外的点的预测值太单一。样本之间的分布越均匀越好,样本各个维度的数值以及样本的目标值的精度越高越好(既样本质量越高越好)。
KNN的主要优点有: - 理论成熟,思想简单,既可以用来做分类也可以用来做回归。 - 可用于非线性分类,和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感。 - 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。 - 该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
KNN的主要缺点有: - 计算量大,尤其是特征数非常多的时候。 - 样本不平衡的时候,对稀有类别的预测准确率低。 - 使用懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢。 - 相比决策树模型,KNN模型可解释性不强。
3.KNN算法Python实现
from numpy import *
import operator
# 给出训练数据以及类别
def createDataSet():
group = array([[1.0, 1.1],
[1.0, 1.0],
[0, 0],
[0, 0.1]])
labels = ["A", "A", "B", "B"]
return group, labels
# 通过KNN进行分类
def classify0(inX, dataSet, labels, k):
# 获取数据集的行数
dataSetSize = dataSet.shape[0]
# 计算欧氏距离
# 将 inX 扩展到 dataSize 行
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
# 选取最小的 k 个点
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# 将 classCount 字典分解成元组,并按照第二个元素的次序对元组进行排序,此处的排序为逆序
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
if __name__ == '__main__':
group, labels = createDataSet()
inX = [0, 0]
classLabel = classify0(inX, group, labels, 3)
print("class is :",classLabel)
运行结果:
class is : B