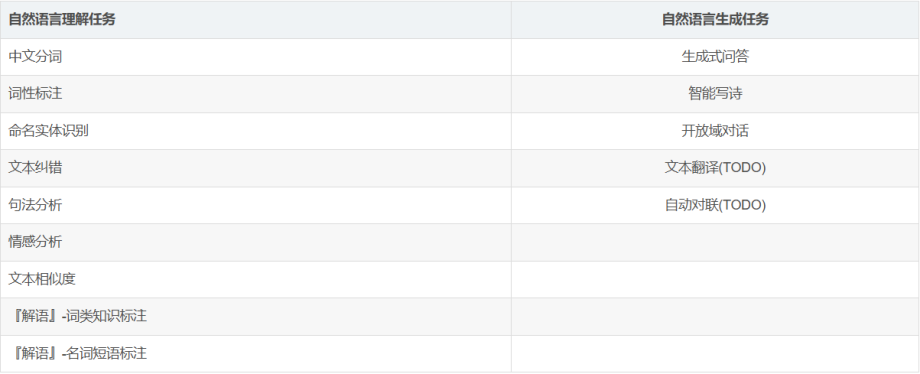
百度飞浆大模型的paddlenlp.Taskflow提供开箱即用的NLP预置任务,覆盖自然语言理解与自然语言生成两大核心应用,在中文场景上提供产业级的效果与极致的预测性能。
1.任务清单
环境安装:
#1.创建虚拟环境
conda create -n nlptask_env python==3.10.0
#2.安装PaddlePaddle 2.4.2
conda activate nlptask_env
pip install paddlepaddle==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
#pip install paddlepaddle-gpu==2.4.2 -i https://pypi.org/simple
#3.安装 paddlespeech 的 conda 依赖。
conda install -y -c conda-forge sox libsndfile swig bzip2
#4.安装pytest-runner。
pip install pytest-runner -i https://pypi.tuna.tsinghua.edu.cn/simple
#5.安装PaddleSpeech。
pip install paddlespeech==1.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
#6.安装paddlenlp 2.5.2
pip install paddlenlp==2.5.2
#7.解决一些兼容性问题。肯定是放到最后
pip install protobuf==3.20
2.案例详解
2.1 中文分词
支持三种模式分词: - Base模式(默认) - 快速模式 - 精确模式
Base模式(默认)
from paddlenlp import Taskflow
if __name__ == '__main__':
seg = Taskflow("word_segmentation")
result = seg("第十四届全运会在西安举办。")
print(result)
运行结果:
['第十四届', '全运会', '在', '西安', '举办']
快速模式,利用『结巴』中文分词工具,实现文本快速切分。
from paddlenlp import Taskflow
if __name__ == '__main__':
#seg = Taskflow("word_segmentation")
seg = Taskflow("word_segmentation",model="fast")
result = seg("第十四届全运会在西安举办。")
print(result)
运行结果:
['第十四届', '全运会', '在', '西安', '举办', '。']
精确模式,试图将句子中的实体词完整切分,分词精确度高。
from paddlenlp import Taskflow
if __name__ == '__main__':
#seg = Taskflow("word_segmentation")
seg = Taskflow("word_segmentation",model="accurate")
result = seg("李伟拿出具有科学性、可操作性的《陕西省高校管理体制改革实施方案》")
print(result)
运行结果:
['李伟', '拿出', '具有', '科学性', '、', '可', '操作性', '的', '《', '陕西省', '高校', '管理', '体制改革', '实施', '方案', '》']
自定义词典,用户可以在词典文件每一行有两个部分:词语、词频(可省略),用空格隔开。词频省略则自动计算能保证分出该词的词频。
词典文件user_dict.txt示例:
黑神话:悟空
黑神话
悟空
from paddlenlp import Taskflow
if __name__ == '__main__':
#seg = Taskflow("word_segmentation")
seg = Taskflow("word_segmentation",model="fast", user_dict="user_dict.txt")
result = seg("《黑神话:悟空》是由杭州游科互动科技有限公司开发,浙江出版集团数字传媒有限公司出版的西游题材单机动作角色扮演游戏。")
print(result)
运行结果:
['《', '黑神话:悟空', '》', '是', '由', '杭州游科互动科技有限公司', '开发', ',', '浙江出版集团数字传媒有限公司', '出版', '的', '西游', '题材', '单机', '动作', '角色', '扮演', '游戏', '。']
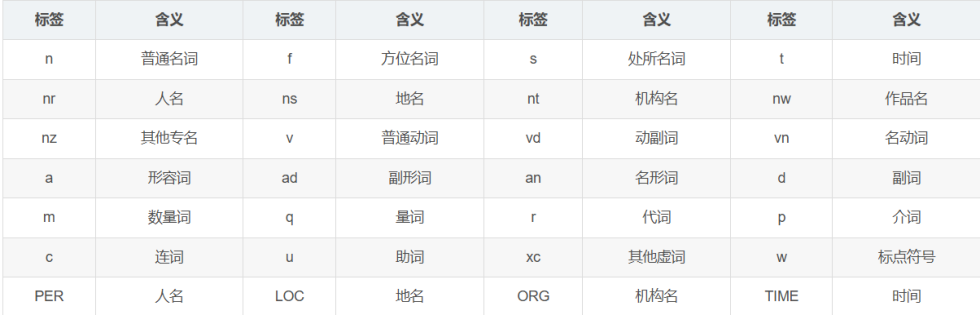
2.2 词性标注
标签集合:
from paddlenlp import Taskflow
if __name__ == '__main__':
tag = Taskflow("pos_tagging")
result = tag("第十四届全运会在西安举办。")
print(result)
运行结果:
[('第十四届', 'm'), ('全运会', 'nz'), ('在', 'p'), ('西安', 'LOC'), ('举办', 'v'), ('。', 'w')]
自定义词典,用户可以通过装载自定义词典来定制化分词和词性标注结果。词典文件每一行表示一个自定义item,可以由一个单词或者多个单词组成,单词后面可以添加自定义标签,格式为item/tag,如果不添加自定义标签,则使用模型默认标签。
词典文件user_dict.txt示例:
赛里木湖/LAKE
高/a 山/n
海拔最高
湖 泊
以"赛里木湖是新疆海拔最高的高山湖泊"为例,原本的输出结果为:
[('赛里木湖', 'LOC'), ('是', 'v'), ('新疆', 'LOC'), ('海拔', 'n'), ('最高', 'a'), ('的', 'u'), ('高山', 'n'), ('湖泊', 'n'), ('。', 'w')]
装载自定义词典及输出结果示例:
from paddlenlp import Taskflow
if __name__ == '__main__':
tag = Taskflow("pos_tagging",user_dict="./user_dict.txt")
result = tag("赛里木湖是新疆海拔最高的高山湖泊。")
print(result)
输出结果:
[('赛里木湖', 'LAKE'), ('是', 'v'), ('新疆', 'LOC'), ('海拔最高', 'n'), ('的', 'u'), ('高', 'a'), ('山', 'n'), ('湖', 'n'), ('泊', 'n'), ('。', 'w')]
2.3 命名实体识别
支持两种模式: - 快速模式 - 精确模式(默认)
快速模式
from paddlenlp import Taskflow
if __name__ == '__main__':
ner = Taskflow("ner", mode="fast")
result = ner("阿里巴巴的创始人是马云。")
print(result)
运行结果:
[('阿里巴巴', 'ORG'), ('的', 'u'), ('创始人', 'n'), ('是', 'v'), ('马云', 'PER'), ('。', 'w')]
精准模式。
from paddlenlp import Taskflow
if __name__ == '__main__':
ner = Taskflow("ner", mode="accurate")
result = ner("阿里巴巴的创始人是马云。")
print(result)
运行结果:
[('阿里巴巴', '品牌名'), ('的', '助词'), ('创始人', '人物类_概念'), ('是', '肯定词'), ('马云', '人物类_实体'), ('。', 'w')]
2.4 文本纠错
from paddlenlp import Taskflow
if __name__ == '__main__':
corrector = Taskflow("text_correction")
result = corrector('遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。')
print(result)
运行结果:
[{'source': '遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。', 'target': '遇到逆境时,我们必须勇于面对,而且要愈挫愈勇,这样我们才能朝著成功之路前进。', 'errors': [{'position': 3, 'correction': {'竟': '境'}}]}]
2.5 句法分析
首先更新LAC。
pip install LAC --upgrade
from paddlenlp import Taskflow
if __name__ == '__main__':
ddp = Taskflow("dependency_parsing")
result = ddp("9月9日上午纳达尔在亚瑟·阿什球场击败俄罗斯球员梅德韦杰夫。")
print(result)
运行结果: 输出概率值和词性标签。
[{'word': ['9月9日', '上午', '纳达尔', '在', '亚瑟·阿什', '球场', '击败', '俄罗斯', '球员', '梅德韦杰夫', '。'], 'head': [2, 7, 7, 6, 6, 7, 0, 9, 10, 7, 7], 'deprel': ['ATT', 'ADV', 'SBV', 'MT', 'ATT', 'ADV', 'HED', 'ATT', 'ATT', 'VOB', 'MT']}]
使用ddparser-ernie-1.0进行预测:
from paddlenlp import Taskflow
if __name__ == '__main__':
ddp = Taskflow("dependency_parsing",model="ddparser-ernie-1.0")
result = ddp("9月9日上午纳达尔在亚瑟·阿什球场击败俄罗斯球员梅德韦杰夫。")
print(result)
运行结果:
[{'word': ['9月9日', '上午', '纳达尔', '在', '亚瑟·阿什', '球场', '击败', '俄罗斯', '球员', '梅德韦杰夫', '。'], 'head': [2, 7, 7, 6, 6, 7, 0, 9, 10, 7, 7], 'deprel': ['ATT', 'ADV', 'SBV', 'MT', 'ATT', 'ADV', 'HED', 'ATT', 'ATT', 'VOB', 'MT']}]
依存关系可视化:
from paddlenlp import Taskflow
import cv2
if __name__ == '__main__':
ddp = Taskflow("dependency_parsing", return_visual=True)
result = ddp("9月9日上午纳达尔在亚瑟·阿什球场击败俄罗斯球员梅德韦杰夫。")[0]['visual']
cv2.imwrite('test.png', result)
输出结果:
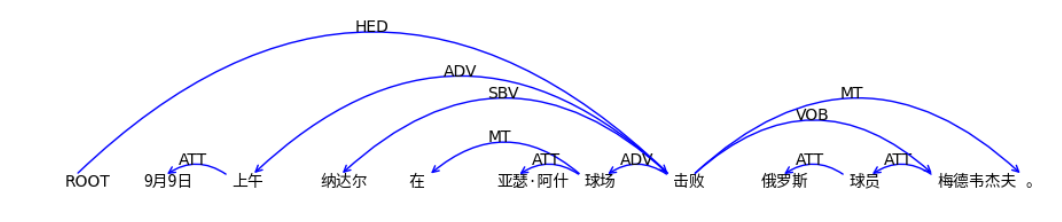
标注关系说明:
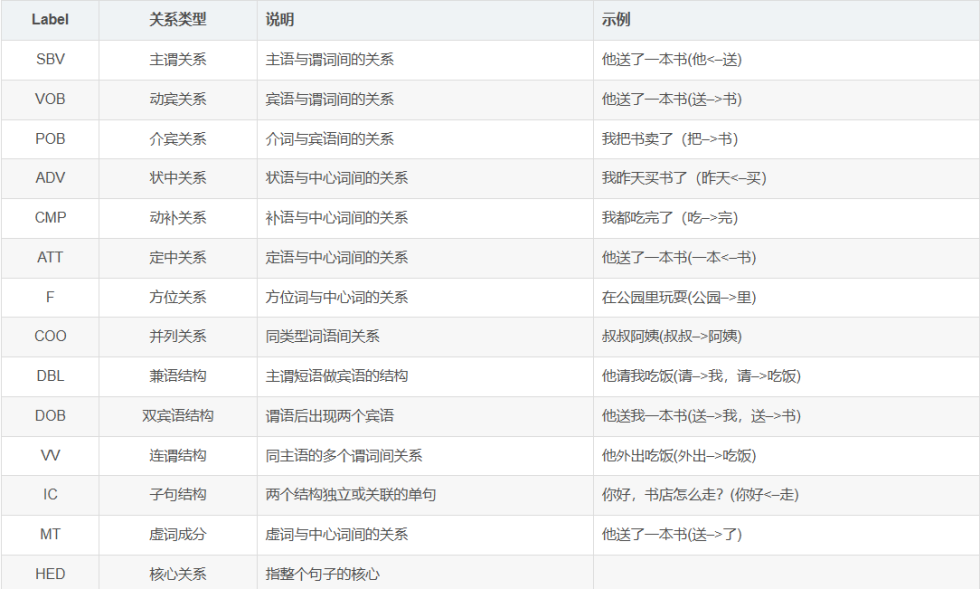
2.6 情感分析
使用BiLSTM模型:
from paddlenlp import Taskflow
if __name__ == '__main__':
senta = Taskflow("sentiment_analysis")
result = senta("这个产品用起来真的很流畅,我非常喜欢。")
print(result)
运行结果:
[{'text': '这个产品用起来真的很流畅,我非常喜欢', 'label': 'positive', 'score': 0.9938690066337585}]
使用SKEP情感分析预训练模型进行预测:
from paddlenlp import Taskflow
if __name__ == '__main__':
senta = Taskflow("sentiment_analysis",model="skep_ernie_1.0_large_ch")
result = senta("作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。")
print(result)
运行结果:
[{'text': '作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。', 'label': 'positive', 'score': 0.984320878982544}]
2.7 文本相似度
from paddlenlp import Taskflow
if __name__ == '__main__':
# 示例句子
sentence1 = "阿里巴巴的总部在杭州,它的创始人是马云。"
sentence2 = "阿里巴巴的创始人是马云,它的总部在杭州。"
similarity = Taskflow("text_similarity")
result = similarity([[sentence1, sentence2]])
print(result)
运行结果:
[{'text1': '阿里巴巴的总部在杭州,它的创始人是马云。', 'text2': '阿里巴巴的创始人是马云,它的总部在杭州。', 'similarity': 0.9977601766586304}]
2.8 知识挖掘-词类知识标注
from paddlenlp import Taskflow
if __name__ == '__main__':
wordtag = Taskflow("knowledge_mining")
result = wordtag("《笑傲江湖》是中国现代作家金庸创作的一部长篇武侠小说,1967年开始创作并连载于《明报》。")
print(result)
运行结果:
[{'text': '笑傲江湖》是中国现代作家金庸创作的一部长篇武侠小说,1967年开始创作并连载于《明报》。', 'items': [{'item': '笑傲江湖', 'offset': 0, 'wordtag_label': '作品类_实体', 'length': 4, 'termid': '作品与出版物_eb_笑傲江湖'}, {'item': '》', 'offset': 4, 'wordtag_label': 'w', 'length': 1}, {'item': '是', 'offset': 5, 'wordtag_label': '肯定词', 'length': 1, 'termid': '肯定否定词_cb_是'}, {'item': '中国', 'offset': 6, 'wordtag_label': '世界地区类_国家', 'length': 2}, {'item': '现代', 'offset': 8, 'wordtag_label': '时间类', 'length': 2, 'termid': '时间阶段_cb_现代'}, {'item': '作家', 'offset': 10, 'wordtag_label': '人物类_概念', 'length': 2, 'termid': '人物_cb_作家'}, {'item': '金庸', 'offset': 12, 'wordtag_label': '人物类_实体', 'length': 2, 'termid': '人物_eb_金庸'}, {'item': '创作', 'offset': 14, 'wordtag_label': '场景事件', 'length': 2, 'termid': '场景事件_cb_创作'}, {'item': '的', 'offset': 16, 'wordtag_label': '助词', 'length': 1, 'termid': '助词_cb_的'}, {'item': '一部', 'offset': 17, 'wordtag_label': '数量词_单位数量词', 'length': 2}, {'item': '长篇武侠小说', 'offset': 19, 'wordtag_label': '作品类_概念', 'length': 6, 'termid': '小说_cb_长篇武侠小说'}, {'item': ',', 'offset': 25, 'wordtag_label': 'w', 'length': 1}, {'item': '1967年', 'offset': 26, 'wordtag_label': '时间类_具体时间', 'length': 5}, {'item': '开始', 'offset': 31, 'wordtag_label': '场景事件', 'length': 2, 'termid': '场景事件_cb_开始'}, {'item': '创作', 'offset': 33, 'wordtag_label': '场景事件', 'length': 2, 'termid': '场景事件_cb_创作'}, {'item': '并', 'offset': 35, 'wordtag_label': '连词', 'length': 1, 'termid': '连词_cb_并'}, {'item': '连载', 'offset': 36, 'wordtag_label': '场景事件', 'length': 2, 'termid': '场景事件_cb_连载'}, {'item': '于', 'offset': 38, 'wordtag_label': '介词', 'length': 1, 'termid': '介词_cb_于'}, {'item': '《', 'offset': 39, 'wordtag_label': 'w', 'length': 1}, {'item': '明报', 'offset': 40, 'wordtag_label': '作品类_实体', 'length': 2}, {'item': '》', 'offset': 42, 'wordtag_label': 'w', 'length': 1}, {'item': '。', 'offset': 43, 'wordtag_label': 'w', 'length': 1}]}]
2.9 知识挖掘-名词短语标注
from paddlenlp import Taskflow
if __name__ == '__main__':
nptag = Taskflow("knowledge_mining", model="nptag",linking=True)
result = nptag(["宫保鸡丁","阿奇霉素"])
print(result)
运行结果:
[{'text': '宫保鸡丁', 'label': '菜品', 'category': '饮食类_菜品'}, {'text': '阿奇霉素', 'label': '抗生素', 'category': '药物类'}]
2.10 生成式问答
from paddlenlp import Taskflow
if __name__ == '__main__':
qa = Taskflow("question_answering")
result = qa("中国的国土面积有多大?")
print(result)
运行结果:
[{'text': '中国的国土面积有多大?', 'answer': '960万平方公里。'}]
2.11 智能写诗
from paddlenlp import Taskflow
if __name__ == '__main__':
poetry = Taskflow("poetry_generation")
result = poetry("林密不见人")
print(result)
运行结果:
[{'text': '林密不见人', 'answer': ',但闻人语响。'}]
2.12 开放域对话
支持两种模式: - 非交互模式 - 交互模式
非交互模式。
from paddlenlp import Taskflow
if __name__ == '__main__':
dialogue = Taskflow("dialogue")
result = dialogue(["吃饭了吗?"])
print(result)
运行结果:
['吃过了,你在干吗呢?']
交互模式。
from paddlenlp import Taskflow
if __name__ == '__main__':
dialogue = Taskflow("dialogue")
# 输入`exit`可退出交互模式
dialogue.interactive_mode(max_turn=3)
运行结果:
[Human]:你好
[Bot]:你好,在干什么呢?
[Human]:我在写程序呢。
[Bot]:你是程序员?
[Human]:是啊,你呢?
[Bot]:我是会计,不过我不喜欢写代码。
3.Taskflow如何修改任务保存路径
Taskflow默认会将任务相关模型等文件保存到$HOME/.paddlenlp下,可以在任务初始化的时候通过home_path自定义修改保存路径。
示例:
from paddlenlp import Taskflow
ner = Taskflow("ner", home_path="/workspace")
通过以上方式即可将ner任务相关文件保存至/workspace路径下。